Shallow Thoughts : tags : mozilla
Akkana's Musings on Open Source Computing and Technology, Science, and Nature.
Sat, 20 Jul 2013
Sometimes when I middleclick on a Firefox link to open it in a new tab,
I get an empty new tab. I hate that.
It happens most often on Javascript links. For instance, suppose a
website offers a Help link next to the link I'm trying to use.
I don't know what type of link it is; if it's
a normal link, to an HTML page, then it may open in my current tab,
overwriting the form I just spent five minutes filling out.
So I want to middleclick it, so it will open in a new tab.
On the other hand, if it's a Javascript link that pops up a new
help window, middleclicking won't work at all; all it does is open
an empty new tab, which I'll have to close.
A similar effect happens on PDF links; in that case, middleclicking
gives me the "What do you want to do with this?" dialog but
I also get a new tab that I have to close. (Though I'm
not sure what happens with Firefox's new built-in PDF reader.)
Anyway, since there seems to be no way of making middleclick just
do the sensible thing and open these links in a new tab like I asked,
it, I can do something almost as good: a user stylesheet that warns me when
I'm about to click on one of these special links. This rule changes
the cursor to a crosshair, and turns the link bold with colors of red
on yellow. Hard to miss!
I put this into userContent.css, inside the chrome
directory inside my profile:
/*
* Make it really obvious when links are javascript,
* since middleclicking javascript links doesn't do anything
* except open an empty new tab that then has to be closed.
*/
a:hover[href^="javascript"] {
cursor: crosshair; font-weight: bold;
text-decoration: blink;
color: red; background-color: yellow
!important
}
/*
* And the same for PDFs, for the same reason.
* Sadly, we can't catch all PDFs, just the ones where the actual
* filename ends in .pdf.
* Apparently there's no way to make a selector case insensitive,
* so we have separate cases for .pdf and .PDFb
*/
a:hover[href$=".pdf"], a:hover[href$=".PDF"] {
cursor: crosshair;
color: red; background-color: yellow
!important
}
In selectors, ^="javascript" means "starts with javascript",
for links like javascript:do_something().
$=".pdf" means "ends with .pdf".
If you want to match a string anywhere inside the href,
*= means "contains".
What about that crosshair cursor?
Here are some of the cursors you can use:
Mozilla's
cursor documentation page. Don't trust the images on that page --
hover over each cursor to see what your actual browser shows.
You can also warn about links that would open a new window or tab.
If you prefer to keep control of that, rather than letting each web
page designer decide for you where each link should open, you
can control it with the
browser.link.open newwindow
preference. But whatever you do with that preference you can add a rule for
a:hover[target="_blank"] to help you notice links that
are likely to open in a new tab.
You can even make these special links blink, with
text-decoration: blink.
Assuming you're not a curmudgeon like I am who disables blinking
entirely by setting the "browser.blink_allowed" preference to false.
Tags: firefox, web, css, browsers, mozilla
[
20:26 Jul 20, 2013
More tech/web |
permalink to this entry |
]
Sun, 09 Jun 2013
I recently went on an upgrading spree on my main computer. In the hope
of getting more up-to-date libraries, I updated my Ubuntu to 13.04
"Raring Ringtail", and Debian to unstable "Sid". Most things went fine
-- except for Firefox.
Under both Ringtail and Sid, Firefox became extremely unstable.
I couldn't use it for more than about fifteen minutes before it would
freeze while trying to access some web resource. The only cure when
that happened was to kill it and start another Firefox.
This was happening with the exact same Firefox -- a 21.0 build from
mozilla.org -- that I was using without any problems on older versions
of Debian and Ubuntu; and with the exact same profile. So it was
clearly something that had changed about Debian and Ubuntu.
The first thing I do when I hit a Firefox bug is test with
a fresh profile. I have all sorts of Firefox customizations, extensions
and other hacks. In fact, the customizations are what keep me tied
to Firefox rather than jumping to some other browser. But they do,
too often, cause problems. I have a generic profile I keep around
for testing, so I fired it up and used it for browsing for a day.
Firefox still froze, but not as often.
Disabling Extensions
Was it one of my extensions?
I went to the Tools->Add-ons to try disabling them all ...
and Firefox froze. Bingo! That was actually good news. Problems like
"Firefox freezes a lot" are hard to debug. "Firefox freezes every time
I open Tools->Add-ons" are a whole lot easier.
Now I needed to find some other way of disabling extensions to see if
that helped.
I went to my Firefox profile directory and moved everything
in the extensions directory into a new directory I made called
extensions.sav. Then I started moving them back one by one,
each time starting Firefox and calling up Tools->Add-ons.
It turned out two extensions were causing the freeze: Open in Browser
and Custom Tab Width. So I left those off for the time being.
Disabling Themes
Along the way, I discovered that clicking on Appearance in
Tools->Add-ons would also cause a freeze, so my visual
theme was also a problem. This wasn't something I cared about:
some time back when Mozilla started trumpeting their themeability,
I clicked around and picked up some theme involving stars and planets.
I could live without that.
But how do you disable a theme?
Especially if you can't go to Tools->Add-ons->Appearance?
Turns out everything written on the web on this is wrong. First,
everything on themes on mozilla.org assumes you can get to that
Appearance tab, and doesn't even consider the possibility that you
might have to look in your profile and remove a file.
Search further and you might find references to files named
lightweighttheme-header and lightweighttheme-footer, neither of
which existed in my profile.
But I did have a directory called lwtheme.
So I removed that, plus four preferences in prefs.js that included
the term "lightweightThemes".
After a restart, my theme was gone, I was able to view that Appearance tab,
and I was able to browse the web for nearly 4 hours before firefox hung again.
Darn! That wasn't all of it.
Debugging the environment
But soon after that I had a breakthrough.
I discovered a page on my bank's website that froze Firefox every time.
But that was annoying for testing, since it required logging in then
clicking through several other pages, and you never know what a bank
website might decide to do if you start logging in over and over.
I didn't want to get locked out.
But then I was checking an episode in one of the podcasts I listen to,
which involved going to the link
http://downloads.bbc.co.uk/podcasts/radio4/moreorless/rss.xml
-- and Firefox froze, on a simple RSS link. I restarted and tried
again -- another freeze. I'd finally found the Rosetta stone,
something that hung Firefox every time. Now I could do some serious testing!
I'd had friends try this using the same version of Firefox and Ubuntu,
without seeing a freeze. Was it something about my user environment?
I created a new user, switched to another virtual console (Ctrl-Alt-F2)
and logged in as my new user, then ran X. This was a handy way to test:
I could get to my normal user's X session in Ctrl-Alt-F7, while the new
user's X session was on Ctrl-Alt-F8. Since I don't have Gnome or KDE
installed on this machine, the new user came up with a default Openbox
session. It came up at the wrong resolution -- the X11 in the newest
Linux distros apparently doesn't read the HDMI monitor properly --
but I wasn't worried about that.
And when I ran Firefox as the new user (letting it create a new profile)
and middlemouse-pasted the BBC RSS URL, it loaded it, without freezing.
Now we're getting somewhere.
Now I knew it was something about my user environment.
I tried copying all of ~/.config from my user to the new user. No hang.
I tried various other configuration files. Still no hang.
The X initialization
I'll skip some steps here, and just mention that in trying to fix the
resolution problem, so I didn't have to do all my debugging at 1024x768,
I discovered that if I used my .xinitrc file to start X, I'd get a freezy
Firefox. If I didn't use my .xinitrc, and defaulted to the system one,
Firefox was fine. Even if I removed everything else from my .xinitrc,
and simply ran openbox from it, that was enough to make Firefox hang.
Okay, what was the system doing? I poked around /etc/X11:
it was running /etc/X11/Xsession. I copied that file to my
.xinitrc and started X. No hang.
Xsession does a bunch of things, but one of the main things it does is run
every script in the /etc/X11/Xsession.d directory.
So I made a copy of that directory inside my home directory, and modified
.xinitrc to execute those files instead. Then I started moving them
aside to see which ones made a difference.
And I found it. /etc/X11/Xsession.d/75dbus_dbus-launch was the
file that mattered.
75dbus_dbus-launch takes the name of the program that's
going to be executed -- in this case that was x-session-manager, which
links to /etc/alternatives/x-session-manager, which links to
/usr/bin/openbox-session -- and instead runs
/usr/bin/dbus-launch --exit-with-session x-session-manager.
Now that I knew that, I moved everything aside and made a little
.xinitrc that ran
/usr/bin/dbus-launch --exit-with-session openbox-session.
And Firefox didn't crash.
Dbus
So it all comes down to dbus. I was already running dbus: ps shows
/usr/bin/dbus-daemon --system running -- and that worked fine
for everything dbussy I normally do, like run "gimp image.jpg" and
have it open in my already running GIMP.
But on Ringtail and Sid, that isn't enough for Firefox. For some
reason, on these newer systems, Firefox requires a second
dbus daemon -- it shows up in ps as
/usr/bin/dbus-daemon --fork --print-pid 5 --print-address 7 --session
-- for the X session. If it doesn't have that, it's fine for a while,
and then, hours later, it will mysteriously freeze while waiting for
a network resource.
Why? I have no idea. No one I've asked seems to know anything about
how dbus works, the difference between system and session dbus daemons,
or why any of it it would have this effect on Firefox.
I filed a Firefox bug,
Bug 881122,
though I don't have much hope of anyone being interested in a bug
that only affects Linux users using nonstandard X sessions.
But maybe I'm not the only one. If your Firefox is hanging and
you found your way here, I hope I've given you some ideas.
And if anyone has a clue as to what's really happening and why
dbus would have that effect, I'd love to hear from you.
Tags: firefox, mozilla, debugging, linux, debian, ubuntu, dbus
[
20:08 Jun 09, 2013
More linux |
permalink to this entry |
]
Tue, 24 Apr 2012
When I upgraded to Firefox 11 a month or so ago, I got a surprise:
I couldn't invoke firefox from other applications any more.
