Shallow Thoughts : tags : tech
Akkana's Musings on Open Source Computing and Technology, Science, and Nature.
Wed, 26 Mar 2025
Michael Kennedy
asked
whether people are using search engines less because of AI chatbots.
I haven't really gotten into using AI chatbots as coding assistants,
so I'm not one to say. But it did make me wonder how many searches I do.
Michael saw a stat that people average fewer than 300 searches per month;
he thought that was absurdly low until he checked his own stats and
found he'd only made 211 searches so far in March.
(Of course, March isn't over yet.
He didn't give a search number for a complete month.)
Read more ...
Tags: tech, firefox, web, python, google, sqlite
[
16:07 Mar 26, 2025
More tech |
permalink to this entry |
]
Thu, 27 Jul 2023
I don't write a lot of book reviews here, but I just finished a book
I'm enthusiastic about:
Recoding America: Why Government is Failing in the Digital Age
and How We Can Do Better, by Jennifer Pahlka.
Read more ...
Tags: books, programming, tech
[
19:20 Jul 27, 2023
More tech |
permalink to this entry |
]
Sun, 12 Dec 2021
I've spent a lot of the past week battling Russian spammers on
the New Mexico Bill Tracker.
The New Mexico legislature just began a special session to define the
new voting districts, which happens every 10 years after the census.
When new legislative sessions start, the BillTracker usually needs
some hand-holding to make sure it's tracking the new session. (I've
been working on code to make it notice new sessions automatically, but
it's not fully working yet). So when the session started, I checked
the log files...
and found them full of Russian spam.
Specifically, what was happening was that a bot was going to my
new user registration page and creating new accounts where the
username was a paragraph of Cyrillic spam.
Read more ...
Tags: web, tech, spam, programming, python, flask, captcha
[
18:50 Dec 12, 2021
More tech/web |
permalink to this entry |
]
Tue, 08 Dec 2020
Los Alamos (and White Rock) Alert!
Los Alamos and White Rock readers:
please direct your attention to Andy Fraser's
Better Los Alamos Broadband NOW
petition.
One thing the petition doesn't mention is that LANL is bringing a
second high speed trunk line through White Rock. I'm told that They
don't actually need the extra bandwidth, but they want redundancy in
case their main line goes out.
Meanwhile, their employees, and the rest of the town, are struggling
with home internet speeds that aren't even close to the federal definition
of broadband:
Read more ...
Tags: tech, los alamos
[
15:17 Dec 08, 2020
More politics |
permalink to this entry |
]
Fri, 26 Jun 2020
The LWV
Los Alamos is running a Privacy Study, which I'm co-chairing.
As preparation for our second meeting, I gave a Toastmasters talk entitled
"Browser Privacy: Cookies and Tracking and Scripts, Oh My!"
A link to the talk video, a transcript, and lots of extra details
are available on my newly created
Privacy page.
Tags: tech, privacy, speaking
[
08:58 Jun 26, 2020
More tech |
permalink to this entry |
]
Sat, 09 May 2020
Social distancing is hitting some people a lot harder than others.
Of course, there are huge
inequities that are making life harder for a lot of people, even if
they don't know anyone infected with the coronavirus. Distancing is
pointing out long-standing inequalities in living situations (how much
can you distance when you live in an apartment with an elevator, and
get to work on public transit?) and, above all, in internet access.
Here in New Mexico, rural residents, especially on the pueblos and
reservations, often can't get a decently fast internet connection at
any price. I hope that this will eventually lead to a reshaping of how
internet access is sold in the US; but for now, it's a disaster for
students trying to finish their coursework from home, for workers
trying to do their jobs remotely, and for anyone trying to fill out a
census form or an application for relief.
It's a terrible problem,
but that's not really what this article is about. Today I'm writing
about the less tangible aspects of social distancing, and its
implications for introverts and extroverts.
Read more ...
Tags: tech, misc
[
13:57 May 09, 2020
More tech |
permalink to this entry |
]
Thu, 09 Jul 2015
For a year or so, I've been appending "output=classic" to any Google
Maps URL. But Google disabled Classic mode last month.
(There have been
a
few other ways to get classic Google maps back, but Google is gradually
disabling them one by one.)
I have basically three problems with the new maps:
- If you search for something, the screen is taken up by a huge
box showing you what you searched for; if you click the "x" to dismiss
the huge box so you can see the map underneath, the box disappears but
so does the pin showing your search target.
- A big swath at the bottom of the screen is taken up by a filmstrip
of photos from the location, and it's an extra click to dismiss that.
- Moving or zooming the map is very, very slow: it relies on OpenGL
support in the browser, which doesn't work well on Linux in general,
or on a lot of graphics cards on any platform.
Now that I don't have the "classic" option any more, I've had to find
ways around the problems -- either that, or switch to Bing maps.
Here's how to make the maps usable in Firefox.
First, for the slowness: the cure is to disable webgl in Firefox.
Go to about:config and search for webgl.
Then doubleclick on the line for webgl.disabled to make it
true.
For the other two, you can add userContent lines to tell
Firefox to hide those boxes.
Locate your
Firefox profile.
Inside it, edit chrome/userContent.css (create that file
if it doesn't already exist), and add the following two lines:
div#cards { display: none !important; }
div#viewcard { display: none !important; }
Voilà! The boxes that used to hide the map are now invisible.
Of course, that also means you can't use anything inside them; but I
never found them useful for anything anyway.
Tags: web, tech, mapping, GIS, firefox
[
10:54 Jul 09, 2015
More tech/web |
permalink to this entry |
]
Thu, 30 Oct 2014
Today dinner was a bit delayed because I got caught up dealing with an
RSS feed that wasn't feeding. The website was down, and Python's
urllib2, which I use in my
"feedme" RSS fetcher,
has an inordinately long timeout.
That certainly isn't the first time that's happened, but I'd like it
to be the last. So I started to write code to set a shorter timeout,
and realized: how does one test that? Of course, the offending site
was working again by the time I finished eating dinner, went for a
little walk then sat down to code.
I did a lot of web searching, hoping maybe someone had already set up
a web service somewhere that times out for testing timeout code.
No such luck. And discussions of how to set up such a site
always seemed to center around installing elaborate heavyweight Java
server-side packages. Surely there must be an easier way!
How about PHP? A web search for that wasn't helpful either. But I
decided to try the simplest possible approach ... and it worked!
Just put something like this at the beginning of your HTML page
(assuming, of course, your server has PHP enabled):
<?php sleep(500); ?>
Of course, you can adjust that 500 to be any delay you like.
Or you can even make the timeout adjustable, with a
few more lines of code:
<?php
if (isset($_GET['timeout']))
sleep($_GET['timeout']);
else
sleep(500);
?>
Then surf to yourpage.php?timeout=6 and watch the page load
after six seconds.
Simple once I thought of it, but it's still surprising no one
had written it up as a cookbook formula. It certainly is handy.
Now I just need to get some Python timeout-handling code working.
Tags: web, tech, programming, php
[
19:38 Oct 30, 2014
More tech/web |
permalink to this entry |
]
Sun, 07 Sep 2014
I read about cool computer tricks all the time. I think "Wow, that
would be a real timesaver!" And then a week later, when it actually
would save me time, I've long since forgotten all about it.
After yet another session where I wanted to open a frequently opened
file in emacs and thought "I think I made a
bookmark
for that a while back", but then decided it's easier to type the whole
long pathname rather than go re-learn how to use emacs bookmarks,
I finally decided I needed a reminder system -- something that would
poke me and remind me of a few things I want to learn.
I used to keep cheat sheets and quick reference cards on my desk;
but that never worked for me. Quick reference cards tend to be
50 things I already know, 40 things I'll never care about and 4 really
great things I should try to remember. And eventually they get
burned in a pile of other papers on my desk and I never see them again.
My new system is working much better. I created a file in my home
directory called .reminders, in which I put a few -- just a few
-- things I want to learn and start using regularly. It started out
at about 6 lines but now it's grown to 12.
Then I put this in my .zlogin (of course, you can do this for any
shell, not just zsh, though the syntax may vary):
if [[ -f ~/.reminders ]]; then
cat ~/.reminders
fi
Now, in every login shell (which for me is each new terminal window
I create on my desktop), I see my reminders. Of course, I don't read
them every time; but I look at them often enough that I can't forget
the existence of great things like
emacs bookmarks, or
diff <(cmd1) <(cmd2).
And if I forget the exact
keystroke or syntax, I can always cat ~/.reminders to
remind myself. And after a few weeks of regular use, I finally have
internalized some of these tricks, and can remove them from my
.reminders file.
It's not just for tech tips, either; I've used a similar technique
for reminding myself of hard-to-remember vocabulary words when I was
studying Spanish. It could work for anything you want to teach yourself.
Although the details of my .reminders are specific to Linux/Unix and zsh,
of course you could use a similar system on any computer. If you don't
open new terminal windows, you can set a reminder to pop up when you
first log in, or once a day, or whatever is right for you. The
important part is to have a small set of tips that you see regularly.
Tags: linux, cmdline, tech
[
21:10 Sep 07, 2014
More tech |
permalink to this entry |
]
Thu, 27 Mar 2014
Microsoft is in trouble this week -- someone discovered
Microsoft
read a user's Hotmail email as part of an internal leak investigation
(more info here: Microsoft frisked blogger's Hotmail inbox, IM chat to hunt Windows 8 leaker, court told).
And that led The Verge to publish the alarming news that it's not just
Microsoft -- any company that handles your mail can also look at the contents:
"Free email also means someone else is hosting it; they own the
servers, and there's no legal or technical safeguard to keep them from
looking at what's inside."
Well, yeah. That's true of any email system -- not just free webmail like
Hotmail or Gmail.
I was lucky enough to learn that lesson early.
I was a high school student in the midst of college application angst.
The physics department at the local university had generously
given me an account on their Unix PDP-11 since I'd taken a few physics
classes there.
I had just sent off some sort of long, angst-y email message to a friend
at another local college, laying my soul bare,
worrying about my college applications and life choices and who I was going to
be for the rest of my life. You know, all that important earth-shattering
stuff you worry about when you're that age, when you're sure that any
wrong choice will ruin the whole rest of your life forever.
And then, fiddling around on the Unix system after sending my angsty mail,
I had some sort of technical question, something I couldn't figure out
from the man pages, and I sent off a quick question to the same college friend.
A couple of minutes later, I had new mail. From root.
(For non-Unix users, root is the account of the system administrator:
the person in charge of running the computer.) The mail read:
Just ask root. He knows all!
followed by a clear, concise answer to my technical question.
Great!
... except I hadn't asked root. I had asked my friend at a college across town.
When I got the email from root, it shook me up. His response to the
short technical question was just what I needed ... but if he'd read
my question, did it mean he'd also read
the long soul-baring message I'd sent just minutes earlier?
Was he the sort of snoop who spent his time reading all the mail
passing through the system? I wouldn't have thought so, but ...
I didn't ask; I wasn't sure I wanted to know. Lesson learned.
Email isn't private. Root (or maybe anyone else with enough knowledge)
can read your email.
Maybe five years later, I was a systems administrator on a
Sun network, and I found out what must have happened.
Turns out, when you're a sysadmin, sometimes you see things like that
without intending to. Something goes wrong with
the email system, and you're trying to fix it, and there's a spool
directory full of files with randomized names, and you're checking on
which ones are old and which are recent, and what has and hasn't gotten
sent ... and some of those files have content that includes the bodies
of email messages. And sometimes you see part of what's in them.
You're not trying to snoop. You don't sit there and read the full
content of what your users are emailing. (For one thing, you don't
have time, since typically this happens when you're madly trying to
fix a critical email problem.) But sometimes you do see snippets, even
if you're not trying to. I suspect that's probably what happened
when "root" replied to my message.
And, of course, a snoopy and unethical system administrator who really
wanted to invade his users' privacy could easily read everything
passing through the system. I doubt that happened on the college system
where I had an account, and I certainly didn't do it when I was a
sysadmin. But it could happen.
The lesson is that email, if you don't encrypt it, isn't private.
Think of email as being like a postcard. You don't expect Post Office employees
to read what's written on the postcard -- generally they have better
things to do -- but there are dozens of people who handle your postcard
as it gets delivered who could read it if they wanted to.
As the Verge article says,
"Peeking into your clients' inbox is bad form, but it's perfectly legal."
Of course, none of this excuses Microsoft's deliberately reading
Hotmail mailboxes. It is bad form, and amid the outcry
Microsoft
has changed its Hotmail snooping policies somewhat, saying they'll only
snoop deliberately in certain cases).
But the lesson for users is: if you're writing anything private, anything
you don't want other people to read ... don't put it on a postcard.
Or in unencrypted email.
Tags: email, privacy, tech
[
14:59 Mar 27, 2014
More tech/email |
permalink to this entry |
]
Sun, 15 Dec 2013
On way home from a trip last week, one of the hotels we stayed at had
an unexpected bonus:
Hi-Fi Internet!
![[Hi-fi internet]](http://shallowsky.com/blog/images/humor/img_8823-hifi.jpg)
You may wonder, was it mono or stereo?
They had two accesspoints visible (with different essids), so I guess
it was supposed to be stereo. Except one of the accesspoints never worked,
so it turned out to be mono after all.
Tags: humor, travel, tech
[
19:35 Dec 15, 2013
More humor |
permalink to this entry |
]
Sun, 02 Jun 2013
I was pretty surprised at something I saw visiting someone's blog recently.
![[spam that the blog owner didn't see]](http://shallowsky.com/blog/images/screenshots/blogseoT.jpg) The top 2/3 of my browser window was full of spammy text with links to
shady places trying to sell me things like male enhancement pills
and shady high-interest loans.
Only below that was the blog header and content.
(I've edited out identifying details.)
The top 2/3 of my browser window was full of spammy text with links to
shady places trying to sell me things like male enhancement pills
and shady high-interest loans.
Only below that was the blog header and content.
(I've edited out identifying details.)
Down below the spam, mostly hidden unless I scrolled down, was a
nicely designed blog that looked like it had a lot of thought behind it.
It was pretty clear the blog owner had no idea the spam was there.
Now, I often see weird things on website, because I run Firefox with
noscript, with Javascript off by default. Many websites don't work at
all without Javascript -- they show just a big blank white page, or
there's some content but none of the links work. (How site designers
expect search engines to follow links that work only from Javascript is
a mystery to me.)
So I enabled Javascript and reloaded the site. Sure enough: it looked
perfectly fine: no spammy links anywhere.
Pretty clever, eh? Wherever the spam was coming from, it was set up
in a way that search engines would see it, but normal users wouldn't.
Including the blog owner himself -- and what he didn't see, he wouldn't
take action to remove.
Which meant that it was an SEO tactic.
Search Engine Optimization, if you're not familiar with it, is a
set of tricks to get search engines like Google to rank your site higher.
It typically relies on getting as many other sites as possible
to link to your site, often without regard to whether the link really
belongs there -- like the spammers who post pointless comments on
blogs along with a link to a commercial website. Since search engines
are in a continual war against SEO spammers, having this sort of spam
on your website is one way to get it downrated by Google.
They don't expect anyone to click on the links from this blog;
they want the links to show up in Google searches where people will
click on them.
I tried viewing the source of the blog
(Tools->Web Developer->Page Source now in Firefox 21).
I found this (deep breath):
<script language="JavaScript">function xtrackPageview(){var a=0,m,v,t,z,x=new Array('9091968376','9489728787768970908380757689','8786908091808685','7273908683929176', '74838087','89767491','8795','72929186'),l=x.length;while(++a<=l){m=x[l-a]; t=z='';for(v=0;v<m.length;){t+=m.charAt(v++);if(t.length==2){z+=String.fromCharCode(parseInt(t)+33-l);t='';}}x[l-a]=z;}document.write('<'+x[0]+'>.'+x[1]+'{'+x[2]+':'+x[3]+';'+x[4]+':'+x[5]+'(800'+x[6]+','+x[7]+','+x[7]+',800'+x[6]+');}</'+x[0]+'>');} xtrackPageview();</script><div class=wrapper_slider><p>Professionals and has their situations hour payday lenders from Levitra Vs Celais
(long list of additional spammy text and links here)
Quite the obfuscated code! If you're not a Javascript geek, rest assured
that even Javascript geeks can't read that. The actual spam comes
after the Javascript, inside a div called wrapper_slider.
Somehow that Javascript mess must be hiding wrapper_slider from view.
Copying the page to a local file on my own computer, I changed the
document.write to an alert,
and discovered that the Javascript produces this:
<style>.wrapper_slider{position:absolute;clip:rect(800px,auto,auto,800px);}</style>
Indeed, its purpose was to hide the wrapper_slider
containing the actual spam.
Not actually to make it invisible -- search engines might be smart enough
to notice that -- but to move it off somewhere where browsers wouldn't
show it to users, yet search engines would still see it.
I had to look up the arguments to the CSS clip property.
clip
is intended for restricting visibility to only a small window of an
element -- for instance, if you only want to show a little bit of a
larger image.
Those rect arguments are top, right, bottom, and left.
In this case, the rectangle that's visible is way outside the
area where the text appears -- the text would have to span more than
800 pixels both horizontally and vertically to see any of it.
Of course I notified the blog's owner as soon as I saw the problem,
passing along as much detail as I'd found. He looked into it, and
concluded that he'd been hacked. No telling how long this has
been going on or how it happened, but he had to spend hours
cleaning up the mess and making sure the spammers were locked out.
I wasn't able to find much about this on the web. Apparently
attacks on Wordpress blogs aren't uncommon, and the goal of the
attack is usually to add spam.
