Shallow Thoughts : tags : web
Akkana's Musings on Open Source Computing and Technology, Science, and Nature.
Wed, 26 Mar 2025
Michael Kennedy
asked
whether people are using search engines less because of AI chatbots.
I haven't really gotten into using AI chatbots as coding assistants,
so I'm not one to say. But it did make me wonder how many searches I do.
Michael saw a stat that people average fewer than 300 searches per month;
he thought that was absurdly low until he checked his own stats and
found he'd only made 211 searches so far in March.
(Of course, March isn't over yet.
He didn't give a search number for a complete month.)
Read more ...
Tags: tech, firefox, web, python, google, sqlite
[
16:07 Mar 26, 2025
More tech |
permalink to this entry |
]
Thu, 22 Feb 2024
I maintain quite a few small websites. I have several of my own under
different domains (shallowsky.com, nmbilltracker.com and so forth),
plus a few smaller projects like flask apps running on a different port.
In addition, I maintain websites for several organizations on a volunteer
basis (because if you join any volunteer organization and they find out
you're at all technical, that's the first job they want you to do).
I typically maintain a local copy of each website, so I can try out
any change locally first.
Read more ...
Tags: web, shell, programming
[
16:18 Feb 22, 2024
More linux |
permalink to this entry |
]
Thu, 22 Jun 2023
Someone contacted me because my
Galilean Moons
of Jupiter page stopped working.
We've been upgrading the web server to the latest Debian, Bookworm
(we were actually two revs back, on Buster, rather than on Bullseye,
due to excessive laziness) and there have been several glitches that I
had to fix, particularly with the apache2 configuration.
But Galilean? That's just a bunch of JavaScript, no server-side
involvement like Flask or PHP or CGI.
Read more ...
Tags: web, javascript, apache
[
13:53 Jun 22, 2023
More linux |
permalink to this entry |
]
Thu, 13 Apr 2023
Last week I spent some time monitoring my apache error logs to try to
get rid of warnings from my website and see if there are any errors I
need to fix. (Answer: yes, there were a few things I needed to fix,
mostly due to changes in libraries since I wrote the pages in question.)
The vast majority of lines in my error log, however, are requests for
/wp-login.php or /xmlrpc.php. There are so many of them
that they drown out any actual errors on the website.
Read more ...
Tags: web, apache
[
10:28 Apr 13, 2023
More tech/web |
permalink to this entry |
]
Tue, 10 Jan 2023
I wanted to find something I'd googled for recently.
That should be easy, right? Just go to the browser's history window.
Well, actually not so much.
You can see them in Firefox's history window, but they're interspersed
with all the other places you've surfed so it's hard to skim the list quickly.
I decided to take a little time and figure out how to extract the
search terms. I was pretty sure that they were in places.sqlite3
inside the firefox profile. And they were.
Read more ...
Tags: web, firefox, google, sqlite
[
16:54 Jan 10, 2023
More tech/web |
permalink to this entry |
]
Sat, 29 Jan 2022
Firefox's zoom settings are useful. You can zoom in on a page with
Ctrl-+ (actually Ctrl-+ on a US-English keyboard), or out with Ctrl--.
Useful, that is, until you start noticing that lots of pages you
visit have weirdly large or small font sizes, and it turns out that
Firefox is remembering a Zoom setting you used on that site
half a year ago on a different monitor.
Whenever you zoom, Firefox remembers that site, and uses that
zoom setting any time you go to that site forevermore (unless you
zoom back out).
Now that I'm using the same laptop in different modes —
sometimes plugged into a monitor, sometimes using its own screen —
that has become a problem.
Read more ...
Tags: web, firefox, sql, database
[
18:04 Jan 29, 2022
More tech/web |
permalink to this entry |
]
Sun, 12 Dec 2021
I've spent a lot of the past week battling Russian spammers on
the New Mexico Bill Tracker.
The New Mexico legislature just began a special session to define the
new voting districts, which happens every 10 years after the census.
When new legislative sessions start, the BillTracker usually needs
some hand-holding to make sure it's tracking the new session. (I've
been working on code to make it notice new sessions automatically, but
it's not fully working yet). So when the session started, I checked
the log files...
and found them full of Russian spam.
Specifically, what was happening was that a bot was going to my
new user registration page and creating new accounts where the
username was a paragraph of Cyrillic spam.
Read more ...
Tags: web, tech, spam, programming, python, flask, captcha
[
18:50 Dec 12, 2021
More tech/web |
permalink to this entry |
]
Mon, 15 Nov 2021
A priest, a minister, and a rabbit walk into a bar.
The bartender asks the rabbit what he'll have to drink.
"How should I know?" says the rabbit. "I'm only here because of autocomplete."
Firefox folks like to call the location bar/URL bar the "awesomebar"
because of the suggestions it makes. Sometimes, those suggestions
are pretty great; there are a lot of sites I don't bother to bookmark
because I know they will show up as the first suggestion.
Other times, the "awesomebar" not so awesome. It gets stuck on some site
I never use, and there's seemingly no way to make Firefox forget that site.
Read more ...
Tags: web, firefox, sql
[
16:54 Nov 15, 2021
More tech/web |
permalink to this entry |
]
Fri, 06 Aug 2021
I maintain quite a few domains, both domains I own and domains
belonging to various nonprofits I belong to.
For testing these websites, I make virtual domains in apache,
choosing an alias for each site.