Clicking on a link in an app such as xchat just gave me the Firefox
Profile Manager dialog, instead of opening the link in the browser
I was already running.
I couldn't find anything written about it, so I've been putting up
with it, copying each link then switching to the desktop where Firefox
is running and middleclick-pasting it into the browser. But this morning,
I did a new round of searching, and finally found the answer, in
bug 716110.
and its duplicate,
716361.
Quoting from bug 716110::
[The developers] changed the -no-remote flag's behavior in a
surprising, backward incompatible way. Before, it just meant "start a
new instance." Now, it also means "don't listen for remote commands."
Apparently the change went in for Firefox 9, because of
bug 650078.
Indeed, that was the problem. I have multiple Firefox profiles, so
I use -no-remote -P profilename when I start Firefox, so
each profile doesn't conflict with one that might already be running.
But with Firefox 9 or later, you can't do that. Instead, run your
first, primary profile without -no-remote; then if you start up other
profiles later, run them with -no-remote so they don't conflict with
the first one. That works okay for my typical usage, fortunately: I
have a main Firefox window I run all day, and only start up other
profiles for short periods.
But since not everyone uses this model, fortunately, some upcoming
Firefox version will fix the problem by adding a new runtime flag,
-new-instance, to do what -no-remote used to do:
start up a window for a new profile, rather than talking to the
running Firefox. Here's the new --help text:
| -no-remote | Do not accept or send remote commands; implies -new-instance.\n
|
| -new-instance | Open new instance, not a new window in running instance.\n
|
The web
Command
Line Options page doesn't seem to have been updated yet, but
perhaps it will when the Firefox with the fix is released.
Of course, it would have been much simpler if Firefox just honored
the -P flag and used whatever profile it was given, as suggested by a
commenter
in bug 650078. But bsmedberg replies that the complexity of the code
makes that difficult.
The new arguments look more sensible than the old -no-remote, though
it's frustrating that it was so hard to find information about changes
like this. All three bugs are filled with comments from people who,
like me, lost a lot of time trying to figure out what broke and how to
launch URLs remotely after the change. Thanks to Ryan for clarifying
the issue and filing the bug to fix the problem, and to Jed, who added
the new flag with his first Mozilla patch. Hooray for open source!
Tags: firefox, mozilla
[
11:26 Apr 24, 2012
More tech/web |
permalink to this entry |
]
Sun, 09 Oct 2011
A group of us were commiserating about that widely-reviled
feature, Google Instant. That's the thing that refreshes your Google
search page while you're still typing, so you always feel like you
have to type reallyreallyfasttofinishyourquerybeforeitupdates.
Google lets you turn off Instant -- but only if you let them set and
remember your cookies, meaning they can also track you across the web.
Isn't there a more privacy-preserving way to get a simple Google
page that doesn't constantly change as you change your search query?
Disable Instant
It turns out there is. Just add complete=0 to your search
queries.
How do you do that? Well, in Firefox, I search in the normal URL bar.
No need for a separate search field taking up space in the browser window;
any time you type multiple terms (or a space followed by a single term)
in Firefox's URLbar, it appends your terms to whatever you have set as
the keyword.URL preference.
So go to about:config and search for keyword, then double-click on
keyword.URL and make sure it's something like
"http://www.google.com/search?complete=0&q=".
Or if you want to make sure it won't be overridden,
find your
Firefox profile, edit user.js (create it if you don't have one
already), and add a line like:
user_pref("keyword.URL", "http://www.google.com/search?complete=0&q=");
Show only pages matching the search terms
I use a slightly longer query, myself:
user_pref("keyword.URL", "http://www.google.com/search?complete=0&q=allintext%3A+"
Adding allintext: as the first word in any search query tells
Google not to show pages that don't have the search terms as part of
the page. You might think this would be the default ... but The Google
Works in Mysterious Ways and it is Not Ours to Question.
Disable Instant Previews
Finally, just recently Google has changed their search page again to
add a bunch of crap down the right side of the page which, if you
accidentally mouse on it, loads a miniature preview of the page over on
your sidebar. You have to be very careful with your mouse not to have
stuff you might not be interested in popping up all the time.
A moment's work with Firebug gave me the CSS classes I needed to hide.
Edit chrome/userContent.css in your Firefox profile (create it
if you don't already have one) and add this rule:
/* Turn off the "instant preview" annoying buttons in google search results */
.vspib, .vspii { display: none !important; }
Really, it's a darn shame that Google has gone from its origins as a
clean, simple website to something like Facebook with things popping
up all over that users have to bend over backward to disable.
But that seems to be the way of the web.
Good thing browsers are configurable!
Tags: firefox, mozilla, web, google, annoyances, user interface
[
22:31 Oct 09, 2011
More tech/web |
permalink to this entry |
]
Fri, 30 Sep 2011
So everybody's complaining about that new Facebook ticker. You know,
the thing that sits on the right sidebar and constantly and distractingly
updates with stupid stuff you don't care about and wouldn't be able to
click on quickly enough even if you tried.
My mom forwarded me a link to a neat page she'd seen with instructions on
removing the ticker using Adblock Plus.
A good idea -- I hadn't thought about using Adblock, though it does
seem obvious in retrospect.
But I don't currently have Adblock installed in the profile I use for
Facebook -- I keep Facebook separate from my everyday browsing,
since I don't want Facebook tracking all the other sites I visit.
Could I do the same thing with userContent.css?
It turned out to be quite easy. Copying the exact pattern didn't work,
but a minute or two with Firebug told me the CSS class of the ticker.
I edited chrome/userContent.css in my profile. If you don't
have one already, just look for userContent-example.css and create
a new file in the same directory without the -example part, named
just userContent.css. I added this line:
.tickerOnTop { display: none !important; }
Restart firefox, and presto! No more ticker.
Tags: web.firefox, mozilla, annoyances, user interface
[
21:58 Sep 30, 2011
More tech/web |
permalink to this entry |
]
Mon, 09 May 2011
Mostly the transition to Firefox4 has pretty smooth. But there's been one
big hassle: middlemouse content load URL doesn't work as well as it used to.
Middlemouse content load is a great Firefox feature on Linux and other Unix
platforms. You see a URL somewhere that doesn't have clickable URLs --
say, a plaintext mail message, or something somebody typed in IRC.
You highlight it with the mouse --
no need to Copy explicitly -- X does that automatically whenever you
highlight text). Then move to the Firefox window and click the middle mouse
button somewhere in the content window -- anywhere as long as it's not
over a link or text input -- and Firefox goes straight to the URL you pasted.
A few silly Linux distros, like Ubuntu, disable this feature
by default. You can turn it back on by going to about:config,
searching for middlemouse, and setting
middlemouse.contentLoadURL to true.
Except, in Firefox 4, much of the time nothing happens. In Firefox 4,
contentLoadURL only works if the URL you pasted is a complete URL,
like http://example.com. This is completely silly, because
most of the time, if you had a complete URL, it would have been
clickable already in whatever window you originally found it in.
When you need contentLoadURL is
when someone types "Go to example.com if you want to see this".
It's also great for when
you get those horrible Facebook or Stumbleupon or Google URLs like
http://www.facebook.com/l/bfd4f/example.com/somelink
and you want just the real link (example.com/somelink),
without the added cruft.
Hacking the jar
Hooray! It turns out the offending code is in browser.js,
so it's hackable without needing to recompile all of Firefox.
You just need to unpack omni.jar,
patch browser.js, then zip up a new omni.jar.
In other words, something like this (on Ubuntu Natty,
starting in an empty directory):
$ cp /usr/lib/firefox-4.0/omni.jar ~/omni-jar.sav
$ unzip /usr/lib/firefox-4.0/omni.jar
[ edit or patch chrome/browser/content/browser/browser.js ]
$ rm -f /tmp/new-omni.jar; zip /tmp/new-omni.jar `find .`
$ sudo cp /tmp/new-omni.jar /usr/lib/firefox-4.0/omni.jar
Getting Firefox to notice code changes
Except, as I was testing this, I discovered: I could make changes and
most of the time Firefox wouldn't see them. I would put in something
obvious like alert("Hello, world");, verify that the alert
was really in omni.jar, run Firefox, click the middle mouse button and --
no alert. Where was Firefox getting the code it was actually running,
if not from omni.jar?
I'll spare you the agonizing details of the hunt and just say that
eventually I discovered that if I ran Firefox from a different profile
on the same machine, I got a different result.
It turns out that if you remove either of two files,
extensions.sqlite and XUL.mfasl,
Firefox4 will re-read the new code in omni.jar.
Removing XUL.mfasl seems to be a little safer: extensions.sqlite
contains some details of which extensions are enabled.
Of course, back up both files first before experimenting with
removing them.
Why these files are keeping a cache of code that's already in omni.jar is
anybody's guess.
The Patch: fix contentLoadURL
Oh, and the change? Mikachu came up with a cleaner fix than
mine, so this is his. It accepts partial URLs like
example.com and also bookmarklet keywords:
--- browser.js.sav 2011-05-07 16:40:03.672540242 -0700
+++ omni/chrome/browser/content/browser/browser.js 2011-05-08 16:29:28.943313984 -0700
@@ -10597,12 +10597,10 @@
clipboard.replace(/\s*\n\s*/g, "");
let url = getShortcutOrURI(clipboard);
- try {
- makeURI(url);
- } catch (ex) {
- // Not a valid URI.