The most common term I found for it was "blackhat SEO spam injection".
But the few pages I saw all described immediately visible spam.
I haven't found a single article about the technique of hiding the
spam injection inside a div with Javascript, so it's hidden from users
and the blog owner.
I'm puzzled by not being able to find anything. Can this attack
possibly be new? Or am I just searching for the wrong keywords?
Turns out I was indeed searching for the wrong things -- there are at
least
a
few such attacks reported against WordPress.
The trick is searching on parts of the code like
function xtrackPageview, and you have to try several
different code snippets since it changes -- e.g. searching on
wrapper_slider doesn't find anything.
Either way, it's something all site owners should keep in mind.
Whether you have a large website or just a small blog.
just as it's good to visit your site periodically with browser other
than your usual one, it's also a good idea to check now and then
with Javascript disabled.
You might find something you really need to know about.
Tags: spam, tech, web
[
19:59 Jun 02, 2013
More tech/web |
permalink to this entry |
]
Thu, 12 Jan 2012
When I give talks that need slides, I've been using my
Slide
Presentations in HTML and JavaScript for many years.
I uploaded it in 2007 -- then left it there, without many updates.
But meanwhile, I've been giving lots of presentations, tweaking the code,
tweaking the CSS to make it display better. And every now and then I get
reminded that a few other people besides me are using this stuff.
For instance, around a year ago, I gave a talk where nearly all the
slides were just images. Silly to have to make a separate HTML file
to go with each image. Why not just have one file, img.html, that
can show different images? So I wrote some code that lets you go to
a URL like img.html?pix/whizzyphoto.jpg, and it will display
it properly, and the Next and Previous slide links will still work.
Of course, I tweak this software mainly when I have a talk coming up.
I've been working lately on my SCALE talk, coming up on January 22:
Fun
with Linux and Devices (be ready for some fun Arduino demos!)
Sometimes when I overload on talk preparation, I procrastinate
by hacking the software instead of the content of the actual talk.
So I've added some nice changes just in the past few weeks.
For instance, the speaker notes that remind me of where I am in
the talk and what's coming next. I didn't have any way to add notes on
image slides. But I need them on those slides, too -- so I added that.
Then I decided it was silly not to have some sort of automatic
reminder of what the next slide was. Why should I have to
put it in the speaker notes by hand? So that went in too.
And now I've done the less fun part -- collecting it all together and
documenting the new additions. So if you're using my HTML/JS slide
kit -- or if you think you might be interested in something like that
as an alternative to Powerpoint or Libre Office Presenter -- check
out the presentation I have explaining the package, including the
new features.
You can find it here:
Slide
Presentations in HTML and JavaScript
Tags: speaking, javascript, html, web, programming, tech
[
21:08 Jan 12, 2012
More speaking |
permalink to this entry |
]
Tue, 03 Jan 2012
Like most Linux users, I use virtual desktops. Normally my browser
window is on a desktop of its own.
Naturally, it often happens that I encounter a link I'd like to visit
while I'm on a desktop where the browser isn't visible. From some apps,
I can click on the link and have it show up. But sometimes, the link is
just text, and I have to select it, change to the browser desktop,
paste the link into firefox, then change desktops again to do something
else while the link loads.
So I set up a way to load whatever's in the X selection in firefox no
matter what desktop I'm on.
In most browsers, including firefox, you can tell your existing
browser window to open a new link from the command line:
firefox http://example.com/ opens that link in your
existing browser window if you already have one up, rather than
starting another browser. So the trick is to get the text you've selected.
At first, I used a program called xclip. You can run this command:
firefox `xclip -o` to open the selection. That worked
okay at first -- until I hit my first URL in weechat that was so long
that it was wrapped to the next line. It turns out xclip does odd things
with multi-line output; depending on whether it thinks the output is
a terminal or not, it may replace the newline with a space, or delete
whatever follows the newline. In any case, I couldn't find a way to
make it work reliably when pasted into firefox.
After futzing with xclip for a little too long, trying to reverse-engineer
its undocumented newline behavior, I decided it would be easier just to
write my own X clipboard app in Python. I already knew how to do that,
and it's super easy once you know the trick:
mport gtk
primary = gtk.clipboard_get(gtk.gdk.SELECTION_PRIMARY)
if primary.wait_is_text_available() :
print primary.wait_for_text()
That just prints it directly, including any newlines or spaces.
But as long as I was writing my own app, why not handle that too?
It's not entirely necessary on Firefox: on Linux, Firefox has some
special code to deal with pasting multi-line URLs, so you can copy
a URL that spans multiple lines, middleclick in the content area and
things will work. On other platforms, that's disabled, and some Linux
distros disable it as well; you can enable it by going to
about:config and searching for single,
then setting the preference
editor.singlelinepaste.pasteNewlines to 2.
However, it was easy enough to make my Python clipboard app do the
right thing so it would work in any browser. I used Python's re
(regular expressions) module:
#!/usr/bin/env python
import gtk
import re
primary = gtk.clipboard_get(gtk.gdk.SELECTION_PRIMARY)
if not primary.wait_is_text_available() :
sys.exit(0)
s = primary.wait_for_text()
# eliminate newlines, and any spaces immediately following a newline:
print re.sub(r'[\r\n]+ *', '', s)
That seemed to work fine, even on long URLs pasted from weechat
with newlines and spaces, like that looked like
http://example.com/long-
url.html
All that was left was binding it so I could access it from anywhere.
Of course, that varies depending on your desktop/window manager.
In Openbox, I added two items to my desktop menu in menu.xml:
<item label="open selection in Firefox">
<action name="Execute"><execute>sh -c 'firefox `xclip -o`'</execute></action>
</item>
<item label="open selection in new tab">
<action name="Execute"><execute>sh -c 'firefox -new-tab `xclip -o`'</execute></action>
</item>
I also added some code in rc.xml inside
<context name="Desktop">, so I can middle-click
or control-middle-click on the desktop to open a link in the browser:
<mousebind button="Middle" action="Press">
<action name="Execute">
<execute>sh -c 'firefox `pyclip`'</execute>
</action>
</mousebind>
<mousebind button="C-Middle" action="Press">
<action name="Execute">
<execute>sh -c -new-tab 'firefox `pyclip`'</execute>
</action>
</mousebind>
I set this up maybe two hours ago and I've probably used it ten or
fifteen times already. This is something I should have done long ago!
Tags: tech, firefox, linux, cmdline
[
22:37 Jan 03, 2012
More linux |
permalink to this entry |
]
Sat, 24 Sep 2011
I suspect all technical people -- at least those with a web presence
-- get headhunter spam. You know, email saying you're perfect for a
job opportunity at "a large Fortune 500 company" requiring ten years'
experience with technologies you've never used.
Mostly I just delete it. But this one sent me a followup --
I hadn't responded the first time, so surely I hadn't seen it and
here it was again, please respond since I was perfect for it.
Maybe I was just in a pissy mood that night. But
look, I'm a programmer, not a DBA -- I had to look it up to verify
that I knew what DBA stood for. I've never used Oracle.
A "Production DBA with extensive Oracle experience" job is right out,
and there's certainly nothing in my resume that would suggest that's
my line of work.
So I sent a brief reply, asking,
Why do you keep sending this?
Why exactly do you think I'm a DBA or an Oracle expert?
Have you looked at my resume? Do you think spamming people
with jobs completely unrelated to their field will get many
responses or help your credibility?
I didn't expect a reply. But I got one:
I must say my credibility is most important and it's unfortunate
that recruiters are thought of as less than in these regards. And, I know it
is well deserved by many of them.
In fact, Linux and SQL experience is more important than Oracle in this
situation and I got your email address through the Peninsula Linux Users
Group site which is old info and doesn't give any information about its
members' skill or experience. I only used a few addresses to experiment with
to see if their info has any value. Sorry you were one of the test cases but
I don't think this is spamming and apologize for any inconvenience it caused
you.
[name removed], PhD
A courteous reply. But it stunned me.
Harvesting names from old pages on a LUG website, then sending a
rather specific job description out to all the names harvested,
regardless of their skillset -- how could that possibly not be
considered spam? isn't that practically the definition of spam?
And how could a recruiter expect to seem credible after sending this
sort of non-targeted mass solicitation?
To technical recruiters/headhunters: if you're looking for
good technical candidates, it does not help your case to spam people
with jobs that show you haven't read or understood their resume.
All it does is get you a reputation as a spammer. Then if you do, some
day, have a job that's relevant, you'll already have lost all credibility.
Tags: spam, headhunters, tech
[
21:30 Sep 24, 2011
More tech |
permalink to this entry |
]
Tue, 16 Aug 2011
Google has been doing a horrible UI experiment with me recently
involving its search field.
I search for something -- fine, I get a normal search page page.
At the top of the page is a text field with my search terms, like this:
![[normal-looking google search bar]](http://shallowsky.com/blog/images/screenshots/google-searchbar.jpg)
Now suppose I want to modify my search. Suppose I double-click the word
"ui", or drag my mouse across it to select it, perhaps intending to
replace it with something else. Here's what happens:
![[messed up selection in google search bar]](http://shallowsky.com/blog/images/screenshots/google-searchbar-selected.jpg)
Whoops! It highlighted something other than what I clicked, changed the
font size of the highlighted text and moved it. Now I have no idea what
I'm modifying.
This started happening several weeks ago (at about the same time they
made Instant Seach mandatory -- yuck). It only happens on one of my
machines, so I can only assume they're running one of their
little
UI experiments with me, but clearing google cookies (or even banning
cookies from Google) didn't help.
Blacklisting Google from javascript cures it, but then I can't
use Google Maps or other services.
For a week or so, I tried using other search engines. Someone pointed
me to Duck Duck Go, which isn't
bad for general searches. But when it gets to technical searches,
or elaborate searches with OR and - operators, google's search
really is better. Except for, you know, minor details like not being
able to edit your search terms.
But finally it occurred to me to try firebug. Maybe I could find out
why the font size was getting changed. Indeed, a little poking around
with firebug showed a suspicious-looking rule on the search field:
.gsfi, .lst {
font: 17px arial,sans-serif;
}
and disabling that made highlighting work again.
So to fix it permanently, I added the following
to chrome/userContent.css in my Firefox profile directory:
.gsfi, .lst {
font-family: inherit !important;
font-size: inherit !important;
}
And now I can select text again! At least until the next time Google
changes the rule and I have to go back to Firebug to chase it down
all over again.
Note to Google UI testers:
No, it does not make search easier to use to change the font size in
the middle of someone's edits. It just drives the victim away to
try other search engines.
Tags: tech, google, css, web
[
22:05 Aug 16, 2011
More tech/web |
permalink to this entry |
]
Tue, 26 Jul 2011
I've been dying to play with an ebook reader, and this week my mother
got a new Nook Touch. That's not its official name,
but since Barnes & Noble doesn't seem interested in giving it a
model name to tell it apart from the two older Nooks, that's the name
the internet seems to have chosen for this new small model with the
6-inch touchscreen.
Here's a preliminary review, based on a few days of playing with it.
Nice size, nice screen
The Nook Touch feels very light. It's a little heavier than a
paperback, but it's easy to hold, and the rubbery back feels nice in
the hand. The touchscreen works well enough for book reading, though
you wouldn't want to try to play video games or draw pictures on it.
It's very easy to turn pages, either with the hardware buttons on the
bezel or a tap on the edges of the screen. Page changes are
much faster than with older e-ink readers like the original Nook or the
Sony Pocket: the screen still flashes black with each page change,
but only very briefly.
I'd wondered how a non-backlit e-ink display would work in dim light,
since that's one thing you can't test in stores. It turns out it's
not as good as a paper book -- neither as sharp nor as contrasty -- but
still readable with my normal dim bedside lighting.
Changing fonts, line spacing and margins is easy once you figure out
that you need to tap on the screen to get to that menu.
Navigating within a book is also via that tap-on-page menu -- it gives
you a progress meter you can drag, or a "jump to page" option. Which is
a good thing. This is sadly very important (see below).
Searching within books isn't terribly convenient. I wanted to figure
out from the user manual how to set a bookmark, and I couldn't find
anything that looked helpful in the user manual's table of contents,
so I tried searching for "bookmark". The search results don't show much
context, so I had to try them one at a time, and
there's no easy way to go back and try the next match.
(Turns out you set a bookmark by tapping in the upper right corner,
and then the bookmark applies to the next several pages.)
Plan to spend some quality time reading the full-length manual
(provided as a pre-installed ebook, naturally) learning tricks like this:
a lot of the UI isn't very discoverable (though it's simple enough
once you learn it) so you'll miss a lot if you rely on what you can
figure out by tapping around.
Off to a tricky start with minor Wi-fi issues
When we first powered up, we hit a couple of problems right off with
wireless setup.
First, it had no way to set a static IP address. The only way we
could get the Nook connected was to enable DHCP on the router.
But even then it wouldn't connect. We'd re-type the network
password and hit "Connect"; the "Connect" button would flash
a couple of times, leaving an "incorrect password" message at the top
of the screen. This error message never went away, even after going
back to the screen with the list of networks available, so it wasn't
clear whether it was retrying the connection or not.
Finally through trial and error we found the answer: to clear a
failed connection, you have to "Forget" the network and start over.
So go back to the list of wireless networks, choose the right network,
then tap the "Forget" button. Then go back and choose the network
again and proceed to the connect screen.
Connecting to a computer
The Nook Touch doesn't come with much in the way of starter books --
just two public-domain titles, plus its own documentation -- so the
first task was to download a couple of
Project Gutenberg books that
Mom had been reading on her Treo.
The Nook uses a standard micro-USB cable for both charging and its
USB connection. Curiously, it shows up as a USB device with no
partitions -- you have to mount sdb, not sdb1. Gnome handled that
and mounted it without drama. Copying epub books to the Nook was just
a matter of cp or drag-and-drop -- easy.
Getting library books may be moot
One big goal for this device is reading ebooks from the public library,
and I had hoped to report on that.
But it turns out to be a more difficult proposition than expected.
There are all the expected DRM issues to surmount, but before that,
there's the task of finding an ebook that's actually available to
check out, getting the library's online credentials straightened
out, and so forth. So that will be a separate article.
The fatal flaw: forgetting its position
Alas, the review is not all good news. While poking around, reading
a page here and there, I started to notice that I kept getting reset
back to the beginning of a book I'd already started. What was up?
For a while I thought it was my imagination. Surely remembering one's
place in a book you're reading is fundamental to a device designed from
the ground up as a book reader. But no -- it clearly was forgetting
where I'd left off. How could that be?
It turns out this is a known and well reported problem
with what B&N calls "side-loaded" content -- i.e. anything
you load from your computer rather than download from their bookstore.
With side-loaded books, apparently
connecting
the Nook to a PC causes it to lose its place in the book you're
reading! (also discussed
here
and
here).
There's no word from Barnes & Noble about this on any of the threads,
but people writing about it speculate that when the Nook makes a USB
connection, it internally unmounts its filesystems -- and
forgets anything it knew about what was on those filesystems.
I know B&N wants to drive you to their site to buy all your books
... and I know they want to keep you online checking in with their
store at every opportunity. But some people really do read free
books, magazines and other "side loaded" content. An ebook reader
that can't handle that properly isn't much of a reader.
It's too bad. The Nook Touch is a nice little piece of hardware. I love
the size and light weight, the daylight-readable touchscreen, the fast
page flips. Mom is being tolerant about her new toy, since she likes it
otherwise -- "I'll just try to remember what page I was on."
But come on, Barnes & Noble: a dedicated ebook reader
that can't remember where you left off reading your book? Seriously?
Tags: ebook, tech, nook
[
20:46 Jul 26, 2011
More tech |
permalink to this entry |
]
Sun, 24 Apr 2011
I spent Friday and Saturday at the
WhereCamp unconference on mapping,
geolocation and related topics.
This was my second year at WhereCamp. It's always a bit humbling. I
feel like I'm pretty geeky, and I've written a couple of Python
mapping apps and I know spherical geometry and stuff ... but when
I get in a room with the folks at WhereCamp I realize I don't know
anything at all. And it's all so interesting I want to learn all of it!
It's a terrific and energetic unconference.
I
I won't try to write up a full report, but here are some highlights.
Several Grassroots Mapping
people were there again this year.
Jeffrey Warren led people in constructing balloons from tape and mylar
space blankets in the morning, and they shot some aerial photos.
Then in a late-afternoon session he discussed how to stitch the
aerial photos together using
Cargen Knitter.
But he also had other projects to discuss:
the Passenger
Pigeon project to give cameras to people who will
be flying over environmental that need to be monitored -- like New York's
Gowanus Canal superfund site, next to La Guardia airport.
And the new Public Laboratory for Open
Technology and Science has a new project making vegetation maps
by taking aerial photos with two cameras simultaneously, one normal,
one modified for infra-red photography.
How do you make an IR camera? First you have to remove the IR-blocking
filter that all digital cameras come with (CCD sensors are very
sensitive to IR light). Then you need to add a filter that blocks
out most of the visible light. How? Well, it turns out that exposed
photographic film (remember film?) makes a good IR-only filter.
So you go to a camera store, buy a roll of film, rip it out of the
reel while ignoring the screams of the people in the store, then hand
it back to them and ask to have it developed. Cheap and easy.
Even cooler, you can use a similar technique to
make a
spectrometer from a camera, a cardboard box and a broken CD.
Jeffrey showed spectra for several common objects, including bacon
(actually pancetta, it turns out).
| JW: | See the dip in the UV? Pork fat is very absorbent
in the UV. That's why some people use pork products as sunscreen.
|
| Audience member: | Who are these people?
|
| JW: | Well, I read about them on the internet.
|
I ask you, how can you beat a talk like that?