- return;
- }
+ var URIFixup = Components.classes["@mozilla.org/docshell/urifixup;1"]
+ .getService(Components.interfaces.nsIURIFixup);
+ url = URIFixup.createFixupURI(url, 1).spec;
+ // 1 is FIXUP_FLAG_ALLOW_KEYWORD_LOOKUP
try {
addToUrlbarHistory(url);
Tags: firefox, mozilla, programming, browsers
[
20:28 May 09, 2011
More tech/web |
permalink to this entry |
]
Sun, 20 Jun 2010
Regular readers probably know that I use
HTML
for the slides in my talks, and I present them either with Firefox
in fullscreen mode, or with my own Python
preso
tool based on webkit.
Most of the time it works great. But there's one situation that's
always been hard to deal with: low-resolution projectors.
Most modern projectors are 1024x768, and have been for quite a few years,
so that's how I set up my slides. And then I get asked to give a talk
at a school, or local astronomy club, or some other group that
has a 10-year-old projector that can only handle 800x600. Of course,
you never find out about this ahead of time, only when you plug in
right before the talk. Disaster!
Wait -- before you object that HTML pages shouldn't use pixel values and
should work regardless of the user's browser window size: I completely
agree with you. I don't specify absolute font sizes or absolute
positioning on web pages -- no one should.
But presentation slides are different: they're designed for
a controlled environment where everyone sees the same thing using the
same software and hardware.
I can maintain a separate stylesheet -- that works for making the
font size smaller but it doesn't address the problem of pictures too
large to fit (and we all like to use lots of pictures in presentations,
right?) I can maintain two separate copies of the slides for the two sizes,
but that's a lot of extra work and they're bound to get out of sync.
Here's a solution I should have thought of years ago: full-page zoom.
Most major browsers have offered that capability for years, so the
only trick is figuring out how to specify it in the slides.
IE and the Webkit browsers (Safari, Konqueror, etc.) offer a wonderful
CSS property called zoom. It works like this:
body {
zoom: 78.125%;
}
78.125% is the ratio between an 800-pixel projector and a 1024-pixel one.
Just add this line, and your whole page will be scaled down to the
right size. Lovely!
Lovely, except it doesn't work on Firefox
(bug 390936).
Fortunately, Firefox has another solution: the more general and not yet
standardized CSS transform, which Mozilla has implemented as the
Mozilla-specific property
-moz-transform.
So add these lines:
body {
position: absolute; left: 0px; top: 0px;
-moz-transform: scale(.78125, .78125);
}
The position: absolute is needed because when Firefox scales
with -moz-transform, it also centers whatever it scaled, so the
slide ends up in the top center of the screen.
On my laptop, at least, it's the upper left part of the screen that
gets sent to the projector, so slides must start in the upper left corner.
The good news is that these directives don't conflict; you can put
both zoom and -moz-transform in the same rule and things
will work fine. So I've added this to the body rule in my slides.css:
/* If you get stuck on an 800x600 projector, use these:
zoom: 78.125%;
position: absolute; left: 0px; top: 0px;
-moz-transform: scale(.78125, .78125);
*/
Uncomment in case of emergency and all will be well.
(Unless you use Opera, which doesn't seem to understand either version.)
Tags: speaking, html, css, browsers, firefox, mozilla
[
12:14 Jun 20, 2010
More tech/web |
permalink to this entry |
]
Fri, 19 Mar 2010
I discovered recently that 1067 lines in my Firefox preferences file
(out of 1438 total) were devoted to duplicating default printer settings.
I got a new printer recently.
I needed to set up a preference in user.js so I can
switch
temporarily to landscape mode printing without having landscape
mode become permanent. So I checked in on prefs.js to
see what Firefox called my new printer -- and, well, eek!
For every printer I've ever used on this machine, I had a set
of options that looked like this:
user_pref("print.printer_Epson.print_bgcolor", false);
user_pref("print.printer_Epson.print_bgimages", false);
user_pref("print.printer_Epson.print_colorspace", "default");
user_pref("print.printer_Epson.print_command", "lpr ${MOZ_PRINTER_NAME:+-P\"$MOZ_PRINTER_NAME\"}");
user_pref("print.printer_Epson.print_margin_bottom", "0.500000012107193");
user_pref("print.printer_Epson.print_margin_left", "0.500000012107193");
and so on -- 41 lines, in the case of print.printer_Epson.
But some printers had multiple sets of preferences -- here's the
list of printer names, each of which had those 41 lines, more or less:
- printer_Brother
- printer_CUPS/Brother
- printer_CUPS/Epson
- printer_CUPS/epson
- printer_Epson
- printer_PostScript/default
- printer_Print_to_File
- printer_Deskjet-F4200-series
- printer_HP_Deskjet_F4200_series
In case you're curious, this encompasses three physical printers
I've used with Firefox:
my old Epson C86, my new HP F4280, and Dave's Brother HL 2070N.
None of these values is anything I've ever set myself;
they're all default values.
Why Firefox feels the need to store them for all eternity is anybody's guess.
But wait, you say ... 41 lines times 9 printers is a lot, but it
doesn't come close to equalling 1067 lines. What else is there?
Well, there are another 43 lines that repeat all those same defaults
again but don't specify any particular printer, like
user_pref("print.print_footerleft", "&PT");.
And then, oh wait, what's this? All the preceding prefs
are duplicated all over again, with "tmp" added, like this:
user_pref("print.tmp.printerfeatures.Brother_HL-2070N_series.supports_paper_size
_change", true);
user_pref("print.tmp.printerfeatures.CUPS/Brother.orientation.count", 2);
and so on. 456 lines of that.
Unfortunately, I got a little over-zealous in deleting lines before
I'd made a backup of the original file. So by the time it occurred to
me to write this up, I'd destroyed some of the evidence and had to
work from a backup, which "only" had 813 lines of print preferences.
Part of that is that I didn't have the new printer yet (two entries
times 41 lines times two) but that only gets me up to 977 lines.
I'm not sure what the other 190 lines were.
How many printing preferences do you have?
You can see them by going to about:config and typing print.
Or on Linux, you can count them. First
find your
profile folder, where your prefs.js file lives,
or search for prefs.js directly:
locate prefs.js | grep home
Then use wc on that prefs.js file to count your print preference lines:
grep print yourprofile/prefs.js | wc -l
As to why Firefox uses so many redundant lines in the preference file
for settings that have never been changed from the defaults ... well,
your guess is as good as mine.
Tags: firefox, mozilla, preferences, printing
[
19:59 Mar 19, 2010
More tech/web |
permalink to this entry |
]
Tue, 01 Dec 2009
"Cookies are small text files which websites place on a visitor's
computer."
I've seen this exact phrase hundreds of times, most recently on a site
that should know better,
The Register.
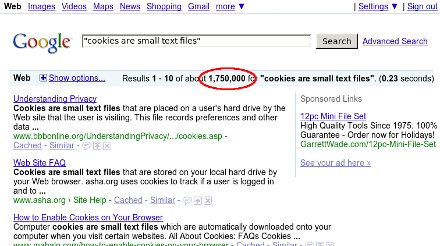
I'm dying to know who started this ridiculous non-explanation,
and why they decided to explain cookies using an implementation
detail from one browser -- at least, I'm guessing IE must implement cookies
using separate small files, or must have done so at one point. Firefox
stores them all in one file, previously a flat file and now an sqlite
database.
How many users who don't know what a cookie is do know what a
"text file" is? No, really, I'm serious. If you're a geek, go ask a few
non-geeks what a text file is and how it differs from other files.
Ask them what they'd use to view or edit a text file.
Hint: if they say "Microsoft Word" or "Open Office",
they don't know.
And what exactly makes a cookie file "text" anyway?
In Firefox, cookies.sqlite is most definitely not a "text file" --
it's full of unprintable characters.
But even if IE stores cookies using printable characters --
have you tried to read your cookies?
I just went and looked at mine, and most of them looked something like this:
Name: __utma
Value: 76673194.4936867407419370000.1243964826.1243871526.1243872726.2
I don't know about you, but I don't spend a lot of time reading text
that looks like that.
Why not skip the implementation details entirely, and just tell users
what cookies are? Users don't care if they're stored in one file or many,
or what character set is used. How about this?
Cookies are small pieces of data which your web browser stores at the
request of certain web sites.
I don't know who started this meme or why people keep copying it
without stopping to think.
But I smell a Fox Terrier. That was Stephen Jay Gould's example,
in his book Bully for Brontosaurus, of a
factoid invented by one writer and blindly copied by all who come later.
The fox terrier -- and no other breed -- was used universally for years to
describe the size of Eohippus. At least it was reasonably close;
Gould went on to describe many more examples where people copied the
wrong information, each successive textbook copying the last with
no one ever going back to the source to check the information.
It's usually a sign that the writer doesn't really understand what
they're writing. Surely copying the phrase everyone else uses must
be safe!
Tags: web, browsers, writing, skepticism, tech, firefox, mozilla
[
21:25 Dec 01, 2009
More tech/web |
permalink to this entry |
]
Mon, 13 Apr 2009
I'm taking a CSS class, hoping to get a more solid understanding of
these CSS parameters I tweak and why they do or don't work, and
one of the exercises involved using the CSS font family "cursive".
Which, on my Firefox, displayed in MS Comic Sans. That doesn't look
very cursive to me!
To test what you're seeing now for cursive and fantasy, use the
W3C
font-family test page ... or these might work (though they might
not survive RSS feeds to other sites):
This is a Cursive font
... ...
This is a Fantasy font
Being a font junkie, I have plenty of nice cursive fonts installed.
The question was how to tell Firefox about them, since its font
dialog (unlike the old Seamonkey/Mozilla suite's) doesn't
make any allowance for setting them, nor do the categories show up
in about:config.
Method 1: Firefox prefs
The answer was in this
Mozillazine
thread. Edit user.js in your Firefox profile
and add lines like:
// Set cursive and fantasy fonts
user_pref("font.name.cursive.x-western", "Allegro");
user_pref("font.name.fantasy.x-western", "Dragonwick");
(of course, use fonts you have installed, not necessarily Allegro
and Dragonwick).
The bug (marked WONTFIX) requesting Firefox offer this in the
Preferences window is
bug 196405,
and related
bug 61883.
Method 2: fontconfig
But wait! Soon after I figured out how to set the font family for
Firefox, I noticed that the font was still MS Comic Sans in other
browsers -- konqueror, midori, opera. It occurred to me that that
Comic Sans cursive was probably coming from fontconfig settings,
and it should be possible to change fontconfig's defaults
for these categories.
And indeed it was, and fairly simple, too. Just make a file named
.fonts.conf in your home directory and add this to it:
<?xml version='1.0'?>
<!DOCTYPE fontconfig SYSTEM 'fonts.dtd'>
<fontconfig>
<alias>
<family>cursive</family>
<prefer>
<family>Allegro</family>
</prefer>
</alias>
<alias>
<family>fantasy</family>
<prefer>
<family>BoomerangItalic</family>
</prefer>
</alias>
</fontconfig>
Again, substitute your own fonts ... but beware. The hard part of
this exercise turned out to be that some fonts worked and some
didn't, following no rhyme or reason. My first five choices for a
fantasy font weren't picked up by fontconfig, but finally I found a
few that were. It isn't related to whether they have spaces in the
font name; it isn't where they're installed (I was using only fonts in
~/.fonts); I have no idea why some fonts work in ~/.fonts.conf and
others don't.
It's rather tedious to test, since the only way to test it is to
exit and re-start firefox. I've never found a font viewer that
will display the fonts visible to fontconfig or pango; you have to
start up some full-fledged application like firefox or gimp, and
gimp doesn't see categories like cursive or fantasy.
In the end I did find fonts that worked in firefox.
But ironically, although the system-level fix seems like a better
way to go, my font changes still don't show up in other browsers.
In opera, cursive shows up in bold block letters,
while its fantasy is MS Comic Sans.
Konqeror and Midori don't handle cursive and fantasy at all,
showing them as plain sans-serif.
And in IE6 running under wine, cursive still shows up as MS
Comic Sans ... while fantasy displays in Greek letters.
Tags: mozilla, firefox, fonts, css
[
21:30 Apr 13, 2009
More tech/web |
permalink to this entry |
]
Wed, 18 Mar 2009
Firefox started forgetting new bookmarks. I'd make a few bookmarks,
filing them in the right place ... then the next time I started up,
they wouldn't be there and I had to go find them again. I tested
and verified that it wasn't that I was exiting Firefox uncleanly;
even if I ran from the terminal, made a bookmark, and exited,
nothing would be saved.
It took me forever to find anything on this with google, so I'm
blogging it in the hope of making it easier for the next person
to find. It turns out the Mozilla Knowledge Base has a terrific
article called
Bookmarks
not saved that discusses lots of ways this can happen. Go through
the list and you'll probably find a solution.
In my case it was the second item: "Places preferences - Firefox 3".
It turned out that all three of my boolean browser.places
preferences were set to non-default values -- not by me, since I'd
never heard of any of the browser.places preferences before.
After toggling all three of them by double-clicking,
Firefox lost its
anterograde
amnesia and started remembering new bookmarks again.
Tags: firefox, mozilla, tips
[
23:01 Mar 18, 2009
More tech/web |
permalink to this entry |
]
Sun, 11 Jan 2009
Update: For details on how to edit Firefox history rather than just
delete it, see this later post:
Removing Bad Autocompletes from Firefox's Location Bar.
Firefox decided, some time ago, that whenever I try to type in a local
file pathname, as soon as I start typing /home/... I must be
looking for one specific file: an article I wrote over two months
ago and am long since done with.
Usually it happens when I'm trying to preview a new article.
I no longer have any interest in my local copy of that old article;
it's not bookmarked or anything like that; I haven't viewed it in
quite some time. But try to tell Firefox that. It's convinced that
the old one (why that one, and not one of the more recent ones?)
is what I want.
A recursive grep in ~/.mozilla/firefox showed that the only reference
to the old unwanted file was in the binary file places.sqlite.
My places.sqlite was 11Mb. I look through the Prefs window
showed that the default setting was to store history for minimum of
90 days. That seemed rather excessive, so I reduced it drastically.
But that didn't reduce the size of the file any, nor did it banish
the spurious URLbar suggestion when I typed /home/....
After some discussion with folks on IRC, it developed that Firefox
may never actually reduce the size of the places.sqlite file at all.
Even if it did reduce the amount of data in the file (which it's not
clear it does), it never tells sqlite to compact the file to use less
space. Apparently there was some work on that about a year ago, but it
was slow and unreliable and they never got it working, and
eventually gave up on it.
You can run an sqlite compaction by hand (make sure to exit your
running firefox first!):
sqlite3 places.sqlite vacuum
But vacuuming really didn't help much. It reduced the size of the file
from 11 to 8.8 Mb (after reducing the number of days firefox was
supposed to store to less than a third of the original size) and it
didn't get rid of that spurious suggestion.
So the only remaining option seemed to be to remove the file.
It stores both history and bookmarks, so it's best to back up
bookmarks before removing it. I backed up bookmarks to the
.json format firefox likes to use for backups, and also exported
them to a more human (and browser) readable bookmarks.html.
Then I removed the places.sqlite file.
Success! The spurious recommendation was gone. Typing seems faster
too (less of those freezes while the "awesomebar" searches through
its list of recommendations).
So I guess firefox can't be trusted to clean up after itself,
and users who care have to do that manually.
It remains to be seen how much the file will grow now. I expect
periodic vacuumings or removals will still be warranted if I don't
want a huge file; but it's pretty easy to do, and firefox found the
bookmarks backup and reloaded them without any extra work on my part.
In the meantime, I made a new bookmark -- hidden in my bookmarklets
menu so it doesn't clutter the main bookmarks menu -- to the
directory where I preview articles I'm writing. That ought to help a
bit with future URLbar suggestions.
Tags: firefox, mozilla, performance
[
12:00 Jan 11, 2009
More tech/web |
permalink to this entry |
]
Thu, 20 Nov 2008
I have a new Firefox Tips article up on Linux Planet:
The
Plague of Ridiculously Long URLs
(note I didn't choose the title). It discussees how to handle
long URLs broken over several lines, of the sort we so often
see in email messages.
Tags: writing, mozilla, firefox
[
10:43 Nov 20, 2008
More writing |
permalink to this entry |
]
Thu, 06 Nov 2008
My latest Linux Planet article,
Why
Firefox Rocks on Linux, discusses Linux-specific Firefox
shortcuts involving the middle mouse button, the URLbar and
the scrollbar.
It's getting
good
Diggs, too, and comments from people who found the tips helpful,
which is great. A lot of people don't know about some of these great
Linux time-savers, but these are the sort of things that make me
love Linux and stick with it even when it gets frustrating.
I hate to think of people missing out just because there's no
obvious way to discover some of the shortcuts!
Tags: writing, mozilla, firefox, linux
[
21:44 Nov 06, 2008
More writing |
permalink to this entry |
]
Mon, 03 Nov 2008
This posting ended up being published as a Linux Planet Quick Tip.
You can read about my nifty word counting bookmarklet there:
Quick
Firefox Tip: Word Count Bookmarklet.
Tags: firefox, mozilla, bookmarklets, writing, programming
[
23:41 Nov 03, 2008
More tech/web |
permalink to this entry |
]
Sun, 26 Oct 2008
Mon, 08 Sep 2008
Among Firefox 3's whizzy new features, compared to Firefox 2, is the
drag images. If you drag from anywhere in the browser, instead of
getting the little cursor-sized drag image following the cursor, you
get a preview -- sometimes even a full-sized copy -- of what you're
dragging.
It's really startling and neat and whizzy looking. Except ...
when you're dragging and you have this large very pretty, and very
opaque, image under your mouse,
you can no longer see whatever should be under the image --
like the tab where you're trying to drop it.
After two or three weeks of never being able to drag a URL to another
tab to open it there (I kept guessing where the tab was, guessing
wrong and having it open as a new tab) I went exploring.
Fortunately it turns out they've provided an easy way to turn it off.
Go to about:config and search for "drop". Find the line for
nglayout.enable_drag_images and double-click it.
Or add this line to your user.js or prefs.js:
user_pref("nglayout.enable_drag_images", false);
Tags: firefox, mozilla, user interface
[
20:21 Sep 08, 2008
More tech/web |
permalink to this entry |
]
Fri, 04 Jul 2008
Oops! Right after I posted that last entry, I discovered that my
little kitfox extension wasn't working as well as I'd thought.
And the more I hacked it, the less well it worked, and the more
I discovered was missing, like a chrome.manifest file (which
firefox 2 hadn't seemed to need).
Eventually some very helpful folks on #extdev pointed me to
Ted Mielczarek's excellent Extension
Wizard. Give it some details about your extension (its name and
version, your name, and a couple things you might want like a
toolbar button, a prefs panel and a context menu) and it generates
a zipped directory containing a bare bones extension, even including
niceties like internationalized strings.
Even better, your new extension skeleton includes a readme that
tells you how to leave the extension expanded while you work on
it. That's quite a bit easier than building the XPI file and installing
it each time.
So kitfox has a
0.3 version (in the unlikely event that anybody besides me wants it).
There's a project called
fizzypop
to develop and extend useful Mozilla dev tools like the Extension Wizard ...
watch that space for more details.
Tags: mozilla, firefox, open source
[
21:12 Jul 04, 2008
More tech/web |
permalink to this entry |
]
I finally broke down and spent the time to get Firefox 3 working
properly for me ... meaning, mostly, finding replacement extensions
for the bare minimum of what I need in a browser: control over cookies
(specifically, enabling/disabling them for specific sites),
flashblock, and blocking of animated images. I'd downloaded extensions
for all those a few weeks ago, but I found that although Firefox 3.0
said the FF3 extensions were active, and Firefox 2 said the old ones
were, neither set actually worked.