Two Google representatives gave an interesting demo of some of
the new Google APIs related to maps and data visualization, in
particular Fusion
Tables. Motion charts sounded especially interesting
but they didn't have a demo handy; there may be one appearing soon
in the Fusion Charts gallery.
They also showed the new enterprise-oriented
Google Earth Builder, and custom street views for Google Maps.
There were a lot of informal discussion sessions, people brainstorming
and sharing ideas. Some of the most interesting ones I went to included
- Indoor orientation with Android sensors: how do you map an unfamiliar
room using just the sensors in a typical phone? How do you orient
yourself in a room for which you do have a map?
- A discussion of open data and the impending shutdown of data.gov.
How do we ensure open data stays open?
- Using the Twitter API to analyze linguistic changes -- who initiates
new terms and how do they spread? -- or to search for location-based
needs (any good ice cream places near where I am?)
- Techniques of data visualization -- how can we move beyond basic
heat maps and use interactivity to show more information? What works
and what doesn't?
- An ongoing hack session in the scheduling room included folks
working on projects like a system to get information from pilots
to firefighters in real time. It was also a great place to get help
on any map-related programming issues one might have.
- Random amusing factoid that I still need to look up
(aside from the pork and UV one): Automobile tires have RFID in them?
Lightning talks included demonstrations and discussions of
global Twitter activity as the Japanese quake and tsunami
news unfolded, the new CD from OSGeo,
the upcoming PII conference --
that's privacy identity innovation -- in Santa Clara.
There were quite a few outdoor game sessions Friday. I didn't take part
myself since they all relied on having an iPhone or Android phone: my
Archos 5 isn't
reliable enough at picking up distant wi-fi signals to work as an
always-connected device, and the Stanford wi-fi net was very flaky
even with my laptop, with lots of dropped connections.
Even the OpenStreetMap mapping party
was set up to require smartphones, in contrast with past mapping
parties that used Garmin GPS units. Maybe this is ultimately a good thing:
every mapping party I've been to fizzled out after everyone got back
and tried to upload their data and discovered that nobody had
GPSBabel installed, nor the drivers for reading data off a Garmin.
I suspect most mapping party data ended up getting tossed out.
If everybody's uploading their data in realtime with smartphones,
you avoid all that and get a lot more data. But it does limit your
contributors a bit.
There were a couple of lowlights. Parking was very tight, and somewhat
expensive on Friday, and there wasn't any info on the site except
a cheerfully misleading "There's plenty of parking!" And the lunch
schedule on Saturday as a bit of a mess -- no one was sure when the
lunch break was (it wasn't on the schedule), so afternoon schedule had
to be re-done a couple times while everybody worked it out. Still,
those are pretty trivial complaints -- sheesh, it's a free, volunteer
conference! and they even provided free meals, and t-shirts too!
Really, WhereCamp is an astoundingly fun gathering. I always leave
full of inspiration and ideas, and appreciation for the amazing
people and projects presented there. A big thanks to the organizers
and sponsors. I can't wait 'til next year -- and I hope I'll have
something worth presenting then!
Tags: wherecamp, mapping, GIS, tech, openstreetmap
[
23:40 Apr 24, 2011
More mapping |
permalink to this entry |
]
Sun, 27 Mar 2011
Funny thing happened last week.
I'm on the mailing list for a volunteer group. Round about last December,
I started getting emails every few weeks
congratulating me on RSVPing for the annual picnic meeting on October 17.
This being well past October, when the meeting apparently occurred --
and considering I'd never heard of the meeting before,
let alone RSVPed for it --
I couldn't figure out why I kept getting these notices.
After about the third time I got the same notice, I tried replying,
telling them there must be something wrong with their mailer. I never
got a reply, and a few weeks later I got another copy of the message
about the October meeting.
I continued sending replies, getting nothing in return -- until last week,
when I got a nice apologetic note from someone in the organization,
and an explanation of what had happened. And the explanation made me laugh.
Seems their automated email system sends messages as multipart,
both HTML and plaintext. Many user mailers do that; if you haven't
explicitly set it to do otherwise, you yourself are probably sending out
two copies of every mail you send, one in HTML and one in plain text.
But in this automated system, the plaintext part was broken. When it
sent out new messages in HTML format, apparently for the plaintext part
it was always attaching the same old message, this message from October.
Apparently no one in the
organization had ever bothered to check the configuration, or looked
at the plaintext part, to realize it was broken. They probably didn't
even know it was sending out multiple formats.
I have my mailer configured to show me plaintext in preference to HTML.
Even if I didn't use a text mailer (mutt), I'd still use that
setting -- Thunderbird, Apple Mail, Claws and many other mailers
offer it. It protects you from lots of scams and phishing attacks,
"web bugs" to track you,, and people who think it's the height of style
to send mail in blinking yellow comic sans on a red plaid background.
And reading the plaintext messages from this organization, I'd never
noticed that the message had an HTML part, or thought to look at it to
see if it was different.
It's not the first time I've seen automated mailers send multipart
mail with the text part broken. An astronomy club I used to belong to
set up a new website last year, and now all their meeting notices,
which used to come in plaintext over a Yahoo groups mailing list,
have a text part that looks like this actual example from a few days ago:
Subject: Members' Night at the Monthly Meeting
<p><style type="
16;ext/css">@font-face {
font-family: "MS 明朝";
}@font-face {
font-family: "MS 明朝";
}@font-face {
font-family: "Cambria";
}p.MsoNormal, li.MsoNormal, div.MsoNormal { margin: 0in 0in 0.0001pt; font-size:
12pt; font-family: Cambria; }a:link, span.MsoHyperlink { color: blue;
text-decoration: underline; }a:visited, span.MsoHyperlinkFollowed { color:
purple; text-decoration: underline; }.MsoChpDefault { font-family: Cambria;
}div.WordSection1 { page: WordSection1;
}</style>
<p class="MsoNormal">Friday April 8<sup>th</sup> is members’ night at the
monthly meeting of the PAS.<span style="">  </span>We are asking for
anyone, who has astronomical photographs that they would like to share, to
present them at the meeting.<span style="">  </span>Each presenter will
have about 15 minutes to present and discuss his pictures.<span style=""> We
already have some presenters.   </span></p>
<p class="MsoNormal"> </p>
... on and on for pages full of HTML tags and no line breaks.
I contacted the webmaster, but he was just using packaged software and
didn't seem to grok that the software was broken and was sending HTML
for the plaintext part as well as for the HTML part. His response was
fairly typical: "It looks fine to me".
I eventually gave up even trying to read their meeting announcements,
and now I just delete them.
The silly thing about this is that I can read HTML mail just fine, if
they'd just send HTML mail. What causes the problem is these automated
systems that insist on sending both HTML and plaintext, but then the
plaintext part is wrong. You'll see it on a lot of spam, too, where
the plaintext portion says something like "Get a better mailer"
(why? so I can see your phishing attack in all its glory?)
Folks, if you're setting up an automated email system, just pick one format
and send it. Don't configure it to send multiple formats unless you're
willing to test that all the formats actually work.
And developers, if you're writing an automated email system: don't
use MIME multipart/alternative by default unless you're actually sending
the same message in different formats. And if you must use multipart ...
test it. Because your users, the administrators deploying your system
for their organizations, won't know how to.
Tags: tech, email
[
14:19 Mar 27, 2011
More tech/email |
permalink to this entry |
]
Fri, 25 Feb 2011
This week's Linux Planet article continues the Plug Computer series,
with
Cross-compiling
Custom Kernels for Little Linux Plug Computers.
It covers how to find and install a cross-compiler (sadly, your
Linux distro probably doesn't include one), configuring the Linux
kernel build, and a few gotchas and things that I've found not to
work reliably.
It took me a lot of trial and error to figure out some of this --
there are lots of howtos on the web but a lot of them skip the basic
steps, like the syntax for the kernel's CROSS_COMPILE argument --
but you'll need it if you want to enable any unusual drivers like
GPIO. So good luck, and have fun!
Tags: tech, linux, plug, kernel, writing
[
12:30 Feb 25, 2011
More tech |
permalink to this entry |
]
Thu, 10 Feb 2011
This week's Linux Planet article continues my
Plug
Computing part 1 from two weeks ago.
This week, I cover the all-important issue of "unbricking":
what to do when you mess something up and the plug doesn't boot
any more. Which happens quite a lot when you're getting started
with plugs.
Here it is:
Un-Bricking
Linux Plug Computers: uBoot, iBoot, We All Boot for uBoot.
If you want more exhaustive detail, particular on those uBoot scripts and
how they work, I go through some of the details in a brain-dump I wrote
after two weeks of struggling to unbrick my first GuruPlug:
Building
and installing a new kernel for a SheevaPlug.
But don't worry if that page isn't too clear;
I'll cover the kernel-building part more clearly in my next
LinuxPlanet article on Feb. 24.
Tags: tech, linux, plug, uboot, writing
[
10:15 Feb 10, 2011
More tech |
permalink to this entry |
]
Thu, 27 Jan 2011
My article this week on Linux Planet is an introduction to Plug
Computers: tiny Linux-based "wall wart" computers that fit in a
box not much bigger than a typical AC power adaptor.
Although they run standard Linux (usually Debian or Ubuntu),
there are some gotchas to choosing and installing plug computers.
So this week's article starts with the basics of choosing a model
and connecting to it; part II, in two weeks, will address more
difficult issues like how to talk to uBoot, flash a new kernel or
recover if things go wrong.
Read part I here: Tiny
Linux Plug Computers: Wall Wart Linux Servers.
Tags: tech, linux, plug
[
19:36 Jan 27, 2011
More tech |
permalink to this entry |
]
Wed, 05 May 2010
On a Linux list, someone was having trouble with wireless networking,
and someone else said he'd had a similar problem and solved it by
reinstalling Kubuntu from scratch. Another poster then criticised
him for that:
"if
the answer is reinstall, you might as well downgrade to Windows.",
and later added,
"if
"we should understand a problem, and *then* choose a remedy to match."
As someone who spends quite a lot of time trying to track down root
causes of problems so that I can come up with a fix that doesn't
involve reinstalling, I thought that was unfair.
Here is how I replied on the list (or you can go straight to
the
mailing list version):
I'm a big fan of understanding the root cause of a problem and solving it
on that basis. Because I am, I waste many days chasing down problems
that ought to "just work", and probably would "just work" if I
gave in and installed a bone stock Ubuntu Gnome desktop with no
customizations. Modern Linux distros (except maybe Gentoo) are
written with the assumption that you aren't going to change anything
-- so reverting to the original (reinstalling) will often fix a problem.
Understanding this stuff *shouldn't* take days of wasted time -- but
it does, because none of this crap has decent documentation. With a
lot of the underlying processes in Linux -- networking, fonts, sound,
external storage -- there are plenty of "Click on the System Settings
menu, then click on ... here's a screenshot" howtos, but not much
"Then the foo daemon runs the /etc/acpi/bar.sh script, which calls
ifconfig with these arguments". Mostly you have to reverse-engineer
it by running experiments, or read the source code.
Sometimes I wonder why I bother. It may be sort of obsessive-compulsive
disorder, but I guess it's better than washing my hands 'til they bleed,
or hoarding 100 cats. At least I end up with a nice customized system
and more knowledge about how Linux works. And no cat food expenses.
But don't get on someone's case because he doesn't have days to
waste chasing down deep understanding of a system problem. If
you're going to get on someone's case, go after the people who
write these systems and then don't document how they actually work,
so people could debug them.
Tags: linux, tech, documentation
[
19:37 May 05, 2010
More linux |
permalink to this entry |
]
Tue, 01 Dec 2009
"Cookies are small text files which websites place on a visitor's
computer."
I've seen this exact phrase hundreds of times, most recently on a site
that should know better,
The Register.
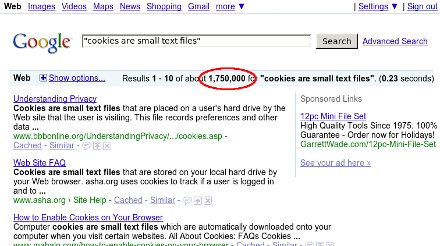
I'm dying to know who started this ridiculous non-explanation,
and why they decided to explain cookies using an implementation
detail from one browser -- at least, I'm guessing IE must implement cookies
using separate small files, or must have done so at one point. Firefox
stores them all in one file, previously a flat file and now an sqlite
database.
How many users who don't know what a cookie is do know what a
"text file" is? No, really, I'm serious. If you're a geek, go ask a few
non-geeks what a text file is and how it differs from other files.
Ask them what they'd use to view or edit a text file.
Hint: if they say "Microsoft Word" or "Open Office",
they don't know.
And what exactly makes a cookie file "text" anyway?
In Firefox, cookies.sqlite is most definitely not a "text file" --
it's full of unprintable characters.
But even if IE stores cookies using printable characters --
have you tried to read your cookies?
I just went and looked at mine, and most of them looked something like this:
Name: __utma
Value: 76673194.4936867407419370000.1243964826.1243871526.1243872726.2
I don't know about you, but I don't spend a lot of time reading text
that looks like that.
Why not skip the implementation details entirely, and just tell users
what cookies are? Users don't care if they're stored in one file or many,
or what character set is used. How about this?
Cookies are small pieces of data which your web browser stores at the
request of certain web sites.
I don't know who started this meme or why people keep copying it
without stopping to think.
But I smell a Fox Terrier. That was Stephen Jay Gould's example,
in his book Bully for Brontosaurus, of a
factoid invented by one writer and blindly copied by all who come later.
The fox terrier -- and no other breed -- was used universally for years to
describe the size of Eohippus. At least it was reasonably close;
Gould went on to describe many more examples where people copied the
wrong information, each successive textbook copying the last with
no one ever going back to the source to check the information.
It's usually a sign that the writer doesn't really understand what
they're writing. Surely copying the phrase everyone else uses must
be safe!
Tags: web, browsers, writing, skepticism, tech, firefox, mozilla
[
21:25 Dec 01, 2009
More tech/web |
permalink to this entry |
]
Sun, 11 Oct 2009
Ah, silence is golden!
For my birthday last month, Dave gave me a nice pair of Bose powered
speakers to replace the crappy broken set I'd been using.
Your basic computer speakers, except I actually use them primarily
for a little portable radio I listen to while hacking.
Only one problem: they had a major hum as soon as I turned them on.
Even when I turned on the radio, I could hear the hum in the
background. It got better if I turned the speakers way down and
the radio up -- it wasn't coming from the radio.
After about a month it was starting to irritate me.
I mentioned it on #linuxchix to see if anyone had any insights.
Maria and Wolf did, and narrowed it down pretty quickly to some sort
of ground problem. The speakers need to get a real ground from somewhere.
They don't get it through their AC power plug (a two-prong wall wart).
They also don't get it from the radio, which is plugged in to AC
via its own 2-prong wall wart, so it doesn't have a ground either.
How could I test this? Wolf suggested an alligator clip going from
one of the RCA plugs on the back of the speaker to my computer's case.
But it turned out there was an easier way. These speakers have dual
inputs: a second set of RCA plugs so I can have another cable going
to an MP3 player, radio or whatever, without needing to unplug
from the radio first. I ran a spare cable from these second RCA plugs
to the sound card output of my spare computer -- bingo!
The hum entirely went away.
I suppose most people buy this type of speaker for use with computers,
so it isn't a problem. But I was surprised that they'd adapt so
poorly to a portable device like a radio or MP3 player. Is that so uncommon?
Tags: tech, audio
[
21:49 Oct 11, 2009
More tech |
permalink to this entry |
]
Tue, 01 Sep 2009
It's so easy as a techie to forget how many people tune out anything
that looks like it has to do with technology.
I've been following the terrible "Station fire" that's threatening
Mt Wilson observatory as well as homes and firefighters' lives
down in southern California. And in addition to all the serious
and useful URLs for tracking the fire, I happened to come across
this one:
http://iscaliforniaonfire.com/
Very funny! I laughed, and so did the friends with whom I shared it.
So when a non-technical mailing list
began talking about the fire, I had to share it, with the comment
"Here's a useful site I found for tracking the status of California fires."
Several people laughed (not all of them computer geeks).
But one person said,
All it said was "YES." No further comments.
The joke seems obvious, right? But think about it: it's only funny
if you read the domain name before you go to the page.
Then you load the page, see what's there, and laugh.
But if you're the sort of person who immediately tunes out when you
see a URL -- because "that's one of those technical things I don't
understand" -- then the page wouldn't make any sense.
I'm not going to stop sharing techie jokes that require some
background -- or at least the ability to read a URL.
But sometimes it's helpful to be reminded of how a lot of the
world looks at things. People see anything that looks "technical" --
be it an equation, a Latin word, or a URL -- and just tune out.
The rest of it might as well not be there -- even if the words
following that "http://" are normal English you think anyone
should understand.
Tags: tech, humor
[
21:48 Sep 01, 2009
More misc |
permalink to this entry |
]
Fri, 12 Jun 2009
My last Toastmasters speech was on open formats: why you should use
open formats rather than closed/proprietary ones and the risks of
closed formats.
To make it clearer, I wanted to print out handouts people could take home
summarizing some of the most common closed formats, along with
open alternatives.
Surely there are lots of such tables on the web, I thought.
I'll just find one and customize it a little for this specific audience.
To my surprise, I couldn't find a single one. Even
openformats.org didn't
have very much.
So I started one:
Open vs. Closed Formats.
It's far from complete, so
I hope I'll continue to get contributions to flesh it out more.
And the talk? It went over very well, and people appreciated the
handout. There's a limit to how much information you can get across
in under ten minutes, but I think I got the point across.
The talk itself, such as it is, is here:
Open up!
Tags: tech, formats, open source, toastmasters
[
11:37 Jun 12, 2009
More tech |
permalink to this entry |
]
Wed, 10 Jun 2009
Lots has been written about
Bing,
Microsoft's new search engine.
It's better than Google, it's worse than Google, it'll never catch
up to Google. Farhad Manjoo of Slate had perhaps the best reason
to use Bing:
"If you switch,
Google's going to do some awesome things to try to win you back."
![[Bing in Omniweb thinks we're in Portugal]](http://shallowsky.com/blog/images/screenshots/omnigalT.jpg) But what I want to know about Bing is this:
Why does it think we're in Portugal when Dave runs it under Omniweb on Mac?
But what I want to know about Bing is this:
Why does it think we're in Portugal when Dave runs it under Omniweb on Mac?
In every other browser it gives the screen you've probably seen,
with side menus (and a horizontal scrollbar if your window isn't
wide enough, ugh) and some sort of pretty picture as a background.
In Omniweb, you get a cleaner layout with no sidebars or horizontal
scrollbars, a different pretty picture -- often
prettier than the one you get on all the other browsers, though
both images change daily -- and a set of togglebuttons that don't
show up in any of the other browsers, letting you restrict results
to only English or only results from Portugal.
Why does it think we're in Portugal when Dave uses Omniweb?
Equally puzzling, why do only people in Portugal have the option
of restricting the results to English only?
Tags: tech, browsers, mapping, geolocation, GIS
[
10:37 Jun 10, 2009
More tech |
permalink to this entry |
]
Sat, 15 Nov 2008
Dave and I recently acquired a lovely trinket from a Mac-using friend:
an old 20-inch Apple Cinema Display.
I know what you're thinking (if you're not a Mac user): surely
Akkana's not lustful of Apple's vastly overpriced monitors when
brand-new monitors that size are selling for under $200!
Indeed, I thought that until fairly recently. But there actually
is a reason the Apple Cinema displays cost so much more than seemingly
equivalent monitors -- and it's not the color and shape of the bezel.
The difference is that Apple cinema displays are a technology called
S-IPS, while normal consumer LCD monitors -- those ones you
see at Fry's going for around $200 for a 22-inch 1680x1050 -- are
a technology called TN. (There's a third technology in between the
two called S-PVA, but it's rare.)
The main differences are color range and viewing angle.
The TN monitors can't display full color: they're only
6 bits per channel. They simulate colors outside that range
by cycling very rapidly between two similar colors
(this is called "dithering" but it's not the usual use of the term).
Modern TN monitors are
astoundingly fast, so they can do this dithering faster than
the eye can follow, but many people say they can still see the
color difference. S-IPS monitors show a true 8 bits per color channel.
The viewing angle difference is much easier to see. The published
numbers are similar, something like 160 degrees for TN monitors versus
180 degrees for S-IPS, but that doesn't begin to tell the story.
Align yourself in front of a TN monitor, so the colors look right.
Now stand up, if you're sitting down, or squat down if you're
standing. See how the image suddenly goes all inverse-video,
like a photographic negative only worse? Try that with an S-IPS monitor,
and no matter where you stand, all that happens is that the image
gets a little less bright.
(For those wanting more background, read
TN Film, MVA,
PVA and IPS – Which one's for you?, the articles on
TFT Central,
and the wikipedia
article on LCD technology.)
Now, the comparison isn't entirely one-sided. TN monitors have their
advantages too. They're outrageously inexpensive. They're blindingly
fast -- gamers like them because they don't leave "ghosts" behind
fast-moving images. And they're very power efficient (S-IPS monitors,
are only a little better than a CRT). But clearly, if you spend a lot
of time editing photos and an S-IPS monitor falls into your
possession, it's worth at least trying out.
But how? The old Apple Cinema display has a nonstandard connector,
called ADC, which provides video, power and USB1 all at once.
It turns out the only adaptor from a PC video card with DVI output
(forget about using an older card that supports only VGA) to an ADC
monitor is the $99 adaptor from the Apple store. It comes with a power
brick and USB plug.
Okay, that's a lot for an adaptor, but it's the only game in town,
so off I went to the Apple store, and a very short time later I had
the monitor plugged in to my machine and showing an image. (On Ubuntu
Hardy, simply removing xorg.conf was all I needed, and X automatically
detected the correct resolution. But eventually I put back one section
from my old xorg.conf, the keyboard section that specifies
"XkbOptions" to be "ctrl:nocaps".)
And oh, the image was beautiful. So sharp, clear, bright and colorful.
And I got it working so easily!
Of course, things weren't as good as they seemed (they never are, with
computers, are they?) Over the next few days I collected a list of
things that weren't working quite right:
- The Apple display had no brightness/contrast controls; I got
a pretty bad headache the first day sitting in front of that
full-brightness screen.
- Suspend didn't work. And here when I'd made so much progress
getting suspend to work on my desktop machine!
- While X worked great, the text console didn't.
The brightness problem was the easiest. A little web searching led me
to acdcontrol, a
commandline program to control brightness on Apple monitors.
It turns out that it works via the USB plug of the ADC connector,
which I initially hadn't connected (having not much use for another
USB 1.1 hub). Naturally, Ubuntu's udev/hal setup created the device
in a nonstandard place and with permissions that only worked for root,
so I had to figure out that I needed to edit
/etc/udev/rules.d/20-names.rules and change the hiddev line to read:
KERNEL=="hiddev[0-9]*", NAME="usb/%k", GROUP="video", MODE="0660"
That did the trick, and after that acdcontrol worked beautifully.
On the second problem, I never did figure out why suspending with
the Apple monitor always locked up the machine, either during suspend
or resume. I guess I could live without suspend on a desktop, though I
sure like having it.
The third problem was the killer. Big deal, who needs text consoles,
right? Well, I use them for debugging, but what was more important,
also broken were the grub screen (I could no longer choose
kernels or boot options) and the BIOS screen (not something
I need very often, but when you need it you really need it).
In fact, the text console itself wasn't a problem. It turns out the
problem is that the Apple display won't take a 640x480 signal.
I tried building a kernel with framebuffer enabled, and indeed,
that gave me back my boot messages and text consoles (at 1280x1024),
but still no grub or BIOS screens. It might be possible to hack a grub
that could display at 1280x1024. But never being able to change BIOS
parameters would be a drag.
The problems were mounting up. Some had solutions; some required
further hacking; some didn't have solutions at all. Was this monitor
worth the hassle? But the display was so beautiful ...
That was when Dave discovered TFT
Central's search page -- and we learned that the Dell 2005FPW
uses the exact same Philips tube as the
Apple, and there are lots of them for sale used,.
That sealed it -- Dave took the Apple monitor (he has a Mac, though
he'll need a solution for his Linux box too) and I bought a Dell.
Its image is just as beautiful as the Apple (and the bezel is nicer)
and it works with DVI or VGA, works at resolutions down to 640x480
and even has a powered speaker bar attached.
Maybe it's possible to make an old Apple Cinema display work on a Mac.
But it's way too much work. On a PC, the Dell is a much better bet.
Tags: linux, tech, graphics, monitor, S-IPS, TN, ADC, DVI
[
21:57 Nov 15, 2008
More tech |
permalink to this entry |
]
Wed, 08 Oct 2008
Dear Asus, and other manufacturers who make Eee imitations:
The Eee laptops are mondo cool. So lovely and light.
Thank you, Asus, for showing that it can be done and that there's
lots of interest in small, light, cheap laptops, thus inspiring
a bazillion imitators. And thank you even more for offering
Linux as a viable option!
Now would one of you please, please offer some models that
have at least XGA resolution so I can actually buy one? Some of us
who travel with a laptop do so in order to make presentations.
On projectors that use 1024x768.
So far HP is the only manufacturer to offer WXGA, in the Mini-Note.
But I read that Linux support is poor for the "Chrome 9" graphics
chip, and reviewers seem very underwhelmed with the Via C7
processor's performance and battery life.
Rumours of a new Mini-Note with a Via Nano or, preferably, Intel
Atom and Intel graphics chip, keep me waiting.
C'mon, won't somebody else step up and give HP some competition?
It's so weird to have my choice of about 8 different 1024x600
netbook models under $500, but if I want another 168 pixels
vertically, the price from everyone except HP jumps to over $2000.
Folks: there is a marketing niche here that you're missing.
Tags: tech, netbook, laptop, resolution, projector
[
22:50 Oct 08, 2008
More tech |
permalink to this entry |
]
Sun, 28 Sep 2008
An interesting occurrence at a Toastmasters meeting last week
offered a lesson in the difficulties of writing or speaking
about technology.
The member who was running Table Topics had an interesting project
planned: "Bookmarks". I thought, things you put in books to mark your
place? Then I saw the three-page printout he had brought and realized
that, duh, of course, he means browser bookmarks.
The task, he explained, was to scan his eclectic list of bookmarks,
pick three, and tell a story about them.
Members reacted with confusion. Several of them said they didn't
understand what he meant at all. Would he give an example? So
he chose three and gave a short demonstration speech. But the members
still looked confused. He said if they wanted to pick just one, that
would be okay. Nobody looked relieved.
We did a couple rounds. I gave a rambling tale that incorporated
three or four bookmarks. One of our newer members took the list,
and wove a spirited story that used at least five (she eventually won
the day's Best Table Topic ribbon). Then the bookmark list passed to
one of the members who had expressed confusion.
She stared at the list, obviously baffled.
"I still don't understand. What do they have to do with bookmarks?"
"Browser bookmarks," I clarified, and a couple of other
people chimed in on that theme, but it obviously wasn't helping.
Several other members crowded around to get a look at the list.
Brows furrowed. Voices murmured. Then one of them looked up.
"Are these like ... Favorites?"
There was a immediate chorus of "Favorites?" "Oh, like in an Explorer
window?" "You mean like on the Internet?" "Ohhh, I think I get it ..."
Things improved from there.
I don't think the member who presented this project had any idea
that a lot of people wouldn't understand the term "Bookmark", as it
applies to a list of commonly-visited sites in a browser. Nor did I.
I was momentarily confused thinking me meant the other kind of
bookmark (the original kind, for paper books), but realizing that
he meant browser bookmarks cleared it right up for me.
A bigger surprise to me was that
the word "browser" wasn't any help to half the membership --
none of them understood what a "browser" was any more than they knew
what a "bookmark" was. "Like in an Explorer window?" or "on the internet"
was the closest they got to the concept that they were running a
specific program called a web browser.
These aren't stupid people;
they just don't use computers much, and haven't ever learned the
terminology for some of the programs they use or the actions they take.
When you're still learning something, you fumble around, sometimes
getting where you need to go be accident; you don't always know
how you got there, much less the terms describing the steps you took.
Even if you're an übergeek, I'm sure you have programs where
you fumble about and aren't quite sure how you get from A to B.
You may sometimes be surprised at meeting people who still use
Internet Explorer and haven't tried Firefox, let alone Opera.
You may wonder if it's the difficulty of downloading and installing
software that stops them.
But the truth may be that questions like "Have you tried Firefox?"
don't really mean anything to a lot of people; they're not really
aware that they're using Internet Explorer in the first place.
It's just a window they've managed to open to show stuff
on the internet.
Avoiding technical jargon is sometimes harder than you think.
Seemingly basic concepts are not so basic as they seem; terms you
think are universal turn out not to be. You have to be careful with
terminology if you to be understood ... and probably the only way
to know for sure if you're using jargon is to try out your language
on an assortment of people.
Tags: tech, browsers, writing, muggles
[
12:23 Sep 28, 2008
More tech |
permalink to this entry |
]
Tue, 05 Aug 2008
The tech press is in a buzz about the new search company,
Cuil (pronounced "cool").
Most people don't like it much, but are using it as an excuse
to rhapsodize about Google and why they took such
a commanding lead in the search market, PageRank and huge
data centers and all those other good things Google has.
Not to run down PageRank or other Google inventions -- Google
does an excellent job at search these days (sometimes spam-SEO sites
get ahead of them, but so far they've always caught up) -- but that's
not how I remember it. Google's victory over other search engines
was a lot simpler and more basic than that. What did they bring?
Logical AND.
Most of you have probably forgotten it since we take Google so for
granted now, but back in the bad old days when search engines were
just getting started, they all did it the wrong way. If you searched
for red fish, pretty much all the early search engines would
give you all the pages that had either red or fish
anywhere in them. The more words you added, the less likely you
were to find anything that was remotely related to what you wanted.
Google was the first search engine that realized the simple fact
(obvious to all of us who were out there actually doing
searches) that what people want when they search for multiple words
is only the pages that have all the words -- the pages that
have both red and fish. It was the search
engine where it actually made sense to search for more than one word,
the first where you could realistically narrow down your search to
something fairly specific.
Even today, most site searches don't do this right. Try searching for
several keywords on your local college's web site, or on a retail site
that doesn't license Google (or Yahoo or other major search engine)
technology.
Logical and. The killer boolean for search engines.
(I should mention that Dave, when he heard this, shook his
head. "No. Google took over because it was the first engine that just
gave you simple text that you could read, without spinning blinking
images and tons of other crap cluttering up the page."
He has a point -- that was certainly
another big improvement Google brought, which hardly anybody else
seems to have realized even now. Commercial sites get more and more
cluttered, and
nobody notices that Google, the industry leader, eschews all that crap
and sticks with simplicity. I don't agree that's why they won, but
it would be an excellent reason to stick with Google even if their search
results weren't the best.)
So what about Cuil? I finally got around to trying it this morning,
starting with a little "vanity google" for my name.
The results were fairly reasonable, though oddly slanted toward
TAC, a local astronomy group
in which I was fairly active around ten years ago
(three hits out of the first ten are TAC!)
Dave then started typing colors into Cuil to see what he would get,
and found some disturbing results. He has Firefox' cookie preference
set to "Ask me before setting a cookie" -- and it looks like Cuil loads
pages in the background, setting cookies galore for sites you haven't
ever seen or even asked to see. For every search term he thought of,
Cuil popped up a cookie request dialog while he was still typing.
Searching for blu wanted to set a cookie for bluefish.something.
Searching for gre wanted to set a cookie for www.gre.ac.uk.
Searching for yel wanted to set a cookie for www.myyellow.com.
Searching for pra wanted to set a cookie for www.pvamu.edu.
Pretty creepy, especially when combined with Cuil's propensity
(noted by every review I've seen so far, and it's true here too)
for including porn and spam sites. We only noticed this because he
happened to have the "Ask me" pref set. Most people wouldn't even know.
Use Cuil and you may end up with a lot of cookies set from sites
you've never even seen, sites you wouldn't want to be associated
with. Better hope no investigators come crawling through your
browser profile any time soon.
Tags: tech, search, privacy
[
11:10 Aug 05, 2008
More tech |
permalink to this entry |
]
Tue, 08 Apr 2008
A friend pointed me to a story she'd written. It was online as a .txt
file. Unfortunately, it had no line breaks, and Firefox presented it
with a horizontal scrollbar and no option to wrap the text to fit in
the browser window.
But I was sure that was a long-solved problem -- surely there must
be a userContent.css rule or a bookmarklet to handle text with long
lines. The trick was to come up with the right Google query.
Like this one:
firefox OR mozilla wrap text userContent OR bookmarklet
I settled on the simple CSS rule from Tero Karvinen's page on
Making
preformated <pre> text wrap in CSS3, Mozilla, Opera and IE:
pre {
white-space: -moz-pre-wrap !important;
}
Add it to
chrome/userContent.css and you're done.
But some people might prefer not to apply the rule to all text.
If you'd prefer a rule that can be applied at will, a bookmarklet
would be better. Like the
word
wrap bookmarklet from Return of the Sasquatch
or the one from Jesse Ruderman's
Bookmarklets
for Zapping Annoyances collection.
Tags: tech, web, mozilla, firefox, css, bookmarklets
[
11:47 Apr 08, 2008
More tech/web |
permalink to this entry |
]
Wed, 24 Oct 2007
I just got back from
She's Geeky.
What a rush! It'll take me a while to wind down from this fabulous
all-women meeting.
I have to admit, I was initially dubious. A conference for geeky women
sounded great, but it struck me as kind of
expensive -- $175 (with a $125 early-bird rate). That's very cheap
as tech conferences go, but for a two-day "unconference", it was
enough to turn off most local techie women I know: nearly all of them
knew about She's Geeky and said "I'd love to go but I can't afford
it." Full disclosure: I said the same thing, and wouldn't have gone
myself had I not gotten a "scholarship", for which I am immensely grateful.
(In retrospect, considering how well run it was, it probably
would have been worth the early-bird price. But that's not easy
to tell ahead of time.)
Monday consisted of lunch and informal discussion followed by
two sessions of scheduled talks. I particularly liked the afternoon
schedule, which included two different sessions of speaker training:
the theory being that one factor holding women back in technology
jobs is that we don't make ourselves visible by public speaking
as much as we could. I went to the "Lightening (sic) Talks" session,
headed by Danese Cooper. It didn't make me lighter, but we got some
great advice at giving conference talks (lightning and otherwise)
plus two rounds of practice at three minute talks.
I'm not sure what I enjoyed more, the practice and useful feedback or
the chance to listen to so many great short talks on disparate and
interesting subjects.