I decided to start from scratch: remove all extensions --
rm -rf .mozilla/firefox/extensions/* .mozilla/firefox/extensions.*
plus apt-get remove firefox-2-dom-inspector --
then install a new set of Firefox 3 add-ons.
After much hunting
(I sure wish addons.mozilla.org
would offer a way to limit the view to only extensions that work with
Firefox 3! Combing through 15 pages of extensions looking for the
handful that will actually install gets old fast) I found the
replacements I needed:
CS Lite for the cookie controls,
a newer Flashblock,
and Custom Toolbar Buttons as a stopgap for image animation
(though I suspect updating anidisable will be a better solution
in the long run). This time, with the old firefox 2 extensions purged,
the new ones took hold and worked.
I also added a nice extension called OpenBook that fixes the horrible
Firefox "Add bookmark" dialog. You know: the one that has two nearly
identical dropdown category menus side by side, with the bigger one
giving you only a tiny subset of your bookmark categories, and the
smaller one being the real one. The one that doesn't offer a space for
keyword, so to set up a bookmarklet you have to Add Bookmark, OK,
Organize Bookmarks, find the bookmark you just added, Ctrl-I to
get the Bookmark info dialog, and finally you can add your
keyword. OpenBook gives you a dialog where you can set the keyword
to begin with, and it only gives you one menu to list categories
so you aren't constantly tempted to click on the wrong one.
Now for the urlbar -- that new firefox 3 "smarter" urlbar that slows
down typing in the middle of a word so it can pop up a big fancy
window full of guesses (all wrong) about where I might be trying to
go. Actually, even if the guesses were right, it wouldn't help,
because I'd have to stop typing, search the list visually, then if
one of the suggestions was right, move my hand to the mouse or the
arrow keys to choose that suggestion. That takes way longer than just
typing the url.
But I guess I don't mind unhelpful suggestions popping up as long as
it doesn't mess up focus (preventing me from clicking or tabbing to
other apps on my screen) or slow down typing. Firefox 3 seems to be
handling the focus issue better than firefox 2 did, but the slowdown
was quite noticeable on the poor old laptop. So I wanted a way to
disable the behavior. A little googling revealed that the Firefox crew
immodestly calls their new urlbar the "awesomebar", which aside from
giggle factor also proves quite useful in googling: a search on
firefox
disable awesomebar reveals that I'm not the only one who doesn't
like it, and got me several preferences
I could tweak in about:config plus a couple of extensions to
turn it off entirely. I won't try to summarize, since the best
settings depend on your machine's spec, plus personal preference.
Making progress! Now the only issue was getting my urlbar tweaks working,
so that typing <Ctrl-Return> after typing a URL opened the URL in a new
tab instead of tacking on various silly extensions (oh, yes, of course
I wanted to go to http://www.firefox disable awesomebar.com
rather than googling for those terms in a new tab).
Fortunately, it turned out that the javascript that runs the urlbar
has changed very little since firefox 2, and I hardly needed to change
anything to get my
kitfox extension (v. 0.2)
working in Firefox 3.
Only one more issue: this blog. The CSS that handles the right sidebar
wasn't displaying right. Seems that Firefox 2 has changed something
about its interpretation of CSS, so it was floating the right sidebar
way down to the bottom of the page below the last content line.
Eventually (after adding firefox-3.0-dom-inspector,
another extension that had stopped working in the transition)
I discovered the problem: the #content was set to width: 77%
while the #rightsidebar's left-margin was at 76%. Apparently Firefox 2
rounded up as needed, whereas Firefox 3 just ignores the left-margin
if it would overlap the content, and then floats the sidebar anywhere
it thinks it can fit it. Fixing those percentages helped quite a bit,
and I added an overflow-x: hidden (on a tip from a helpful person in
#firefox) so that wide calendar doesn't hurt layout for narrow windows.
I think it's working now ... any readers having problems with the
layout in any browser, by all means let me know.
Tags: mozilla, firefox, user interface, css, bookmarklets
[
12:04 Jul 04, 2008
More tech/web |
permalink to this entry |
]
Thu, 12 Jun 2008
I discovered a handy tip for Linux Firefox' printing Page Setup today.
Normal web page printing uses "Portrait" mode: you read the page
with the paper oriented so that it's taller than it is wide.
Once a week, I need to print a form from a club web site to bring
to the meetings. It's a table that's much wider than it is tall,
so I want to print it that way: in "Landscape" mode.
In Firefox 2 (at least on Linux), you can't do that from the Print
dialog -- there's no Portrait/Landscape option. So you have to use
a separate dialog, Page Setup, following these steps:
- Run Page Setup
- Change Portrait to Landscape
- Click OK
- Print (bring up the Print dialog and click OK)
- Run Page Setup
- Change Landscape to Portrait
- Click OK
Kind of a lot of steps just to print one landscape page!
But if you forget,
the next page you print from Firefox will be printed in Landscape
mode and will take twice as many pages as it should (if you don't
notice what's happening and dive for the printer's OFF switch in time,
that being the only way to cancel a printing job once it hits the printer).
This morning, it finally occurred to me that Firefox was storing this
setting somehow, most likely in prefs.js.
If I could find the setting and force it in user.js (which takes
precedence over prefs.js and is not updated by Firefox), I could make
Firefox set itself back to Portrait every time it starts up.
(prefs.js and user.js are both generally found in $HOME/.mozilla/firefox/).
Some greppery-pokery revealed the solution.
I needed only to add a line in user.js that looks like this:
user_pref("print.printer_CUPS/Epson.print_orientation", 0);
and presto! my problem was solved.
Oddly, it's set separately for every printer you have defined, even
though there's no way to set one printer to Landscape while another
one is still on Portrait (the Page Setup dialog is global, and applies
to every printer Firefox knows about). "Epson" is the CUPS name of my
primary printer; replace that with your printer's name (as set in
CUPS), and add a similar line for each printer you have. For the
printers I've used, 0 is Portrait and 1 is Landscape, but you can
verify that by typing:
grep orientation prefs.js | grep name
That command will also help you
if you're not sure what printers you have defined, or you don't use
CUPS but want to try this under a different print spooler.
(Don't be misled by all the orientation prefs with "tmp" in the name.)
As a minor digression, there's actually a secret pref that's supposed
to give another way around the problem:
user_pref("print.whileInPrintPreview", true);
This lets you do all your printing from the Print Preview window,
which offers its own Portrait and Landscape buttons. That would
be a nice solution. Alas, the Portrait and Landscape buttons in that
dialog currently don't work, and since this preference is undocumented
and unmaintained, filing more bugs isn't likely to help.
(I should mention that this all pertains to Firefox 2.
I haven't switched to Firefox 3 yet,
so I don't know the state of its printing UI, or whether this
preference is either helpful or effective there.)
Tags: mozilla, firefox, printing, tips
[
21:07 Jun 12, 2008
More tech/web |
permalink to this entry |
]
Tue, 08 Apr 2008
A friend pointed me to a story she'd written. It was online as a .txt
file. Unfortunately, it had no line breaks, and Firefox presented it
with a horizontal scrollbar and no option to wrap the text to fit in
the browser window.
But I was sure that was a long-solved problem -- surely there must
be a userContent.css rule or a bookmarklet to handle text with long
lines. The trick was to come up with the right Google query.
Like this one:
firefox OR mozilla wrap text userContent OR bookmarklet
I settled on the simple CSS rule from Tero Karvinen's page on
Making
preformated <pre> text wrap in CSS3, Mozilla, Opera and IE:
pre {
white-space: -moz-pre-wrap !important;
}
Add it to
chrome/userContent.css and you're done.
But some people might prefer not to apply the rule to all text.
If you'd prefer a rule that can be applied at will, a bookmarklet
would be better. Like the
word
wrap bookmarklet from Return of the Sasquatch
or the one from Jesse Ruderman's
Bookmarklets
for Zapping Annoyances collection.
Tags: tech, web, mozilla, firefox, css, bookmarklets
[
11:47 Apr 08, 2008
More tech/web |
permalink to this entry |
]
Sat, 20 Oct 2007
I remember a few years ago the Mozilla folks were making a lot of
noise about the "blazingly fast Back/Forward" that was coming up
in the (then) next version of Firefox. The idea was that the layout
engine was going to remember how the page was laid out (technically,
there would be a "frame cache" as opposed to the normal cache which
only remembers the HTML of the page). So when you click the Back
button, Firefox would remember everything it knew about that page --
it wouldn't have to parse the HTML again or figure out how to lay
out all those tables and images, it would just instantly display
what the page looked like last time.
Time passed ... and Back/Forward didn't get faster. In fact, they
got a lot slower. The "Blazingly Fast Back" code did get checked in
(here's
how to enable it)
but somehow it never seemed to make any difference.
The problem, it turns out, is that the landing of
bug
101832 added code to respect a couple of HTTP Cache-Control header
settings, no-store and no-cache. There's also a
third cache control header, must-revalidate, which is similar
(the difference among the three settings is fairly subtle, and
Firefox seems to treat them pretty much the same way).
Translated, that means that web servers, when they send you a page,
can send some information along with the page that asks the browser
"Please don't keep a local copy of this page -- any time you want
it again, go back to the web and get a new copy."
There are pages for which this makes sense. Consider a secure bank
site. You log in, you do your banking, you view your balance and other
details, you log out and go to lunch ... then someone else comes by
and clicks Back on your browser and can now see all those bank
pages you were just viewing. That's why banks like to set no-cache
headers.
But those are secure pages (https, not http). There are probably
reasons for some non-secure pages to use no-cache or no-store
... um ... I can't think of any offhand, but I'm sure there are some.
But for most pages it's just silly. If I click Back, why wouldn't I
want to go back to the exact same page I was just looking at?