Tuesday started way before normal geek time, with bagels and espresso
and an explanation by conference organizer Kaliya Hamlin on how we'd
use the Open Space process.
Sessions would be an hour long, and we had eight rooms to work with,
all charted on a huge grid on the wall. Anyone could run a session
(or several). Write it (and your name) on a card, get up and tell the
group about it, then find a time and space for it and tape it on
the grid. Rules for sessions were few.
For session leaders, Whoever comes to your session is the right
audience, and whatever happens is what should have happened.
For people attending a session there's the Rule of Two Feet:
if you're not getting anything out of the session you're in,
you should get up and get yourself to somewhere where
you're contributing and/or learning. Not hard when there are seven
other sessions to choose from.
This all worked exactly as described. Whatever hesitance many
women may feel toward public speaking, there was no lack of volunteer
session leaders on a wide variety of topics, both technical and social.
I signed up to give a GIMP session before lunch; then in a morning
session on server and firewall configuration given by fellow
LinuxChix Gloria W. and Gaba,
I noticed a few people having a lot of general Linux questions,
in particular command-line questions, so I ran back to the wall
grid and added an afternoon session on "Understanding the Linux
command line".
Easily my favorite session of the conference was the Google Maps API
talk by Pamela Fox of Google. I've been meaning to experiment
with Google Maps and KML for a long time. I even have books on it
sitting on my shelf. But I never seem to get over the hump: find a
project and a specific task, then go
RTFM
and figure out how to write
a KML file from scratch to do something fun and useful. Pamela got
me over that in a hurry -- she showed us the "My Maps" tab in
Google Maps (you have to be signed on to a Google account to use
it). It includes tools for generating some starter KML
interactively, and it even has a polygon editor, all implemented
in AJAX (Javascript) and running in a browser. Wow! What a great
way to get a running start on map mashups. There's also a whole open
source Javascript API and set of libraries for writing creative web
mapping apps. I'm sure I'll be experimenting with this a lot more
and writing about it separately. Just this talk alone made the
conference worthwhile, even without all the other great sessions.
But I didn't get a chance to experiment right away with any of
that cool mapping stuff, because right after that session was
one by speaker and comedian Heather
Gold. Heather had given Saturday night's evening entertainment,
and I am very sorry to have had to miss the show to go to a night class.
The session was on self confidence, getting over fear of speaking,
and connecting with the audience. Since the allotted space was noisy
(the same one I'd ended up with for my GIMP talk, and the noise was
definitely a problem), Heather led our small group out onto the
balcony to enjoy the warm weather. The group was diverse and included
women at very different levels of speaking, but Heather had great tips
for all of us. She has great presence and a lot of useful things to
say, and she's funny -- I'd love to see her on stage.
Everybody had a really positive attitude.
At the Lightning Talks session on Saturday, Danese stressed
"No whinging" as a general rule to follow (in talks or anywhere else),
and I'd say the whole conference followed it.
While we heard about lots of serious topics women face, I
didn't hear any whining or "men are keeping us down" or that sort
of negativism. There were some bad experiences shared as well as good
ones, but the point was in finding solutions and making progress, not
dwelling on problems. This was a group of women doing things.
There are only two changes I can think of that could have improved the
conference at all.
First, I already mentioned the cost. While it was fair
considering the fantastic organization, great people, plus catered
meals, it still lets out some of the women who could have benefitted the
most: students and the un- and under-employed. A few of us LinuxChix
talked about how much we'd love to see a similar conference held at
a cheaper facility, without the handouts or the catered meals.
Maybe some day we'll be able to make it happen.
Second (and this is a very minor point), it might have been helpful
to have runners reminding people when sessions were ending, and
perhaps making the sessions 55 minutes instead of an hour to encourage
getting to the next session and starting on promptly.
Even without that, people mostly stuck to the schedule and Tuesday
finished right on time: pretty amazing for a conference whose agenda
had been made that morning with cardboard, tape and marking pens.
I've seen unconferences before, and they're usually a disorganized mess.
This one ran better than most scheduled conferences. Kaliya and her
fellow organizers clearly know how to make this process work.
We all pitched in to clean up the room, and I braved the rush-hour
freeway.
And arrived home to find that my husband had cooked dinner and it
was just about ready.
What a nice ending to the day!
Tags: conferences, tech, chix, speaking
[
00:01 Oct 24, 2007
More misc |
permalink to this entry |
]
Sat, 20 Oct 2007
I remember a few years ago the Mozilla folks were making a lot of
noise about the "blazingly fast Back/Forward" that was coming up
in the (then) next version of Firefox. The idea was that the layout
engine was going to remember how the page was laid out (technically,
there would be a "frame cache" as opposed to the normal cache which
only remembers the HTML of the page). So when you click the Back
button, Firefox would remember everything it knew about that page --
it wouldn't have to parse the HTML again or figure out how to lay
out all those tables and images, it would just instantly display
what the page looked like last time.
Time passed ... and Back/Forward didn't get faster. In fact, they
got a lot slower. The "Blazingly Fast Back" code did get checked in
(here's
how to enable it)
but somehow it never seemed to make any difference.
The problem, it turns out, is that the landing of
bug
101832 added code to respect a couple of HTTP Cache-Control header
settings, no-store and no-cache. There's also a
third cache control header, must-revalidate, which is similar
(the difference among the three settings is fairly subtle, and
Firefox seems to treat them pretty much the same way).
Translated, that means that web servers, when they send you a page,
can send some information along with the page that asks the browser
"Please don't keep a local copy of this page -- any time you want
it again, go back to the web and get a new copy."
There are pages for which this makes sense. Consider a secure bank
site. You log in, you do your banking, you view your balance and other
details, you log out and go to lunch ... then someone else comes by
and clicks Back on your browser and can now see all those bank
pages you were just viewing. That's why banks like to set no-cache
headers.
But those are secure pages (https, not http). There are probably
reasons for some non-secure pages to use no-cache or no-store
... um ... I can't think of any offhand, but I'm sure there are some.
But for most pages it's just silly. If I click Back, why wouldn't I
want to go back to the exact same page I was just looking at?
Why would I want to wait for it to reload everything from the server?
The problem is that modern Content Management Systems (CMSes) almost
always set one or more of these headers. Consider the
Linux.conf.au site.
Linx.conf.au is one of the most clueful, geeky conferences around.
Yet the software running their site sets
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Pragma: no-cache
on every page. I'm sure this isn't intentional -- it makes no sense for
a bunch of basically static pages showing information about a
conference several months away. Drupal, the CMS used by
LinuxChix sets
Cache-Control: must-revalidate -- again, pointless.
All it does is make you afraid to click on links because then
if you want to go Back it'll take forever. (I asked some Drupal
folks about this and they said it could be changed with
drupal_set_header).
(By the way, you can check the http headers on any page with:
wget -S -O /dev/null http://... or, if you have curl,
curl --head http://...)
Here's an excellent summary of the options in an
Opera developer's
blog, explaining why the way Firefox handle caching is not only
unfriendly to the user, but also wrong according to the specs.
(Darn it, reading sensible articles like that make me wish I wasn't
so deeply invested in Mozilla technology -- Opera cares so much
more about the user experience.)
But, short of a switch to Opera, how could I fix it on my end?
Google wasn't any help, but I figured that this must be a reported
Mozilla bug, so I turned to Bugzilla and found quite a lot.
Here's the scoop. First, the code to respect the cache settings
(slowing down Back/Forward) was apparently added in response to bug 101832.
People quickly noticed the performance problem, and filed
112564.
(This was back in late 2001.) There was a long debate,
but in the end, a fix was checked in which allowed no-cache http
(non-secure) sites to cache and get a fast Back/Forward.
This didn't help no-store and must-revalidate sites, which
were still just as slow as ever.
Then a few months later,
bug
135289 changed this code around quite a bit. I'm still getting
my head around the code involved in the two bugs, but I think this
update didn't change the basic rules governing which
pages get revalidated.
(Warning: geekage alert for next two paragraphs.
Use this fix at your own risk, etc.)
Unfortunately, it looks like the only way to fix this is in the
C++ code. For folks not afraid of building Firefox, the code lives in
nsDocShell::ShouldDiscardLayoutState and controls the no-cache and
no-store directives. In nsDocShell::ShouldDiscardLayoutState
(currently lie 8224, but don't count on it), the final line is:
return (noStore || (noCache && securityInfo));
Change that to
return ((noStore || noCache) && securityInfo);
and Back/Forward will get instantly faster, while still preserving
security for https. (If you don't care about that security issue
and want pages to cache no matter what, just replace the whole
function with
return PR_FALSE; )
The must-validate setting is handled in a completely different
place, in nsHttpChannel.
However, for some reason, fixing nsDocShell also fixes Drupal pages
which set only must-validate. I don't quite understand why yet.
More study required.
(End geekage.)
Any Mozilla folks are welcome to tell me why I shouldn't be doing
this, or if there's a better way (especially if it's possible in a
way that would work from an extension or preference).
I'd also be interested in from Drupal or other CMS folks defending why
so many CMSes destroy the user experience like this. But please first
read the Opera article referenced above, so that you understand why I
and so many other users have complained about it. I'm happy to share
any comments I receive (let me know if you want your comments to
be public or not).
Tags: tech, web, mozilla, firefox, performance
[
20:32 Oct 20, 2007
More tech/web |
permalink to this entry |
]
Wed, 04 Jul 2007
I like buying from Amazon, but it's gotten a lot more difficult since
they changed their web page design to assume super-wide browser
windows. On the browser sizes I tend to use, even if I scroll right
I can't read the reviews of books, because the content itself is wider
than my browser window. Really, what's up with the current craze of
insisting that everyone upgrade their screen sizes then run browser
windows maximized?
(I'd give a lot for a browser that had the concept of "just show me
the page in the space I have". Opera has made some progress on this
and if they got it really working it might even entice me away from
Firefox, despite my preference for open source and my investment in
Mozilla technology ... but so far it isn't better enough to justify a
switch.)
I keep meaning to try the
greasemonkey extension,
but still haven't gotten around to it.
Today, I had a little time, so I googled to see if
anyone had already written a greasemonkey script to make Amazon readable.
I couldn't find one, but I did find a
page
from last October trying to fix a similar problem on another
website, which mentioned difficulties in keeping scripts working
under greasemonkey, and offered a Javascript bookmarklet with
similar functionality.
Now we're talking! A bookmarklet sounds a lot simpler and more secure
than learning how to program Greasemonkey. So I grabbed the
bookmarklet, a copy of an Amazon page, and my trusty DOM Inspector
window and set about figuring out how to make Amazon fit in my window.
It didn't take long to realize that what I needed was CSS, not
Javascript. Which is potentially a lot easier: "all" I needed to do
was find the right CSS rules to put in userContent.css. "All" is in
quotes because getting CSS to do anything is seldom a trivial task.
But after way too much fiddling, I did finally come up with a rule
to get Amazon's Editorial Reviews to fit. Put this in
chrome/userContent.css inside your Firefox profile directory
(if you don't know where your profile directory is, search your disk
for a file called prefs.js):
div#productDescription div.content { max-width: 90% !important; }
You can replace that 90% with a pixel measurement, like 770px,
or with a different percentage.
I spent quite a long time trying to get the user reviews (a table with
two columns) to fit as well, without success. I was trying things like:
#customerReviews > div.content > table > tbody > tr > td { max-width: 300px; min-width: 10px !important; }
div#customerReviews > div.content > table { margin-right: 110px !important; }
but nothing worked, and some of it (like the latter of those two
lines) actually interfered with the div.content rule for reasons
I still don't understand. (If any of you CSS gurus want to enlighten
me, or suggest a better or more complete solution, or solutions that
work with other web pages, I'm all ears!)
I'll try for a more complete solution some other time, but for now,
I'm spending my July 4th celebrating my independance from Amazon's
idea of the one true browser width.
Tags: tech, web, css, mozilla, firefox
[
21:01 Jul 04, 2007
More tech/web |
permalink to this entry |
]
Sat, 30 Jun 2007
Today's topics are three: the excellent comic called xkcd,
the use of google to search a site but exclude parts of that site,
and, most important, the useful Mozilla technique called Bookmarklets.
I found myself wanting to show someone a particular xkcd comic
(the one about dreams).
Xkcd, for anyone who hasn't been introduced, is a wonderfully
geeky, smart, and thoughtful comic strip drawn by Randall
Munroe.
How to search for a comic strip? Xkcd has an archive page but that
seems to have a fairly small subset of all the comics. But fortunately
the comics also have titles and alt tags, which google can index.
But googling for dreams site:xkcd.org gets me lots of
hits on xkcd's forum and blag pages (which I hadn't even known
existed) rather than just finding the comic I wanted. After some
fiddling, though, I managed to find a way to exclude all the fora
and blag pages: google for
xkcd dreams site:xkcd.com -site:forums.xkcd.com -site:fora.xkcd.com -site:blag.xkcd.com
Nifty!
In fact, it was so nifty that I decided I might want to use it again.
Fortunately, Mozilla browsers like Firefox have a great feature called
bookmarklets. Bookmarklets are like shell aliases in Linux:
they let you assign an alias to a bookmark, then substitute in your
own terms each time you use it.
That's probably not clear, so here's how it works in this specific
case:
- I did the google search I listed above, which gave me this long
and seemingly scary URL:
http://www.google.com/search?hl=en&q=xkcd+dreams+site%3Axkcd.com+-site%3Aforums.xkcd.com+-site%3Afora.xkcd.com+-site%3Ablag.xkcd.com&btnG=Search
- Bookmarks->Bookmark this page. Unfortunately Firefox
doesn't let you change any bookmark properties at the time you make
the bookmark, so:
- Bookmarks->Organize Bookmarks, find the new bookmark
(down at the bottom of the list) and Edit->Properties...
- Change the Name to something useful (I called it
Xkcd search)
then choose a simple word for the Keyword field. This is the "alias"
you'll use for the bookmark. I chose xkcd.
- In the Location field, find the term you want to be
variable. In this case, that's "dreams", because I won't always be
searching for the comic about dreams, I might want to search for anything.
Change that term to %s.
(Note to non-programmers: %s is a term often used in programming
languages to mean "replace the %s with a string I'll provide
later.")
So now the Location looks like:
http://www.google.com/search?hl=en&q=xkcd+%s+site%3Axkcd.com+-site%3Aforums.xkcd.com+-site%3Afora.xkcd.com+-site%3Ablag.xkcd.com&btnG=Search
- Save the bookmarklet (click OK) and, optionally, drag it
into a folder somewhere where it won't clutter up your bookmarks menu.
You aren't ever going to be choosing this from the menu.
Now I had a new bookmarklet. To test it, I went to the urlbar in
Firefox and typed:
xkcd "regular expressions"
Voila! The first hit was exactly the comic I wanted.
(You'll find many more useful bookmarklets by
googling on
bookmarklets.)
Tags: tech, web, bookmarklets
[
22:13 Jun 30, 2007
More tech/web |
permalink to this entry |
]
Sun, 27 May 2007
For a
bit
over a year I've been running a patched version of Firefox,
which I call
Kitfox,
as my main browser. I patch it because there are a few really
important features that the old Mozilla suite had which Firefox
removed; for a long time this kept me from using Firefox
(and I'm
not
the only one who feels that way), but when the Mozilla Foundation
stopped supporting the suite and made Firefox the only supported
option, I knew my only choice was to make Firefox do what I needed.
The patches were pretty simple, but they meant that I've been building
my own Firefox all this time.
Since all my changes were in JavaScript code, not C++,
I knew this was probably all achievable with a Firefox extension.
But never around to it;
building the Mozilla source isn't that big a deal to me. I did it as
part of my job for quite a few years, and my desktop machine is fast
enough that it doesn't take that long to update and rebuild, then
copy the result to my laptop.
But when I installed the latest Debian, "Etch", on the laptop, things
got more complicated. It turns out Etch is about a year behind in
its libraries. Programs built on any other system won't run on Etch.
So I'd either have to build Mozilla on my laptop (a daunting prospect,
with builds probably in the 4-hour range) or keep another
system around for the purpose of building software for Etch.
Not worth it. It was time to learn to build an extension.
There are an amazing number of good tutorials on the web for writing
Firefox extensions (I won't even bother to link to any; just google
firefox extension and make your own choices).
They're all organized as step by step examples with sample code.
That's great (my favorite type of tutorial) but it left my real
question unanswered: what can you do in an extension?
The tutorial examples all do simple things like add a new menu or toolbar
button. None of them override existing Javascript, as I needed to do.
Canonical
URL to the rescue.
It's an extension that overrides one of the very behaviors I wanted to
override: that of adding "www." to the beginning and ".com" or ".org"
to the end of whatever's in the URLbar when you ctrl-click.
(The Mozilla suite behaved much more usefully: ctrl-click opened the
URL in a new tab, just like ctrl-clicking on a link. You never need
to add www. and .com or .org explicitly because the URL loading code
will do that for you if the initial name doesn't resolve by itself.)
Canonical URL showed me that all you need to do is make an overlay
containing your new version of the JavaScript method you want to
override. Easy!
So now I have a tiny Kitfox extension
that I can use on the laptop or anywhere else. Whee!
Since extensions are kind of a pain to unpack,
I also made a source tarball which includes a simple Makefile:
kitfox-0.1.tar.gz.
Tags: tech, web, mozilla, firefox, programming
[
11:59 May 27, 2007
More tech/web |
permalink to this entry |
]
Sat, 05 May 2007
For quite some time, I've been seeing all too frequently the dialog
in Firefox which says:
A script on this page may be busy, or it may have stopped
responding. You can stop the script now, or continue to see if the
script will complete.