Why would I want to wait for it to reload everything from the server?
The problem is that modern Content Management Systems (CMSes) almost
always set one or more of these headers. Consider the
Linux.conf.au site.
Linx.conf.au is one of the most clueful, geeky conferences around.
Yet the software running their site sets
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Pragma: no-cache
on every page. I'm sure this isn't intentional -- it makes no sense for
a bunch of basically static pages showing information about a
conference several months away. Drupal, the CMS used by
LinuxChix sets
Cache-Control: must-revalidate -- again, pointless.
All it does is make you afraid to click on links because then
if you want to go Back it'll take forever. (I asked some Drupal
folks about this and they said it could be changed with
drupal_set_header).
(By the way, you can check the http headers on any page with:
wget -S -O /dev/null http://... or, if you have curl,
curl --head http://...)
Here's an excellent summary of the options in an
Opera developer's
blog, explaining why the way Firefox handle caching is not only
unfriendly to the user, but also wrong according to the specs.
(Darn it, reading sensible articles like that make me wish I wasn't
so deeply invested in Mozilla technology -- Opera cares so much
more about the user experience.)
But, short of a switch to Opera, how could I fix it on my end?
Google wasn't any help, but I figured that this must be a reported
Mozilla bug, so I turned to Bugzilla and found quite a lot.
Here's the scoop. First, the code to respect the cache settings
(slowing down Back/Forward) was apparently added in response to bug 101832.
People quickly noticed the performance problem, and filed
112564.
(This was back in late 2001.) There was a long debate,
but in the end, a fix was checked in which allowed no-cache http
(non-secure) sites to cache and get a fast Back/Forward.
This didn't help no-store and must-revalidate sites, which
were still just as slow as ever.
Then a few months later,
bug
135289 changed this code around quite a bit. I'm still getting
my head around the code involved in the two bugs, but I think this
update didn't change the basic rules governing which
pages get revalidated.
(Warning: geekage alert for next two paragraphs.
Use this fix at your own risk, etc.)
Unfortunately, it looks like the only way to fix this is in the
C++ code. For folks not afraid of building Firefox, the code lives in
nsDocShell::ShouldDiscardLayoutState and controls the no-cache and
no-store directives. In nsDocShell::ShouldDiscardLayoutState
(currently lie 8224, but don't count on it), the final line is:
return (noStore || (noCache && securityInfo));
Change that to
return ((noStore || noCache) && securityInfo);
and Back/Forward will get instantly faster, while still preserving
security for https. (If you don't care about that security issue
and want pages to cache no matter what, just replace the whole
function with
return PR_FALSE; )
The must-validate setting is handled in a completely different
place, in nsHttpChannel.
However, for some reason, fixing nsDocShell also fixes Drupal pages
which set only must-validate. I don't quite understand why yet.
More study required.
(End geekage.)
Any Mozilla folks are welcome to tell me why I shouldn't be doing
this, or if there's a better way (especially if it's possible in a
way that would work from an extension or preference).
I'd also be interested in from Drupal or other CMS folks defending why
so many CMSes destroy the user experience like this. But please first
read the Opera article referenced above, so that you understand why I
and so many other users have complained about it. I'm happy to share
any comments I receive (let me know if you want your comments to
be public or not).
Tags: tech, web, mozilla, firefox, performance
[
20:32 Oct 20, 2007
More tech/web |
permalink to this entry |
]
Wed, 04 Jul 2007
I like buying from Amazon, but it's gotten a lot more difficult since
they changed their web page design to assume super-wide browser
windows. On the browser sizes I tend to use, even if I scroll right
I can't read the reviews of books, because the content itself is wider
than my browser window. Really, what's up with the current craze of
insisting that everyone upgrade their screen sizes then run browser
windows maximized?
(I'd give a lot for a browser that had the concept of "just show me
the page in the space I have". Opera has made some progress on this
and if they got it really working it might even entice me away from
Firefox, despite my preference for open source and my investment in
Mozilla technology ... but so far it isn't better enough to justify a
switch.)
I keep meaning to try the
greasemonkey extension,
but still haven't gotten around to it.
Today, I had a little time, so I googled to see if
anyone had already written a greasemonkey script to make Amazon readable.
I couldn't find one, but I did find a
page
from last October trying to fix a similar problem on another
website, which mentioned difficulties in keeping scripts working
under greasemonkey, and offered a Javascript bookmarklet with
similar functionality.
Now we're talking! A bookmarklet sounds a lot simpler and more secure
than learning how to program Greasemonkey. So I grabbed the
bookmarklet, a copy of an Amazon page, and my trusty DOM Inspector
window and set about figuring out how to make Amazon fit in my window.
It didn't take long to realize that what I needed was CSS, not
Javascript. Which is potentially a lot easier: "all" I needed to do
was find the right CSS rules to put in userContent.css. "All" is in
quotes because getting CSS to do anything is seldom a trivial task.
But after way too much fiddling, I did finally come up with a rule
to get Amazon's Editorial Reviews to fit. Put this in
chrome/userContent.css inside your Firefox profile directory
(if you don't know where your profile directory is, search your disk
for a file called prefs.js):
div#productDescription div.content { max-width: 90% !important; }
You can replace that 90% with a pixel measurement, like 770px,
or with a different percentage.
I spent quite a long time trying to get the user reviews (a table with
two columns) to fit as well, without success. I was trying things like:
#customerReviews > div.content > table > tbody > tr > td { max-width: 300px; min-width: 10px !important; }
div#customerReviews > div.content > table { margin-right: 110px !important; }
but nothing worked, and some of it (like the latter of those two
lines) actually interfered with the div.content rule for reasons
I still don't understand. (If any of you CSS gurus want to enlighten
me, or suggest a better or more complete solution, or solutions that
work with other web pages, I'm all ears!)
I'll try for a more complete solution some other time, but for now,
I'm spending my July 4th celebrating my independance from Amazon's
idea of the one true browser width.
Tags: tech, web, css, mozilla, firefox
[
21:01 Jul 04, 2007
More tech/web |
permalink to this entry |
]
Thu, 28 Jun 2007
I upgraded my laptop's Ubuntu partition from Edgy to Feisty.
Debian Etch works well, but it's just too old and I can't build
software like GIMP that insists on depending on cutting-edge
libraries.
But Feisty is cutting edge in other ways, so
it's been a week of workarounds, in two areas: Firefox and the kernel.
I'll start with Firefox.
Firefox crashes playing flash
First, the way Ubuntu's Firefox crashes when running Flash.
I run flashblock, fortunately, so I've been able to browse the web
just fine as long as I don't click on a flashblock button.
But I like being able to view the occasional youtube video,
and flash 7 has worked fine for me on every distro except Ubuntu.
I first saw the problem on Edgy, and upgrading to Feisty didn't cure the
problem.
But it wasn't their Firefox build; my own "kitfox" firefox
build crashed as well. And it wasn't their flash installation; I've
never had any luck with either their adobe flash installer nor their
opensource libswfdec, so I'm running the same old flash 7 plug-in
that I've used all along for other distros.
To find out what was really happening, I ran Firefox from the
commandline, then went to a flash page. It turned out it was
triggering an X error:
The error was: 'BadMatch (invalid parameter attributes)'.
(Details: serial 104 error_code 8 request_code 145 minor_code 3)
That gave me something to search for. It turns out there's a longstanding
Ubuntu
bug, 14911 filed on this issue, with several workarounds.
Setting the environment variable XLIB_SKIP_ARGB_VISUALS to 1 fixed the
problem, but, reading farther in the bug, I saw that the real problem
was that Ubuntu's installer had, for some strange reason, configured
my X to use 16 bit color instead of 24. Apparently this is pretty
common, and due to some bug involving X's and Mozilla's or Flash's
handling of transparency, this causes flash to crash Mozilla.
So the solution is very simple. Edit /etc/X11/xorg.conf, look
for the DefaultDepth line, and if it's 16, that's your problem.
Change it to 24, restart X and see if flash works. It worked for me!
Eliminating Firefox's saved session pester dialog
While I was fiddling with Firefox, Dave started swearing. "Why does
Firefox always make me go through this dialog about restoring the last
session? Is there a way to turn that off?"
Sure enough, there's no exposed preference for this, so I poked around
about:config, searched for browser and found
browser.sessionstore.resume_from_crash. Doubleclick that
line to change it to false and you'll have no more pesky
dialog.
For more options related to session store, check the
Mozillazine
Session Restore page.
Kernel: runaway kacpid
Alas, having upgraded to Feisty expressly so that I could build
cutting-edge programs like GIMP, I discovered that I couldn't build
anything at all. Anything that uses heavy CPU for more than a minute
or two triggers a kernel daemon, kacpid, to grab most of the CPU for
itself. Being part of the kernel (even though it has a process ID),
kacpi is unkillable, and prevents the machine from shutting down,
so once this happens the only solution is to pull the power plug.
This has actually been a longstanding Ubuntu problem
(bug 75174)
but it used to be that disabling acpid would stop kacpid from
running away, and with feisty, that no longer helps.
The bug is also
kernel.org
bug 8274.
The Ubuntu bug suggested that disabling cpufreq solved it for one
person. Apparently the only way to do that is to build a new kernel.
There followed a long session of attempted kernel building.
It was tricky because of course I couldn't build on the
target machine (inability to build being the problem I was trying to
solve), and even if I built on my desktop machine,
a large rsync of the modules directory would trigger a
runaway kacpi. In the end, building a standalone kernel with
no modules was the only option.
But turning off cpufreq didn't help, nor did any of the other obvious
acpi options. The only option which stops kacpid is to disable acpi
altogether, and use apm. I'm sorry to lose hibernate, and temperature
monitoring, but that appears to be my only option with modern kernels.
Sigh.
Kernel: Hangs for 2 minutes at boot time initializing sound card
While Dave and I were madly trying to find a set of config options to
build a 2.6.21 that would boot on a Vaio (he was helping out with his
SR33 laptop, starting from a different set of config options) we both
hit, at about the same time, an odd bug: partway through boot, the
kernel would initialize the USB memory stick reader:
sd 0:0:0:0: Attached scsi removable disk sda
sd 0:0:0:0: Attached scsi generic sg0 type 0
and then it would hang, for a long time. Two minutes, as it turned
out. And the messages after that were pretty random: sometimes related
to the sound card, sometimes to the network, sometimes ... GConf?!
(What on earth is GConf doing in a kernel boot sequence?)
We tried disabling various options to try to pin down the culprit:
what was causing that two minute hang?
We eventually narrowed the blame to the sound card (which is a Yamaha,
using the ymfpci driver). And that was enough information for google
to find this
Linux Kernel Mailing List thread. Apparently the sound maintainer
decided, for some reason, to make the ymfpci driver depend on an
external firmware file ... and then didn't include the firmware file,
nor is it included in the alsa-firmware package he references in that
message. Lovely. I'm still a little puzzled about the timeout: the
post does not explain why, if a firmware file isn't found on the
disk, waiting for two minutes is likely to make one magically appear.
Apparently it will be fixed in 2.6.22, which isn't much help for
anyone who's trying to run a kernel on any of the 2.6.21.* series
in the meantime. (Isn't it a serious enough regression to fix in
2.6.21.*?) And he didn't suggest a workaround, except that
alsa-firmware package which doesn't actually contain the firmware
for that card.
Looks like it's left to the user to make things work.
So here's what to do: it turns out that if you take a 2.6.21 kernel,
and substitute the whole sound/pci/ymfpci directory from a 2.6.20
kernel source tree, it builds and boots just fine. And I'm off and
running with a standalone apm kernel with no acpi; sound works, and I
can finally build GIMP again.
So it's been quite a week of workarounds. You know, I used to argue
with all those annoying "Linux is not ready for the desktop"
people. But sometimes I feel like Linux usability is moving in the
wrong direction. I try to imagine explaining to my mac-using friends
why they should have to edit /etc/X11/xorg.conf because their distro
set up a configuration that makes Firefox crash, or why they need to
build a new kernel because the distributed ones all crash or hang
... I love Linux and don't regret using it, but I seem to need
workarounds like this more often now than I did a few years ago.
Sometimes it really does seem like the open source world is moving
backward, not forward.
Tags: linux, ubuntu, mozilla, firefox, kernel, audio
[
23:24 Jun 28, 2007
More linux |
permalink to this entry |
]
Sun, 27 May 2007
For a
bit
over a year I've been running a patched version of Firefox,
which I call
Kitfox,
as my main browser. I patch it because there are a few really
important features that the old Mozilla suite had which Firefox
removed; for a long time this kept me from using Firefox
(and I'm
not
the only one who feels that way), but when the Mozilla Foundation
stopped supporting the suite and made Firefox the only supported
option, I knew my only choice was to make Firefox do what I needed.
The patches were pretty simple, but they meant that I've been building
my own Firefox all this time.
Since all my changes were in JavaScript code, not C++,
I knew this was probably all achievable with a Firefox extension.
But never around to it;
building the Mozilla source isn't that big a deal to me. I did it as
part of my job for quite a few years, and my desktop machine is fast
enough that it doesn't take that long to update and rebuild, then
copy the result to my laptop.
But when I installed the latest Debian, "Etch", on the laptop, things
got more complicated. It turns out Etch is about a year behind in
its libraries. Programs built on any other system won't run on Etch.
So I'd either have to build Mozilla on my laptop (a daunting prospect,
with builds probably in the 4-hour range) or keep another
system around for the purpose of building software for Etch.
Not worth it. It was time to learn to build an extension.
There are an amazing number of good tutorials on the web for writing
Firefox extensions (I won't even bother to link to any; just google
firefox extension and make your own choices).
They're all organized as step by step examples with sample code.
That's great (my favorite type of tutorial) but it left my real
question unanswered: what can you do in an extension?
The tutorial examples all do simple things like add a new menu or toolbar
button. None of them override existing Javascript, as I needed to do.
Canonical
URL to the rescue.
It's an extension that overrides one of the very behaviors I wanted to
override: that of adding "www." to the beginning and ".com" or ".org"
to the end of whatever's in the URLbar when you ctrl-click.
(The Mozilla suite behaved much more usefully: ctrl-click opened the
URL in a new tab, just like ctrl-clicking on a link. You never need
to add www. and .com or .org explicitly because the URL loading code
will do that for you if the initial name doesn't resolve by itself.)
Canonical URL showed me that all you need to do is make an overlay
containing your new version of the JavaScript method you want to
override. Easy!
So now I have a tiny Kitfox extension
that I can use on the laptop or anywhere else. Whee!
Since extensions are kind of a pain to unpack,
I also made a source tarball which includes a simple Makefile:
kitfox-0.1.tar.gz.
Tags: tech, web, mozilla, firefox, programming
[
11:59 May 27, 2007
More tech/web |
permalink to this entry |
]
Sat, 05 May 2007
For quite some time, I've been seeing all too frequently the dialog
in Firefox which says:
A script on this page may be busy, or it may have stopped
responding. You can stop the script now, or continue to see if the
script will complete.
[Continue] [Stop script]
Googling found lots of pages offering advice on how to increase the
timeout for scripts from the default of 5 seconds to 20 or more
(change the preference dom.max_script_run_time in
about:config. But that seemed wrong. I was seeing the
dialog on lots of pages where other people didn't see it, even
on my desktop machine, which, while it isn't the absolute latest
and greatest in supercomputing, still is plenty fast for basic
web tasks.
The kicker came when I found the latest page that triggers this
dialog: Firefox' own cache viewer. Go to about:cache and
click on "List Cache Entries" under Disk cache device.
After six or seven seconds I got an Unresponsive script dialog
every time. So obviously this wasn't a problem with the web sites
I was visiting.
Someone on #mozillazine pointed me to Mozillazine's page
discussing this dialog, but it's not very useful. For instance,
it includes advice like
To determine what script is running too long, open the Error Console
and tell it to stop the script. The Error Console should identify
the script causing the problem.
Error console? What's that? I have a JavaScript Console, but it
doesn't offer any way to stop scripts. No one on #mozillazine
seemed to have any idea where I might find this elusive Error
console either.
Later Update: turns out this is new with Firefox 2.0.
I've edited the Mozillazine page to say so. Funny that no one on
IRC knew about it.
But there's a long and interesting
MozillaZine discussion of the problem
in which it's clear that it's often caused by extensions
(which the Mozillazine page had also suggested).
I checked the suggested list of Problematic
extensions, but I didn't see anything that looked likely.
So I backed up my Firefox profile and set to work, disabling my
extensions one at a time. First was Adblock, since it appeared
in the Problematic list, but removing it didn't help: I still got
the Unresponsive script when viewing my cache.
The next try was Media Player Connectivity. Bingo! No more
Unresponsive dialog. That was easy.
Media Player Connectivity never worked right for me anyway.
It's supposed to help with pages that offer videos not as a simple
video link, like movie.mpeg or movie.mov or whatever,
but as an embedded object in the page which insists on a
specific browser plug-in
(like Apples's QuickTime or Microsoft's Windows Media Player).
Playing these videos in Firefox is a huge pain in the keister -- you
have to View Source and crawl through the HTML trying to find the URL
for the actual video. Media Player Connectivity is supposed to help
by doing the crawl for you and presenting you with video links
for any embedded video it finds. But it typically doesn't find
anything, and its user interface is so inconsistent and complicated
that it's hard to figure out what it's telling you. It also can't
follow the playlists and .SMIL files that so many sites use now.
So I end up having to crawl through HTML source anyway.
Too bad! Maybe some day someone will find a way to make it easier
to view video on Linux Firefox. But at least I seem to have gotten
rid of those Unresponsive Script errors. That should make for nicer
browsing!
Tags: tech, web, mozilla, firefox
[
13:07 May 05, 2007
More tech/web |
permalink to this entry |
]
Fri, 04 Aug 2006
Every time I click on a mailto link, Firefox wants to bring up
Evolution. That's a fairly reasonable behavior (I'm sure Evolution
is configured as the default mailer somewhere on my system even
though I've never used it) but it's not what I want, since I
have mutt running through a remote connection to another machine
and that's where I'd want to send mail. Dismissing the dialog is
an annoyance that I keep meaning to find a way around.
But I just learned about two excellent solutions:
First: network.protocol-handler.warn-external.mailto
Set this preference to TRUE (either by going to about:config
and searching for mailto, then doubleclicking on the line for
this preference, or by editing the config.js or user.js file
in your firefox profile) and the next time you click on a
mailto link, you'll get a confirmation dialog asking whether
you really want to launch an external mailer.
"Ew! Cancelling a dialog every time is nearly as bad as cancelling
the Evolution launch!" Never fear: this dialog has a
"Don't show me this again" checkbox, so check it and click Cancel
and Firefox will remember. From then on, clicks on mailto links
will be treated as no-ops.
"But wait! It's going to be confusing having links that do
nothing when clicked on. I'm not going to know why that
happened!"
Happily, there's a solution to that, too:
you can set up a custom user style
(in your chrome/userContent.css directory) to show a custom
icon when you mouse over any mailto link. Shiny!
Tags: tech, web, firefox, mozilla
[
21:19 Aug 04, 2006
More tech/web |
permalink to this entry |
]
Mon, 10 Oct 2005
Ever want to look for something in your browser cache, but when you
go there, it's just a mass of oddly named files and you can't figure
out how to find anything?
(Sure, for whole pages you can use the History window, but what if
you just want to find an image you saw this morning
that isn't there any more?)