[Continue] [Stop script]
Googling found lots of pages offering advice on how to increase the
timeout for scripts from the default of 5 seconds to 20 or more
(change the preference dom.max_script_run_time in
about:config. But that seemed wrong. I was seeing the
dialog on lots of pages where other people didn't see it, even
on my desktop machine, which, while it isn't the absolute latest
and greatest in supercomputing, still is plenty fast for basic
web tasks.
The kicker came when I found the latest page that triggers this
dialog: Firefox' own cache viewer. Go to about:cache and
click on "List Cache Entries" under Disk cache device.
After six or seven seconds I got an Unresponsive script dialog
every time. So obviously this wasn't a problem with the web sites
I was visiting.
Someone on #mozillazine pointed me to Mozillazine's page
discussing this dialog, but it's not very useful. For instance,
it includes advice like
To determine what script is running too long, open the Error Console
and tell it to stop the script. The Error Console should identify
the script causing the problem.
Error console? What's that? I have a JavaScript Console, but it
doesn't offer any way to stop scripts. No one on #mozillazine
seemed to have any idea where I might find this elusive Error
console either.
Later Update: turns out this is new with Firefox 2.0.
I've edited the Mozillazine page to say so. Funny that no one on
IRC knew about it.
But there's a long and interesting
MozillaZine discussion of the problem
in which it's clear that it's often caused by extensions
(which the Mozillazine page had also suggested).
I checked the suggested list of Problematic
extensions, but I didn't see anything that looked likely.
So I backed up my Firefox profile and set to work, disabling my
extensions one at a time. First was Adblock, since it appeared
in the Problematic list, but removing it didn't help: I still got
the Unresponsive script when viewing my cache.
The next try was Media Player Connectivity. Bingo! No more
Unresponsive dialog. That was easy.
Media Player Connectivity never worked right for me anyway.
It's supposed to help with pages that offer videos not as a simple
video link, like movie.mpeg or movie.mov or whatever,
but as an embedded object in the page which insists on a
specific browser plug-in
(like Apples's QuickTime or Microsoft's Windows Media Player).
Playing these videos in Firefox is a huge pain in the keister -- you
have to View Source and crawl through the HTML trying to find the URL
for the actual video. Media Player Connectivity is supposed to help
by doing the crawl for you and presenting you with video links
for any embedded video it finds. But it typically doesn't find
anything, and its user interface is so inconsistent and complicated
that it's hard to figure out what it's telling you. It also can't
follow the playlists and .SMIL files that so many sites use now.
So I end up having to crawl through HTML source anyway.
Too bad! Maybe some day someone will find a way to make it easier
to view video on Linux Firefox. But at least I seem to have gotten
rid of those Unresponsive Script errors. That should make for nicer
browsing!
Tags: tech, web, mozilla, firefox
[
13:07 May 05, 2007
More tech/web |
permalink to this entry |
]
Tue, 27 Mar 2007
The wireless network was messed up at the Super-8.
No surprise there -- Super-8 motels always have flaky wireless.
But last night's wi-fi travails were quite a bit more interesting
than the usual story.
When we checked in, the sign
at the desk saying "We know the wi-fi is flaky;
you've been warned, no refunds", wasn't encouraging.
We needed some information from the web fairly quickly,
so rather than futz with trying to get the motel system to work we
headed over to the public library, where I got re-acquainted with the
travails of browsing circa 1999 by using their slow link and
Internet Explorer. How do people live without being able to open
lots of search results in multiple tabs? And hitting return didn't
work in any search fields. Eesh.
I was also amused to find that when I searched on terms related to IRS
and tax information, several of the results brought up a page saying
they were blocked by the library's firewall. Wouldn't want anyone
looking at that sort of smut on public library machines!
Anyway, after dinner we had time to fiddle with the hotel wi-fi.
When we couldn't get a reliable signal in the room,
we carted our laptops down to the lobby to see if things were
better there. They weren't.
But the single public lobby workstation was free (showing a
myspace page), so we decided to try that and see if it worked any
better than our laptops. Nope.
But something about the throbber in the lobby workstation's browser
seemed familiar to me. That's not IE ... it's not firefox either ...
Why, it's konqueror! But ... doesn't that mean ...?
We tried browsing to a few familiar file paths, like /etc/fstab,
and sure enough, the lobby workstation was running linux (Slackware).
We played filename guessing games for a bit before discovering
Tools->Open Terminal. That wasn't very reliable, though --
it seemed to have a redraw problem and it was hard to get past that.
(Later I found an alternative elsewhere in the Konqueror menus,
"Show Terminal Emulator". I'm not clear on why Konqueror needs two
different terminal emulators, but it was helpful here.)
Then I experimentally typed "whoami" and
discovered that we were root. How handy!
It turned out that the machine was running a live CD based distro.
Dave stumbled on /etc/issue, which began with the lines:
-------------------------------------------------------
:: WHAX 1.0 -- Dev Edition: http://www.iwhax.net
-------------------------------------------------------
User : root
Pass : toor
If you use this CD not for development purposes, remember to change
passwords!
Great fun! And we played around with the machine for a bit.
But alas, none of this helped with the net -- the WHAX box was just as
much a victim of the network as we were.
After a brief delay to admire the bright yellow Sunbeam Alpine that
pulled up on a trailer outside the registration desk (the folks
playing poker at the next table had never seen a Sunbeam before),
Dave took to the parking lot with his laptop looking for a
stronger signal. (He can do this with his Prism2 card while I can't
with my Prism54. Why is it that every Linux wi-fi driver
has a completely different set of supported operations?)
Does it still count as war-walking if you're just looking for a
working connection for a net you've paid for?
He found the strongest signal at the Travelodge next door (the net is
shared between the two motels), just outside the metal door marked
"DISCONNECT MAIN ELECTRIC".
I guess whoever set up this network decided
that the perfect place to put a radio transmitter was in the electric
main box surrounded by lots of metal and current-carrying wires.
Not being an RF engineer myself, somehow that would not have occurred
to me as the ideal spot. But what do I know?
Tags: tech
[
21:28 Mar 27, 2007
More tech |
permalink to this entry |
]
Sat, 24 Mar 2007
Every time I do a system upgrade on my desktop machine,
I end up with a web server that can't do PHP or CGI,
and I have to figure out all over again how to enable all the
important stuff. It's all buried in various nonobvious places.
Following Cory Doctorow's
"My
blog, my outboard brain" philosophy,
I shall record here the steps I needed this time, so next time I can
just look them up:
-
Install apache2.
-
Install an appropriate mod-php package (or, alternately, a full fledged
PHP package).
-
Edit /etc/apache2/sites-enabled/000-default, find the stanza
corresponding to the default site, and change AllowOverride
from None to something more permissive. This controls what's
allowed through .htaccess files. For testing, use All;
for a real environment you'll probably want something
more fine grained than that.
-
While you're there, look for the Options line in the same stanza
and add +ExecCGI to the end.
-
Edit /etc/apache2/apache2.conf and search for PHP. No, not
the line that already includes index.php; keep going to the lines
that look something like
#AddType application/x-httpd-php .php
#AddType application/x-httpd-php-source .phps
Uncomment these. Now PHP should work. The next step is to enable CGI.
-
Still in /etc/apache2/apache2.conf, search for CGI.
Eventually you'll get to
# To use CGI scripts outside /cgi-bin/:
#
#AddHandler cgi-script .cgi
Uncomment the AddHandler line.
- Finally, disable automatic start of apache at boot time (I don't
need a web server running on my workstation every day, only on days
when I'm actually doing web development). I think some upcoming Ubuntu
release may offer a way to do that through Upstart, but for now, I
mv /etc/init.d/apache /etc/noinit.d
(having previously created /etc/noinit.d for that purpose).
Tags: tech, web, apache
[
18:54 Mar 24, 2007
More tech/web |
permalink to this entry |
]
Sun, 25 Feb 2007
I've used HTML for presentations -- instead of open office, or
magicpoint, or powerpoint -- for several years now.
I like using HTML because I can put my slides online and people
can view them directly, without needing to download a whole
presentation and run some kind of special viewer for it.
It's also lightweight (the files are fairly small), I get
to write in a language I already know pretty well,
and Firefox is already installed on my laptop and
works nicely as a presentation tool.
There are plenty of packages to generate HTML slides -- like
S5. But they
weren't very well developed when I first got interested in
HTML presentations, so I rolled my own Javascript-based
slideshow and have been gradually tweaking it ever since.
I've never tried to package up my presentation system;
my setup is pretty simple (one javascript file, one CSS
file, and the set of HTML slides), and
I figure there are enough prepackaged setups around that
there's no need for another one.
But I have been meaning to put a sample presentation online
which describes how the system works and how to copy and
adapt it. So here it is, a presentation about making
presentations:
Slide
Presentations in HTML and JavaScript.
Tags: tech
[
18:12 Feb 25, 2007
More tech |
permalink to this entry |
]
Tue, 24 Oct 2006
I get tons of phishing scam emails spoofing Amazon. You know, the
ones that say "Your Amazon account may have been compromised: please
click here to log in and verify your identity", and if you look at the
link, it goes to
http://123.45.67.8/morestuff instead of
http://www.amazon.com/morestuff. I get lots of similar phishing
emails spoofing ebay and various banks.
But yesterday's was different. The URL was this:
http://www.amazon.com/gp/amabot/?pf_rd_url=http://211.75.237.149/%20%20/amazon/xec.php?cmd=sign-in
Check it out: they're actually using amazon.com, and Amazon has a 'bot
called amabot that redirects you to somewhere else. Try this, for
example:
http://www.amazon.com/gp/amabot/?pf_rd_url=http://bn.com
-- you start on Amazon's site and end up at Barnes & Noble.
When a family member got tricked by a phish email a few months ago
(fortunately she became suspicious and stopped before revealing
anything important)
I gave her a quick lesson in how URLs work and how to recognize the
host part. "If the host part isn't what you think it should be,
it's probably a scam," I told her. That's pretty much the same as what
Amazon says (#6 on their "Identifying Phishing or Spoofed E-mails"
page). I guess now I need to teach her how to notice
that there's another URL embedded in the original one, even when the
original one goes to the right place. That's a bit more advanced.
I suspect a lot of anti-phishing software uses the same technique and
wouldn't have flagged this URL.
I reported the phish to Amazon (so far, just an automated reply, but
it hasn't been very long). I hope they look into this use of their
amabot and consider whether such a major phishing target really needs
a 'bot that can redirect anywhere on the net.
Tags: tech, web, security
[
11:34 Oct 24, 2006
More tech/web |
permalink to this entry |
]
Mon, 04 Sep 2006
I've been updating some web pages with tricky JavaScript and CSS,
and testing to see if they work in IE (which they never do) is
a hassle involving a lot of pestering of long suffering friends.
I've always heard people talk about how difficult it is to get
IE working on Linux under WINE. It works in
Crossover Office
(which is a good excuse to get Crossover: the company, Codeweavers,
is a good open source citizen and has contributed lots of work
to WINE, and I've bought from them in the past) but most people
who try installing IE under regular WINE seem to have problems.
Today someone pointed me to
IEs 4
Linux. It's a script that downloads IE and installs it under WINE.
You need wine and cabextract installed.
I was sure it couldn't be that simple, but it seemed easy enough to try.
It works great! Asked me a couple of questions, downloaded IE,
installed it, gave me an easy-to-run link in ~/bin, and it runs fine.
Now I can test my pages myself without pestering my friends.
Good stuff!
Tags: tech, web, linux
[
15:21 Sep 04, 2006
More tech/web |
permalink to this entry |
]
Sun, 20 Aug 2006
I finally got my Microsoft Rebate voucher!
Remember the California
Microsoft antitrust case, oh so many years ago?
A bit over three years ago (seems longer) it was determined in a
class-action suit that Microsoft had been abusing their monopoly in
order to overcharge for their software. Any Californian who had
purchased Microsoft products between February 1995 and December 2001
could apply for a rebate based on the number of MS products purchased.
(Curiously, no one ever seemed to point out that Microsoft did not
reduce its prices after this decision, nor did I ever see anyone
question why it's okay for them to overcharge now when it wasn't okay
then. That has puzzled me for some time. Perhaps questions like that
show why I'm a programmer instead of a lawyer or corporate exec.)
Over the years since the decision I've periodically wondered what ever
happened to the rebate vouchers we were supposed to get. But a few
weeks ago they started appearing. I got mine late last week.
The voucher is only redeemable for purchased software (from anyone,
not just Microsoft) or a fairly restrictive list of hardware:
computers (but not components to build a
computer), printers, monitors, scanners, keyboards, mice or trackballs.
For a Linux user who builds computers from parts (to avoid paying the
"Microsoft Tax" or to get a better price), it's a little tough to
use up that voucher. Now where did I put the receipt for that printer
I bought a few years ago? Or maybe it's time to buy a copy of
Crossover Office for
testing web sites against IE.
In any case, if you sent in your rebate claim way back when and
haven't heard anything, watch your mailbox. They say most people should
receive their vouchers this month (August). If you don't, you can
find more information at microsoftcalsettlement.com.
Tags: tech
[
10:58 Aug 20, 2006
More tech |
permalink to this entry |
]
Fri, 04 Aug 2006
Every time I click on a mailto link, Firefox wants to bring up
Evolution. That's a fairly reasonable behavior (I'm sure Evolution
is configured as the default mailer somewhere on my system even
though I've never used it) but it's not what I want, since I
have mutt running through a remote connection to another machine
and that's where I'd want to send mail. Dismissing the dialog is
an annoyance that I keep meaning to find a way around.
But I just learned about two excellent solutions:
First: network.protocol-handler.warn-external.mailto
Set this preference to TRUE (either by going to about:config
and searching for mailto, then doubleclicking on the line for
this preference, or by editing the config.js or user.js file
in your firefox profile) and the next time you click on a
mailto link, you'll get a confirmation dialog asking whether
you really want to launch an external mailer.
"Ew! Cancelling a dialog every time is nearly as bad as cancelling
the Evolution launch!" Never fear: this dialog has a
"Don't show me this again" checkbox, so check it and click Cancel
and Firefox will remember. From then on, clicks on mailto links
will be treated as no-ops.
"But wait! It's going to be confusing having links that do
nothing when clicked on. I'm not going to know why that
happened!"
Happily, there's a solution to that, too:
you can set up a custom user style
(in your chrome/userContent.css directory) to show a custom
icon when you mouse over any mailto link. Shiny!
Tags: tech, web, firefox, mozilla
[
21:19 Aug 04, 2006
More tech/web |
permalink to this entry |
]
Tue, 25 Apr 2006
I've long been an advocate of making
presentations
in HTML rather than using more complex presentation software such as
PowerPoint, Open Office Presenter, etc. For one thing, those
presentation apps are rather heavyweight for my poor slow laptop.
For another, you can put an HTML presentation on the web and everyone
can see it right away, without needing to download the whole
presentation and fire up extra software to see it.
The problem is that Mozilla's fullscreen mode doesn't give you an easy
way to get rid of the URL/navigation bar, so your presentations look
like you're showing web pages in a browser. That's fine for some
audiences, but in some cases it looks a bit unpolished.
In the old Mozilla suite, I solved the problem by having a separate
profile which I used only for presentations, in which I customized
my browser to show no urlbar. But having separate profiles means you
always have to specify one when you start up, and you can't quickly
switch into presentation mode from a running browser. Surely there was
a better way.
After some fruitless poking in the source, I decided to ask around
on IRC, and Derek Pomery (nemo) came up with a wonderful CSS hack to
do it. Just add one line to your chrome/userChrome.css file.
In Firefox:
#toolbar-menubar[moz-collapsed=true] + #nav-bar { display: none !important; }
In Seamonkey:
#main-menubar[moz-collapsed=true] + #nav-bar { display: none !important; }
This uses a nice CSS trick I hadn't seen before, adjacent
sibling selectors, to set the visibility of one item based on the state
of a sibling which appears earlier in the DOM tree.
(A tip for using the DOM Inspector to find out the names of
items in fullscreen mode: since the menus are no longer visible, use
Ctrl-Shift-I to bring up the DOM Inspector window.
Then File->Inspect a Window and select the main content window,
which gets you the chrome of the window, not just the content.
Then you can explore the XUL hierarchy.)
This one-line CSS hack turns either Firefox or Seamonkey
into an excellent presentation tool. If you haven't tried using
HTML for presentations, I encourage you to try it. You may find
that it has a lot of advantages over dedicated presentation
software.
Addendum: I probably should have mentioned that
View->Toolbars->Navigation Controls
turns off the toolbar if you just need it for a one-time
presentation or can't modify userChrome.css.
You have to do it before you flip to fullscreen, of course,
since the menus won't be there afterward,
and then again when you flip back.
I wasn't happy with this solution myself because of the two
extra steps required every time, particularly because the steps
are awkward since they require using the laptop's trackpad.
Tags: tech, web, firefox, speaking
[
17:59 Apr 25, 2006
More tech/web |
permalink to this entry |
]
Fri, 14 Apr 2006
I'm not very consistent about looking at the statistics on my web site.
Every now and then I think of it, and take a look at who's been
visiting, why, and with what, and it's always entertaining.
The first thing I do is take the apache log and run webalizer
on it, to give me a breakdown of some of the "top" lists.
Of course, I'm extremely interested in the user agent list:
which browsers are being used most often? As of last month, the Shallowsky
list still has MSIE 6.0 in the lead ... but it's not as big a lead
as it used to be, at 56.04%. Mozilla 5.0 (which includes all Gecko-
based browsers, as far as I know, including Mozilla, Firefox, Netscape
6 and 7, Camino, etc.) is second with 20.31%. Next are four search
engine 'bots, and then we're into the single digit percentages with
a couple of old IE versions and Opera.