Here's a handy trick.
First, change directory to your cache directory (e.g.
$HOME/.mozilla/firefox/blahblah/Cache).
Next, list the files of the type you're looking for, in the order in
which they were last modified, and save that list to a file. Like this:
% file `ls -1t` | grep JPEG | sed 's/: .*//' > /tmp/foo
In English:
ls -t lists in order of modification date, and -1 ensures
that the files will be listed one per line. Pass that through
grep for the right pattern (do a file * to see what sorts of
patterns get spit out), then pass that through sed to get rid of
everything but the filename. Save the result to a temporary file.
The temp file now contains the list of cache files of the type you
want, ordered with the most recent first. You can now search through
them to find what you want. For example, I viewed them with Pho:
pho `cat /tmp/foo`
For images, use whatever image viewer you normally use; if you're
looking for text, you can use grep or whatever search you lke.
Alternately, you could
ls -lt `cat foo` to see what was
modified when and cut down your search a bit further, or any
other additional paring you need.
Of course, you don't have to use the temp file at all. I could
have said simply:
pho `ls -1t` | grep JPEG | sed 's/: .*//'`
Making the temp file is merely for your convenience if you think you
might need to do several types of searches before you find what
you're looking for.
Tags: tech, web, mozilla, firefox, pipelines, CLI, shell, regexp
[
22:40 Oct 10, 2005
More tech/web |
permalink to this entry |
]
Tue, 04 Oct 2005
Mozilla Firefox's model has always been to dumb down the basic
app to keep it simple, and require everything else to be implemented as
separately-installed extensions.
There's a lot to be said for this model, but aside from security
(the need to download extensions of questionable parentage from unfamiliar
sites) there's another significant down side: every time you upgrade your
browser, all your extensions become disabled, and it may be months
before they're updated to support the new Firefox version (if indeed
they're ever updated).
When you need extensions for basic functionality, like controlling
cookies, or basic sanity, like blocking flash, the intervening
months of partial functionality can be painful, especially when
there's no reason for it (the plug-in API usually hasn't changed,
merely the version string).
It turns out it's very easy to tweak your installed plug-ins
to run under your current Firefox version.
- Locate your profile directory (e.g. $HOME/firefox/blah.blah
for Firefox on Linux).
- Edit profiledirectory/extensions/*/install.rdf
- Search for maxVersion.
- Update it to your current version (as shown in the
Tools->Extensions dialog).
- Restart the browser.
Disclaimer: Obviously, if the Firefox API really has changed
in a way that makes it incompatible with your installed extensions,
this won't be enough. Your extensions may fail to work, crash your
browser, delete all your files, or cause a massive meteorite to
strike the earth causing global extinction. Consider this a
temporary solution; do check periodically to see if there's a real
extension update available.
More
information on extension versioning (may be out of date).
Tags: tech, web, mozilla, firefox
[
19:47 Oct 04, 2005
More tech/web |
permalink to this entry |
]
Mon, 27 Jun 2005
I spent a little time this afternoon chasing down a couple of recent
Firefox regressions that have been annoying me.
First, the business where, if you type a url into the urlbar and hit
alt-Enter (ctrl-Enter in my Kitfox variant) to open a new tab,
if you go back to the old tab you still see the new url in the
urlbar, which doesn't match the page being displayed there.
That turns out to be bug
227826, which was fixed a week and a half ago. Hooray!
Reading that bug yielded a nice Mozilla tip I hadn't previously
known: hitting ESC when focus is in the urlbar will revert the
urlbar to what it should be, without needing to Reload.
The other annoyance I wanted to chase down is the new failure of
firefox -remote to handle URLs with commas in them (as so
many news stories have these days); quoting the url is no help,
because it no longer handles quotes either. That means that trying
to call a browser from another program such as an IRC client is
doomed to fail for any complex url.
That turns out to be a side effect of the check-in for bug
280725, which had something to do with handling non-ASCII
URLs on Windows. I've filed bug
298960 to cover the regression.
That leaves only one (much more minor) annoyance: the way the
selection color has changed, and quite often seems to give me white
text on a dingy mustard yellow background. I think that's because of
bug
56314, which apparently makes it choose a background color
that's the reverse of the page's background, but which then doesn't
seem to choose a contrasting foreground color.
It turns out you can override this if you don't mind specifying a
single fixed set of selection colors (instead of having them change
with the colors of every page). In userChrome.css (for the urlbar)
and userContent.css (for page content):
::-moz-selection {
background-color: magenta;
color: white;
}
(obviously, pick any pair of colors which strikes your fancy).
Tags: tech, web, mozilla, firefox
[
21:45 Jun 27, 2005
More tech/web |
permalink to this entry |
]
Mon, 17 Jan 2005
Investigating some of the disappointing recent regressions in
Mozilla (in particular in handling links that would open new windows,
bug 278429),
I stumbled upon this useful little tidbit from manko, in the old
bug
78037:
You can use CSS to make your browser give different highlighting
for links that would open in a different window.
Put something like this in your
[moz_profile_dir]/chrome/userContent.css:
a[target="_blank"] {
-moz-outline: 1px dashed invert !important;
/* links to open in new window */
}
a:hover[target="_blank"] {
cursor: crosshair; text-decoration: blink;
color: red; background-color: yellow
!important
}
a[href^="http://"] {
-moz-outline: 1px dashed #FFCC00 !important;
/* links outside from current site */
}
a[href^="http://"][target="_blank"] {
-moz-outline: 1px dashed #FF0000 !important;
/* combination */
}
I questioned the use of outlines rather than colors, but then
realized why manko uses outlines instead: it's better to preserve
the existing colors used by each page, so that link colors go along
with the page's background color.
I tried adding a text-decoration: blink; to the a:hover
style, but it didn't work.
I don't know whether mozilla ignores blink, or if it's being
overridden by the line I already had in userContent.css,
blink { text-decoration: none ! important; }
though I doubt that, since that should apply to the blink tag,
not blink styles on other tags.
In any case, the crosshair cursor should make new-window links
sufficiently obvious, and I expect the blinking (even only on hover)
would have gotten on my nerves before long.
Incidentally, for any web designers reading this (and who isn't,
these days?), links that try to open new browser windows are a
longstanding item on usability guru Jakob Neilsen's Top Ten Mistakes in
Web Design, and he has a good explanation why.
I'm clearly not the only one who hates them.
For a few other mozilla hacks, see
my current userChrome.css
and userContent.css.
Tags: tech, web, mozilla, firefox
[
14:03 Jan 17, 2005
More tech/web |
permalink to this entry |
]
Sat, 07 Aug 2004
The Mozilla Dev Conference yesterday went well. Shaver and Brendan
showed off a new implementation they'd hacked up with Stuart allowing
drawing into a graphics area from JavaScript, modelled after Apple's
Canvas API. The API looked pretty simple from the code snippet they
showed briefly, with commands for line, polygon, fill, and so forth.
It also included full transparency support.
This is all implemented in terms of Cairo.
Someone asked how this compared to SVG. The answer was to think of
Canvas as an image you can change from JS -- simpler than an SVG
document.
Brendan was funny, playing Vanna as Shaver did the brunt of the
talking. "Ooh, that's pretty. What's that?"
Roc then gave a talk on "New Rendering Features for Gecko".
Probably what attracted the most interest there was transparency:
he has a new hack (not yet checked in) where you can add a parameter
to a XUL window to make it transparent. X only supports 1-bit
transparency, but in Windows implementation XUL windows can be
fully transparent.
He began his talk talking about Cairo and about the changed hardware
expectations these days. He stated that everyone has 3D now, or at
least, anyone who doesn't, doesn't care about rendering and doesn't
expect much. I found that rather disturbing, given that I sure
don't want to see rendering stop working well on my laptop, and
I'd hate to see Mozilla ignore education, developing countries and
other markets where open source on cheap hardware is starting to
gain a strong foothold.
The other bothersome thing Roc talked about was high-res displays.
He mentioned people at IBM and other places using 200dpi displays,
which (as anyone who's used even 100dpi and has imperfect vision
knows) leads to tiny text and other display problems on a lot of
pages due to the ubiquity of page designers who use pixel-based
sizing. Roc's answer to this was to have an automatic x2 or x3
zoom for people at high resolutions like 200dpi. This seems to
me a very poor solution: text will either be too big or too small,
and images will be scaled weirdly. Perhaps if it's implemented as
a smart font size scaling, without any mandatory image scaling, it
could be helpful. I wish more work were going into Mozilla's text
scaling, rather than things like automatic 2x zooms. Maybe this
will be part of the work. Guess I need to seek out the bugs and get
involved before I worry too much about right or wrong solutions.
Then AaronL gave his accessibility talk, stressing that
"accessibility helps everybody" and that the minimum everyone should
do is check pages and new XUL objects for keyboard accessibility.
He talked a bit about how screen reading software works, with a demo,
color-blindness issues (don't ever use color as the only cue), and
accessibility problems with the current fad of implementing fake
menus using JS and DHTML (such menus are almost never accessible to
screen reading software, and often can't be triggered with keyboard
events either). Hopefully awareness of these issues will increase
as legislation mandates better accessibility. Aaron's talk was
unfortunately cut short because he was scheduled as the last talk
before lunch; people seemed interested and there was a lot of
information on his slides which got skipped due to time constraints.
After lunch, Nigel spoke on writing XUL applications, Bob Clary
presented an automated site testing tool he'd written (which runs
in Mozilla) to validate HTML, CSS and JS, roc spoke again on the
question of how backwards compatible and quirk-compatible Mozilla
should be, Myk presented his RSS reading addition to Thunderbird
mail, Pav gave a longer demo of the Cairo Canvas, and several
other demos were presented.
Tags: tech, web, mozilla
[
11:30 Aug 07, 2004
More tech/web |
permalink to this entry |
]