AvantGo (they're still around?) is number 11 with 0.37% -- interesting.
It looks like they're grabbing the Hitchhiker's Guide to the Moon;
then there are a bunch of lines like:
sync37.avantgo.com - - [05/Apr/2006:14:29:25 -0700] "GET / HTTP/1.0" 200 4549 "http://www.nineplanets.org/" "Mozilla/4.0 (compatible; AvantGo 6.0; FreeBSD)"
and I'm not sure how to read that (nineplanets.org is
The Nine Planets, Bill Arnett's
excellent and justifiably popular planetary site, and he and I have
cross-links, but I'm not sure what that has to do with avantgo and my
site). Not that it's a problem: of course, anyone is welcome to read
my site on a PDA, via AvantGo or otherwise. I'm just curious.
Amusingly, the last user agent in the top fifteen is GIMP Layers, syndicating this blog.
Another interesting list is the search queries: what search terms did
people use which led them to my site? Sometimes that's more
interesting than other times: around Christmas, people were searching
for "griffith park light show" and ending up at my lame collection of
photos from a previous year's light show. I felt so sorry for them:
Griffith Park never puts any information on the web so it's impossible
to find out what hours and dates the light show will be open, so I
know perfectly well why they were googling, and they certainly weren't
getting any help from me. I would have put the information there if
I'd known -- but I tried to find out and couldn't find it either.
But this month, no one is searching on anything unusual. The top
searches leading to my site for the past two months are terms like
birds, gimp plugins, linux powerpoint, mini laptops, debian chkconfig,
san andreas fault, pandora, hummingbird pictures, fiat x1/9,
jupiter's features, linux photo,
and a rather large assortment of dirt bike queries. (I have very
little dirt bike content on my site, but people must be desperate to
find web pages on dirt bikes because those always show up very
prominently in the search string list.)
Most popular pages are this blog (maybe just because of RSS readers),
the Hitchhiker's Guide to the Moon, and bird photos, with an
assortment of other pages covering software, linux tips, assorted
photo collections, and, of course, dirt bikes.
That's most of what I can get from webalizer. Now it's time to look at
the apache error logs. I have quite a few 404s (missing files).
I can clean up some of the obvious ones, and others are coming from
external sites I can't do anything about that for some reason link
to filenames I deleted seven years ago; but how can I get a list of
all the broken internal links on my site, so at least I can fix
the errors that are my own fault?
Kathryn on Linuxchix pointed me to dead-links.com, a rather cool
site. But it turns out it only looks for broken external
links, not internal ones. That's useful, too, just not what I
was after this time.
Warning: if you try to save the page from firefox, it will
start running all over again. You have to copy the content and paste
it into a file if you want to save it.
But Kathryn and Val opined that wget was probably the way to go
for finding internal links. Turns out wget has an option to delete
each file after downloading it, so you can wget a whole site but not
actually need to use the local space to duplicate the site.
Use this command:
wget --recursive -nd -nv --delete-after --domains=domain.com http://domain.com/ | tee wget.out 2>&1
Now open the resulting file in an editor and search repeatedly for
ERROR to find all the broken links. Unfortunately the errors are on
a separate line from the filenames they reference,
so you can't just use a grep. wget also
gets some things wrong: for instance, it tries to download the .class
file of a Java applet inside a .jar, then reports an error when the
class doesn't exist. (--reject .class might help that.)
Still, it's not hard to skip past these errors,
and wget does seem to be a fairly good way of finding broken internal links.
There's one more check left to do in the access log.
But that's a longer story, and a posting for another day.
Tags: tech, web
[
21:43 Apr 14, 2006
More tech/web |
permalink to this entry |
]
Thu, 12 Jan 2006
Anyone who's been following the Sony CD rootkit story -- the one where
Sony audio CDs come infected with a program which, when the CD is
played on Windows PCs, installs a rootkit which is virtually
impossible to uninstall and which makes the PC susceptible to all
sorts of third-party attacks -- won't want to miss
Trend
Micro's information page regarding Sony's rootkits.
Highlight:
This tool works by applying a relatively new technology called
rootkit technology. Rootkits are used to hide system
information, such as running processes, files, or registry entries.
As a standalone application, it is non-malicious. However, certain malware
applications use it [ ... ]
Good thing Trend Micro is there to give us the lowdown on this new
(and non-malicious) rootkit technology!
In a vaguely related note: a speaker at my Toastmasters club today
planned a Powerpoint presentation. (This is unusual in Toastmasters,
but does happen occasionally.) He diligently showed up early to
set up his computer and the projector so he'd be ready before the
meeting started. As we were about to begin the meeting, with the
projector showing his first slide, suddenly a dialog popped up
on top of the slide, informing him that his system auto-update
was finished, and he needed to reboot. It offered two buttons:
[Reboot now] [Reboot later].
The later button was greyed out.
Isn't it nice when your system helpfully gives you automatic updates?
He fiddled for a while but finally gave up and rebooted. I couldn't
help noticing that the first screen that appeared upon reboot was a
Trend Micro screen.
Tags: tech
[
21:17 Jan 12, 2006
More tech |
permalink to this entry |
]
Tue, 22 Nov 2005
It's Mars season (Mars was at opposition at the beginning of
November, so Mars is relatively close this month and it's a
good time to observe it) and I've been making pencil sketches
of my observations.
Of course, that also means firing up the scanner
in order to put the sketches on a web page.
Last weekend I scanned the early sketches.
It was the first time in quite a while that I'd used the scanner
(which seldom gets used except for sketches), and probably only the
second time since I switched to Ubuntu. I was unreasonably pleased
when I plugged it in, went to GIMP's Acquire menu, and was able to
pull up xsane with no extra fiddling. (Hooray for Ubuntu!
Using Debian for a while gives you perspective, so you can get
great joy over little things like "I needed to use my scanner
and it still works! I needed to make a printout and printing hasn't
broken recently!")
Anyway, xsane worked fine, but the scans all came out
looking garish -- bright and washed out, losing most of the detail
in the shading. I know the scanner is capable of handling sketches
(it's a fairly good scanner, an Epson Perfection 2400 Photo) but
nothing I did with the brightness, contrast, and gamma adjustments
got the detail back.
The adjustment I needed turned out to live in the "Standard Options"
window in xsane: a Brightness slider which apparently
controls the brightness of the light (it's different from the
brightness adjustment in the main xsane scanning window).
Setting this to -2 gave me beautiful scans, and I was able to
update my 2005
Mars sketch page.
Tags: tech
[
14:13 Nov 22, 2005
More tech |
permalink to this entry |
]
Wed, 16 Nov 2005
I've been meaning to write up my impression of a few MP3 players
I've tried, since although the web is full of MP3 player reviews,
hardly any of them give you any idea of how the beast actually
works when playing music -- does it remember its position
in a song? Does it stay in random mode, and how hard is it to
get into that mode? Can you fast forward? All those details that
are critical in day to day use, but which are impossible to tell
from the packaging or, sadly, from most reviews.
The review came out rather long, so instead of making it a
blog entry I've put it on its own MP3 Player Review page.
Tags: tech
[
18:48 Nov 16, 2005
More tech |
permalink to this entry |
]
Mon, 10 Oct 2005
Ever want to look for something in your browser cache, but when you
go there, it's just a mass of oddly named files and you can't figure
out how to find anything?
(Sure, for whole pages you can use the History window, but what if
you just want to find an image you saw this morning
that isn't there any more?)
Here's a handy trick.
First, change directory to your cache directory (e.g.
$HOME/.mozilla/firefox/blahblah/Cache).
Next, list the files of the type you're looking for, in the order in
which they were last modified, and save that list to a file. Like this:
% file `ls -1t` | grep JPEG | sed 's/: .*//' > /tmp/foo
In English:
ls -t lists in order of modification date, and -1 ensures
that the files will be listed one per line. Pass that through
grep for the right pattern (do a file * to see what sorts of
patterns get spit out), then pass that through sed to get rid of
everything but the filename. Save the result to a temporary file.
The temp file now contains the list of cache files of the type you
want, ordered with the most recent first. You can now search through
them to find what you want. For example, I viewed them with Pho:
pho `cat /tmp/foo`
For images, use whatever image viewer you normally use; if you're
looking for text, you can use grep or whatever search you lke.
Alternately, you could
ls -lt `cat foo` to see what was
modified when and cut down your search a bit further, or any
other additional paring you need.
Of course, you don't have to use the temp file at all. I could
have said simply:
pho `ls -1t` | grep JPEG | sed 's/: .*//'`
Making the temp file is merely for your convenience if you think you
might need to do several types of searches before you find what
you're looking for.
Tags: tech, web, mozilla, firefox, pipelines, CLI, shell, regexp
[
22:40 Oct 10, 2005
More tech/web |
permalink to this entry |
]
Wed, 05 Oct 2005
I love the messages I keep getting from having attended LinuxWorld a
few months ago. They say:
Dear LinuxWorld Attendee:
That's it. That's all they say.
Well, unless you dig deeper. It turns out there's an html part, too,
which actually does have content (asking me to participate in a
survey). But I would never have seen that if I didn't know how
to read the MIME structure of email messages.
You see, the message is sent as
Content-Type: multipart/alternative, which means that there's
a text part and an html part which are supposed to be equivalent.
You can read either part and they should say the same thing.
Lots of modern mailers, including Mozilla, mutt, pine, probably
Opera, and even Apple Mail can now be configured to give preferences
to the text part of messages (so you don't have to squint your way
through messages written in yellow text on a pink background, or in
tiny 6-point text that's too small for your eyes, and so that you
can be assured of safety from web bugs and other snoopware which
can be embedded in html mail). Any mailer so configured would show this
message as blank, just as I'm seeing it in mutt.
It seems amazing that their web developers would go to the extra trouble
of setting up MIME headers for multipart/alternative content, then
not bother to put anything in the content. Why not just send as
plain html if you don't want to create a text part?
I'd let them know they're sending blank messages, but tracking
down a contact address seems like more trouble than it's worth.
The mail purports to come from LinuxWorldConference&Expo@idg.com;
the message references URLs from www.exhibitsurveys.com;
the actual message (as seen in the headers) came from
outboundmailexhibitsurvey.com. It's probably exhibitsurveys.com
generating the bad email messages, but it's hard to say for sure.
Suggestion for web developers: if you write code to send out mass
mailings, you might want to check the mail that's actually getting
sent out. If your program generates more than one MIME attachment,
it's a good idea to check all the attachments and make sure you're
sending what you think you are.
Look at the actual message structure, don't just glance at the
message in the mail program you happen to use.
The fact that a message displays in one mailer does not imply
that it will display correctly for all users
(especially for a survey aimed at Linux users,
who use a wide variety of mailers on many platforms and are
quite likely to set non-default options).
If you don't know MIME, find someone who does to sanity-check
your output ... or don't send multiple MIME attachments.
Tags: tech
[
12:30 Oct 05, 2005
More tech |
permalink to this entry |
]
Tue, 04 Oct 2005
Mozilla Firefox's model has always been to dumb down the basic
app to keep it simple, and require everything else to be implemented as
separately-installed extensions.
There's a lot to be said for this model, but aside from security
(the need to download extensions of questionable parentage from unfamiliar
sites) there's another significant down side: every time you upgrade your
browser, all your extensions become disabled, and it may be months
before they're updated to support the new Firefox version (if indeed
they're ever updated).
When you need extensions for basic functionality, like controlling
cookies, or basic sanity, like blocking flash, the intervening
months of partial functionality can be painful, especially when
there's no reason for it (the plug-in API usually hasn't changed,
merely the version string).
It turns out it's very easy to tweak your installed plug-ins
to run under your current Firefox version.
- Locate your profile directory (e.g. $HOME/firefox/blah.blah
for Firefox on Linux).
- Edit profiledirectory/extensions/*/install.rdf
- Search for maxVersion.
- Update it to your current version (as shown in the
Tools->Extensions dialog).
- Restart the browser.
Disclaimer: Obviously, if the Firefox API really has changed
in a way that makes it incompatible with your installed extensions,
this won't be enough. Your extensions may fail to work, crash your
browser, delete all your files, or cause a massive meteorite to
strike the earth causing global extinction. Consider this a
temporary solution; do check periodically to see if there's a real
extension update available.
More
information on extension versioning (may be out of date).
Tags: tech, web, mozilla, firefox
[
19:47 Oct 04, 2005
More tech/web |
permalink to this entry |
]
Fri, 16 Sep 2005
On the
Linuxchix grrltalk
list, someone was bothered by the tone of Eric Raymond's
How to
Ask Questions the Smart Way. And certainly, the tone is a bit
brusque (like much of ESR's writing), though it's full of useful advice.
The discussion hinged around user demands such as "YOU SUCK! YOU
MUST FIX THIS NOW!" This is obviously rude, and just as obviously
has little chance of getting a positive reaction from developers.
The problem is that after twenty or so of these demands, even a
polite user coming in to ask for a feature may be snapped at.
I've seen developers get touchy after reading a slew of this sort of
bug reports, and snap at someone who wasn't being particularly rude.
Really, a lot of users have no idea how many of these rude,
demanding, "YOU SUCK -- FIX THIS IMMEDIATELY!" messages some
developers get. Try "watching" a category or developer in bugzilla
for some major project like Mozilla for a month to get an idea
of the volume of email that streams in. It's easy to get ten or more
of these in one day's morning mail before you've even finished your
coffee. Lots of developers just stop reading their bug mail after
a while. I hate that and think it's wrong, but I can understand
why they do it.
Sometimes problems that twenty users comment on, even if they're real
issues, are hard to fix, or the fix would conflict with some other
important aspect of the program.
"Hard to fix" or "Hard to find a way to fix the bug
without breaking another important feature" is not an adequate
solution when you're developing software professionally. But when
you're volunteering your own evenings, weekends and vacations to
contribute to open source software, and some user who probably spent
his evenings watching TV and last weekend skiing, who doesn't
seem to have spent any time contributing to the project beyond
filing a few bugs, shows up and demands that you drop the work
you're currently interested in and instead devote the next eight
weekends to fixing HIS feature ... well, after that happens a few
times it's easy to get a little touchy. When it happens day after
day, it's even easy to stop caring so much about user input in
general, and to (incorrectly) lump all users, not just the rude
ones, into this category.
I wish users, before making a request, would remind themselves that
developers are spending their spare time on the project, instead
of going skiing or watching TV or whatever -- and no, that's not
because developers are troglodyte geeks who have no other hobbies.
DO make suggestions, but remember when you do that you're probably
not talking to someone who's paid to maintain the program forty hours
a week. You're talking to someone who donated spare time to
create a program that you now find usable enough to care about.
No, rudeness doesn't solve anything. Developers being rude doesn't
improve this situation -- it won't make the users stop being rude,
it won't help the polite users, it won't even make the developers
feel better. But sometimes people get irritable when they're taken
for granted. Developers are only human. Whatever users might think.
Tags: tech
[
11:30 Sep 16, 2005
More tech |
permalink to this entry |
]
Sun, 11 Sep 2005
In the wake of the Hurricane Katrina devastation, one of FEMA's many
egregious mistakes is that their web site requires IE 6 in order for
victims to register for relief.
It's mostly academic. The Katrina victims who need help the
most didn't own computers, have net access, or, in many cases, even
know how to use the web. Even if they owned computers, those
computers are probably underwater and their ISP isn't up.
Nevertheless, some evacuees, staying with friends or relatives,
or using library or other public access computers, may need to
register for help using FEMA's web site.
It turns out that it's surprisingly difficult to google for the
answer to the seemingly simple question, "How do I make my browser
spoof IE6?" Here's the simple answer.
Opera: offers a menu to do this, and always has.
Mozilla or Firefox: the easiest way is to install the
User
Agent Switcher extension. Install it, restart the browser and
you get a user-agent switching menu which includes an IE6 option.
To change the user agent on Mozilla-based browsers without the
extension:
- type about:config into your urlbar
- Right-click in the window (on Mac I think that's
cmd-click to get a context menu?) and select New->String
- Use general.useragent.override for the preference name,
and Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1) for the value.
I think this takes effect immediately, no need to restart the
browser.
Safari (thanks to
Rick
Moen on svlug:
- Exit Safari. Open Terminal.
- Type defaults write com.apple.Safari IncludeDebugMenu
-boolean true
- Restart Safari.
Safari's menu bar will now include
Debug, which has an option
to change the user agent.
If you do change your user agent, please change it back after
you've finished whatever business required it. Otherwise, web site
administrators will think you're another IE user, and they they'll
use that as justification for making more ridiculous IE-only pages
like FEMA's. The more visits they see from non IE browsers, the more
they'll realize that not everyone uses IE.
Tags: tech, web
[
13:35 Sep 11, 2005
More tech/web |
permalink to this entry |
]
Mon, 27 Jun 2005
I spent a little time this afternoon chasing down a couple of recent
Firefox regressions that have been annoying me.
First, the business where, if you type a url into the urlbar and hit
alt-Enter (ctrl-Enter in my Kitfox variant) to open a new tab,
if you go back to the old tab you still see the new url in the
urlbar, which doesn't match the page being displayed there.
That turns out to be bug
227826, which was fixed a week and a half ago. Hooray!
Reading that bug yielded a nice Mozilla tip I hadn't previously
known: hitting ESC when focus is in the urlbar will revert the
urlbar to what it should be, without needing to Reload.
The other annoyance I wanted to chase down is the new failure of
firefox -remote to handle URLs with commas in them (as so
many news stories have these days); quoting the url is no help,
because it no longer handles quotes either. That means that trying
to call a browser from another program such as an IRC client is
doomed to fail for any complex url.
That turns out to be a side effect of the check-in for bug
280725, which had something to do with handling non-ASCII
URLs on Windows. I've filed bug
298960 to cover the regression.
That leaves only one (much more minor) annoyance: the way the
selection color has changed, and quite often seems to give me white
text on a dingy mustard yellow background. I think that's because of
bug
56314, which apparently makes it choose a background color
that's the reverse of the page's background, but which then doesn't
seem to choose a contrasting foreground color.
It turns out you can override this if you don't mind specifying a
single fixed set of selection colors (instead of having them change
with the colors of every page). In userChrome.css (for the urlbar)
and userContent.css (for page content):
::-moz-selection {
background-color: magenta;
color: white;
}
(obviously, pick any pair of colors which strikes your fancy).
Tags: tech, web, mozilla, firefox
[
21:45 Jun 27, 2005
More tech/web |
permalink to this entry |
]
Thu, 20 Jan 2005
I've been very frustrated with google searches lately. Not because
of those blog links The Register is always complaining about,
and for which the silly new "no-follow" anchor attribute was added:
I hardly ever see blog links in my google searches, and when I do
they're usually relevant to the search.
(Update: Mary pointed out to me that I was confusing two issues there.
The new anchor attribute does indeed
solve a very valid
problem (not the one The Reg complains about), and isn't silly at all.
She's quite right, of course.)
No, the problem I have is that the top hits always turn out to
be a search engine on some commercial site. Clicking on the google
link takes me to a search page on some random site which says "No
pages were found matching your search terms".
Today I hit a perfect example. I was looking up Apache http
redirects, so I googled for: htaccess mod_rewrite.
The first item is the official Apache documentation for mod_rewrite.
Great!
The second item looks like the following:
htaccess mod_rewrite
... Many htaccess mod_rewrite bargains can only be found online.
Shopping on the Internet is no less safe than shopping in a store or
by mail. ... htaccess mod_rewrite. ...
www.protectyoursite.info/
htaccess-deny-from-all/htaccess-mod-rewrite.html - 8k - Cached -
Similar pages
Strangely, only google seems to show these sorts of search hits.
Perhaps the spoofing sites only do their work for the googlebot,
and don't bother with lesser searchbots. But google still wins
the relevance award for most searches, even after I wade through
the forest of spoofs; so I guess they don't need to worry about
the spoofers until other search engines catch up in relevance.
Eventually, someone else will catch up, and google will need
to clean up its results. Until then ... <pulling on my
rubber boots to wade through the muck in search of real results
...>
Tags: tech
[
18:03 Jan 20, 2005
More tech |
permalink to this entry |
]
Wed, 19 Jan 2005
I've been surprised by the recent explosion in Windows desktop search
tools. Why does everyone think this is such a big deal that every
internet company has to jump onto the bandwagon and produce one,
or be left behind?
I finally realized the answer this morning. These people don't have
grep! They don't have any other way of searching out patterns in
files.
I use grep dozens of times every day: for quickly looking up a phone
number in a text file, for looking in my Sent mailbox for that url I
mailed to my mom last week, for checking whether I have any saved
email regarding setting up CUPS, for figuring out where in mozilla
urlbar clicks are being handled.
Every so often, some Windows or Mac person is opining about how
difficult commandlines are and how glad they are not to have to use
them, and I ask them something like, "What if you wanted to search
back through your mail folders to find the link to the cassini probe
images -- e.g. lines that have both http:// and cassini
in them?" I always get a blank look, like it would never occur to
them that such a search would ever be possible.
Of course, expert users have ways of doing such searches (probably
using command-line add-ons such as cygwin); and Mac OS X has the
full FreeBSD commandline built in. And more recent Windows
versions (Win2k and XP) now include a way to search for content
in files (so in the Cassini example, you could search for
http:// or cassini, but probably not both at once.)
But the vast majority of Windows and Mac users have no way to do
such a search, the sort of thing that Linux commandline users
do casually dozens of times per day. Until now.
Now I see why desktop search is such a big deal.
But rather than installing web-based advertising-drive apps with a
host of potential privacy and security implications ...
wouldn't it be easier just to install grep?
Tags: tech, pipelines, CLI, shell
[
12:45 Jan 19, 2005
More tech |
permalink to this entry |
]
Mon, 17 Jan 2005
Investigating some of the disappointing recent regressions in
Mozilla (in particular in handling links that would open new windows,
bug 278429),
I stumbled upon this useful little tidbit from manko, in the old
bug
78037:
You can use CSS to make your browser give different highlighting
for links that would open in a different window.
Put something like this in your
[moz_profile_dir]/chrome/userContent.css:
a[target="_blank"] {
-moz-outline: 1px dashed invert !important;
/* links to open in new window */
}
a:hover[target="_blank"] {
cursor: crosshair; text-decoration: blink;
color: red; background-color: yellow
!important
}
a[href^="http://"] {
-moz-outline: 1px dashed #FFCC00 !important;
/* links outside from current site */
}
a[href^="http://"][target="_blank"] {
-moz-outline: 1px dashed #FF0000 !important;
/* combination */
}
I questioned the use of outlines rather than colors, but then
realized why manko uses outlines instead: it's better to preserve
the existing colors used by each page, so that link colors go along
with the page's background color.
I tried adding a text-decoration: blink; to the a:hover
style, but it didn't work.
I don't know whether mozilla ignores blink, or if it's being
overridden by the line I already had in userContent.css,
blink { text-decoration: none ! important; }
though I doubt that, since that should apply to the blink tag,
not blink styles on other tags.
In any case, the crosshair cursor should make new-window links
sufficiently obvious, and I expect the blinking (even only on hover)
would have gotten on my nerves before long.
Incidentally, for any web designers reading this (and who isn't,
these days?), links that try to open new browser windows are a
longstanding item on usability guru Jakob Neilsen's Top Ten Mistakes in
Web Design, and he has a good explanation why.
I'm clearly not the only one who hates them.
For a few other mozilla hacks, see
my current userChrome.css
and userContent.css.
Tags: tech, web, mozilla, firefox
[
14:03 Jan 17, 2005
More tech/web |
permalink to this entry |
]
Thu, 13 Jan 2005
For years I've been plagued by having web pages occasionally display
in a really ugly font that looks like some kind of ancient OCR font
blockily scaled up from a bitmap font.
For instance, look at West Valley College
page, or this news page.
I finally discovered today that pages look like this because Mozilla
thinks they're in Cyrillic! In the case of West Valley, their
server is saying in the http headers:
Content-Type: text/html; charset=WINDOWS-1251
-- WINDOWS-1251 is Cyrillic --
but the page itself specifies a Western character set:
<META http-equiv=Content-Type content="text/html; charset=iso-8859-1">
On my system, Mozilla believes the server instead of the page,
and chooses a Cyrillic font to display the page in. Unfortunately,
the Cyrillic font it chooses is extremely bad -- I have good ones
installed, and I can't figure out where this bad one is coming from,
or I'd terminate it with extreme prejudice. It's not even readable
for pages that really are Cyrillic.
The easy solution for a single page is to use Mozilla's View menu:
View->Character Encoding->Western (ISO-8851-1).
Unfortunately, that has to be done again for each new link
I click on the site; there seems to be no way to say "Ignore
this server's bogus charset claims".
The harder way: I sent mail to the contact address on the server
page, and filed bug
278326 on Mozilla's ignoring the page's meta tag (which you'd
think would override the server's default), but it was closed with
the claim that the standard requires that Mozilla give precedence
to the server. (I wonder what IE does?)
At least that finally inspired me to install Mozilla 1.8a6, which
I'd downloaded a few days ago but hadn't installed yet, to verify
that it saw the same charset. It did, but almost immediately I hit
a worse bug: now mozilla -remote always opens a new window,
even if new-tab or no directive at all is specified.
The release notes have nothing matching "remote, but
someone had already filed bug
276808.
Tags: tech, web, fonts, linux
[
20:15 Jan 13, 2005
More tech/web |
permalink to this entry |
]
Wed, 05 Jan 2005
January 8, just a few days away, is the revised deadline in the
California antitrust
class-action settlement against Microsoft, according to this
NYT
article (soul-sucking registration required, or use
BugMeNot).
Anyone in California who bought Windows (even if it was bundled on a PC),
DOS, MS Office, Works, or similar products between February 18, 1995 and
December 15, 2001 is eligible for a rebate,
in the form of a voucher redeemable for any tech hardware or
software, not just Microsoft products.
Microsoft gets to keep 1/3 of the settlement left unclaimed,
so claim the money you're entitled to now before it's too late!
Go to microsoftcalsettlement.com
to fill out your claim form.
Tags: tech
[
22:58 Jan 05, 2005
More tech |
permalink to this entry |
]
An article in the
LA Times on New Year's Day caught my eye:
California has an anti-spyware law going into effect as of January 1.
The
Times was rather sketchy, though, on what constitutes
spyware, though they did say that there were no actual penalties
under the law, merely that the law makes it possible to sue a
company for installing spyware (whatever that's defined to be).
I've seen it covered in other publications now as well, and
every article I read defines spyware differently,
without mentioning how the actual law defines it
(which you might think would be somewhat relevant).
Nor do any of them provide, or link to, the text of the law,
or its number in the CA code.
It turns out the bill was SB 1436, with a history
here: and here
is the text of the bill.
It amends section 22947 of the Business and Professions code:
here's an
attempt at a link to the actual law, but if that doesn't work,
go to leginfo
and search for 22947 in the Business and Professions code.
It's fairly concise and readable.
One point which on which I've long been curious is whether
the various proposed anti-spyware laws cover the invasive end user
license agreements, or EULAs,
which Microsoft, Apple and other software companies love so much
these days. You know, "clicking here gives you permission for
us to snoop on what files you have on your system, what songs you've
been listening to, and what extra software you have installed, and
you have to click here or you can't get security updates"
(stories on Win2k,
WinXP,
and issues
with Windows Media Player; I think Apple does similar things with
iTunes but don't have any story links handy).
It turns out that SB 1436 specifically disallows
collection of a user's web browsing history, or browser bookmarks
(so google search might be in trouble, depending on how it works)
because it's "personal information", along with your name, address
and credit card information;
but it says nothing against collection of information regarding files,
installed software, music, movies, or email. I guess none of those
constitute "personal information" and it's fine to sneak software onto
your system to collect such details.
However, consider this interesting section:
22947.4. (a) A person or entity, who is not an authorized user,
as defined in Section 22947.1, shall not do any of the following with
regard to the computer of a consumer in this state:
(1) Induce an authorized user to install a software component onto
the computer by intentionally misrepresenting that installing
software is necessary for security or privacy reasons or in order to
open, view, or play a particular type of content.
At issue here is the definition of "software component". If a system
update installs a new media player with a new invasive EULA which
suggests that the player may collect information on songs installed or
played, under the aegis of a security update, wouldn't this fall afoul
of the new law?
22947.2 (c) is also interesting:
[an entity who is not the owner or authorized user of a computer shall not]
Prevent, without the authorization of an authorized user,
through intentionally deceptive means, an authorized user's
reasonable efforts to block the installation of, or to disable,
software, by causing software that the authorized user has properly
removed or disabled to automatically reinstall or reactivate on the
computer without the authorization of an authorized user.
If you've ever disabled a feature in a piece of software,
only to have it mysteriously re-enable itself the next time
you updated the software, or if you use software whose EULA
allows that, you may have grounds to sue if you
can prove that it was re-enabled intentionally. This may be a bit
farther than the authors of the bill really intended to go; quite a
lot of software companies (and perhaps some freeware and open source
authors as well) may be exposed here. Software providers beware!
SB 1436 has some good and non-controversial effects.
It explicitly makes it illegal to install, without the user's knowledge:
keystroke loggers (presumably this does not apply to the CIA or
anyone else operating under the Patriot Act), spam email relays,
denial-of-service zombies, multiple popup ads which can't be closed
(we're in 22947.3 (a) now, which applies to software copied onto the
user's computer; but this may apply even to Javascript on a web page,
if you read the definitions at the beginning of the bill).
All good things to disallow.
What about that no-penalty comment in the Times?
As far as I can tell, they're right.
SB1436 makes no mention of fines or other punishments.
This
Infotex post says there's a $1000 fine per incident, plus
attorney's fees; but I can't figure out where they're getting that:
I don't see it in either the bill or the law anywhere.
Tags: tech
[
11:45 Jan 05, 2005
More tech |
permalink to this entry |
]
Thu, 25 Nov 2004
For years I've been using CD-R for backups, especially of photos.
Every now and then I see an article about CD longevity (people are
all over the map about how long these things are supposed to last;
here's
one useful article)
and wonder if I should worry.
It turns out the answer is yes. Yesterday I was looking for some
photos from mid-2001, and discovered that about 80% of the files on
the CD wouldn't read in my DVD reader -- "I/O error". Fortunately,
my DVD writer could read about 80% of the files (maybe it's a little
slower, or something? Or just newer?)
A subsequent flurry of copying my older CD-Rs found read errors on
many discs two and three years old.
The two worst both had sticky labels on them.
In one case (some images I didn't want to lose), I burned two
copies of the same disc, printed a pretty label on one and marked
the other with a Sharpie. The Sharpie disc read fine; the
labelled disc had massive errors and was all but unreadable.
The advice saying not to print labels for CDs meant for
backup appears to be accurate; but even without labels,
they're not reliable.
I'm not sure of a better backup solution, though. I don't trust
longevity for anything magnetic (I've seen too many tapes and floppies fail).
One solution I'm trying is an IDE disk sitting in an external
USB2/firewire enclosure: it can stay powered off most of the
time, and copies are fast. But a disk has a lot of failure modes
(magnetics, head crash, motor). Safer would be two external drives,
kept in sync.
Tags: tech
[
14:40 Nov 25, 2004
More misc |
permalink to this entry |
]
Sat, 07 Aug 2004
The Mozilla Dev Conference yesterday went well. Shaver and Brendan
showed off a new implementation they'd hacked up with Stuart allowing
drawing into a graphics area from JavaScript, modelled after Apple's
Canvas API. The API looked pretty simple from the code snippet they
showed briefly, with commands for line, polygon, fill, and so forth.
It also included full transparency support.
This is all implemented in terms of Cairo.
Someone asked how this compared to SVG. The answer was to think of
Canvas as an image you can change from JS -- simpler than an SVG
document.
Brendan was funny, playing Vanna as Shaver did the brunt of the
talking. "Ooh, that's pretty. What's that?"
Roc then gave a talk on "New Rendering Features for Gecko".
Probably what attracted the most interest there was transparency:
he has a new hack (not yet checked in) where you can add a parameter
to a XUL window to make it transparent. X only supports 1-bit
transparency, but in Windows implementation XUL windows can be
fully transparent.
He began his talk talking about Cairo and about the changed hardware
expectations these days. He stated that everyone has 3D now, or at
least, anyone who doesn't, doesn't care about rendering and doesn't
expect much. I found that rather disturbing, given that I sure
don't want to see rendering stop working well on my laptop, and
I'd hate to see Mozilla ignore education, developing countries and
other markets where open source on cheap hardware is starting to
gain a strong foothold.
The other bothersome thing Roc talked about was high-res displays.
He mentioned people at IBM and other places using 200dpi displays,
which (as anyone who's used even 100dpi and has imperfect vision
knows) leads to tiny text and other display problems on a lot of
pages due to the ubiquity of page designers who use pixel-based
sizing. Roc's answer to this was to have an automatic x2 or x3
zoom for people at high resolutions like 200dpi. This seems to
me a very poor solution: text will either be too big or too small,
and images will be scaled weirdly. Perhaps if it's implemented as
a smart font size scaling, without any mandatory image scaling, it
could be helpful. I wish more work were going into Mozilla's text
scaling, rather than things like automatic 2x zooms. Maybe this
will be part of the work. Guess I need to seek out the bugs and get
involved before I worry too much about right or wrong solutions.
Then AaronL gave his accessibility talk, stressing that
"accessibility helps everybody" and that the minimum everyone should
do is check pages and new XUL objects for keyboard accessibility.
He talked a bit about how screen reading software works, with a demo,
color-blindness issues (don't ever use color as the only cue), and
accessibility problems with the current fad of implementing fake
menus using JS and DHTML (such menus are almost never accessible to
screen reading software, and often can't be triggered with keyboard
events either). Hopefully awareness of these issues will increase
as legislation mandates better accessibility. Aaron's talk was
unfortunately cut short because he was scheduled as the last talk
before lunch; people seemed interested and there was a lot of
information on his slides which got skipped due to time constraints.
After lunch, Nigel spoke on writing XUL applications, Bob Clary
presented an automated site testing tool he'd written (which runs
in Mozilla) to validate HTML, CSS and JS, roc spoke again on the
question of how backwards compatible and quirk-compatible Mozilla
should be, Myk presented his RSS reading addition to Thunderbird
mail, Pav gave a longer demo of the Cairo Canvas, and several
other demos were presented.
Tags: tech, web, mozilla
[
11:30 Aug 07, 2004
More tech/web |
permalink to this entry |
]
![[spam that the blog owner didn't see]](http://shallowsky.com/blog/images/screenshots/blogseo.jpg)
![[Bing in Omniweb thinks we're in Portugal]](http://shallowsky.com/blog/images/screenshots/omnigal.jpg)
{kind=link}
{kind=link}