For instance, for the LWVNM website, the apache site file has
<VirtualHost *:80>
ServerName lwvlocal
and my host table,
/etc/hosts, has
127.0.0.1 localhost lwvlocal
(The
localhost line in my host table has entries for
all the various virtual hosts I use, not just this one).
That all used to work fine. If I wanted to test a new page on the LWVNM
website, I'd go to Firefox's urlbar and type something like
lwvlocal/newpage.html
and it would show me the new page, which I could work on until
it was time to push it to the web server.
A month or so ago, a new update to Firefox broke that.
Read more ...
Tags: firefox, web
[
13:34 Aug 06, 2021
More tech/web |
permalink to this entry |
]
Sun, 06 Jun 2021
![[analemma webapp]](/blog/images/screenshots/analemma-preview.jpg) I have another PEEC Planetarium talk coming up in a few weeks,
a talk on the
summer solstice
co-presenting with Chick Keller on Fri, Jun 18 at 7pm MDT.
I have another PEEC Planetarium talk coming up in a few weeks,
a talk on the
summer solstice
co-presenting with Chick Keller on Fri, Jun 18 at 7pm MDT.
I'm letting Chick do most of the talking about archaeoastronomy
since he knows a lot more about it than I do, while I'll be talking
about the celestial dynamics -- what is a solstice, what is the sun
doing in our sky and why would you care, and some weirdnesses relating
to sunrise and sunset times and the length of the day.
And of course I'll be talking about the analemma, because
just try to stop me talking about analemmas whenever the topic
of the sun's motion comes up.
But besides the analemma, I need a lot of graphics of the earth
showing the terminator, the dividing line between day and night.
Read more ...
Tags: science, astronomy, programming, javascript, web
[
18:33 Jun 06, 2021
More science/astro |
permalink to this entry |
]
Tue, 30 Mar 2021
In my eternal quest for a decent RSS feed for top World/National news,
I decided to try subscribing to the New York Times online.
But when I went to try to add them to my RSS reader, I discovered
it wasn't that easy: their login page sometimes gives a captcha, so
you can't just set a username and password in the RSS reader.
A common technique for sites like this is to log in with a browser,
then copy the browser's cookies into your news reading program.
At least, I thought it was a common technique -- but when I tried
a web search, examples were surprisingly hard to find.
None of the techniques to examine or save browser cookies were all
that simple, so I ended up writing a
browser_cookies.py
Python script to extract cookies from chromium and firefox browsers.
Read more ...
Tags: web, programming, python, cookies, privacy
[
11:19 Mar 30, 2021
More programming |
permalink to this entry |
]
Sat, 08 Aug 2020
It's been a frustration with Firefox for years. You click on a link
and get the "What should Firefox do with this file?" dialog, even
though it's a file type you view all the time -- PDF, say, or JPEG.
You click "View in browser" or "Save file" or whatever ... then you
check the "Do this automatically for files like this from now on"
checkbox, thinking, I'm sure I checked this last time.
Then a few minutes later, you go to a file of the exact same time,
and you get the dialog again. That damn checkbox is like the button
on street crossings or elevators: a no-op to make you think you're
doing something.
I never tried to get to the bottom
of why this happens with some PDFs and not others, some JPGs but not others.
But Los Alamos puts their government meetings on a site called
Legistar.
Legistar does everything as PDF -- and those PDFs all trigger this
Firefox bug, prompting for a download rather than displaying in
Firefox's PDF viewer.
Read more ...
Tags: firefox, web, privacy
[
16:38 Aug 08, 2020
More tech/web |
permalink to this entry |
]
Thu, 09 Jan 2020
I wrote about
various ways of managing a persistent popup window from Javascript,
eventually settling on a postMessage() solution that
turned out not to work in QtWebEngine. So I needed another solution.
Data URI
First I tried using a data: URI.
In that scheme, you encode a page's full content into the URL. For instance:
try this in your browser:
data:text/html,Hello%2C%20World!
So for a longer page, you can do something like:
var htmlhead = '<html>\n'
+ '<head>\n'
+ '<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">\n'
+ '<link rel="stylesheet" type="text/css" href="stylesheet.css">\n'
+ '</head>\n'
+ '\n'
+ '<body>\n'
+ '<div id="mydiv">\n';
var htmltail = '</div>\n'
+ '</body>\n'
+ '</html>\n';
var encodedDataURI = encodeURI(htmlhead + noteText + htmltail);
var notewin = window.open('data:text/html,' + encodedDataURI, "notewindow",
"width=800,height=500");
Nice and easy -- and it even works from file: URIs!
Well, sort of works. It turns out it has a problem related to
the same-origin problems I saw with postMessage.
A data: URI is always opened with an origin of about:blank;
and two about:blank origin pages can't talk to each other.
But I don't need them to talk to each other if I'm not using postMessage,
do I? Yes, I do.
The problem is that stylesheet I included in htmlhead above:
<link rel="stylesheet" type="text/css" href="stylesheet.css">\n'
All browsers I tested refuse to open the stylesheet in the
about:blank popup. This seems strange: don't people use stylesheets
from other domains fairly often? Maybe it's a behavior special to
null (about:blank) origin pages. But in any case, I couldn't find
a way to get my data: URI popup to load a stylesheet. So unless I
hard-code all the styles I want for the notes page into the Javascript
that opens the popup window (and I'd really rather not do that),
I can't use
data: as a solution.
Clever hack: Use the Same Page, Loaded in a Different Way
That's when I finally came across
Remy Sharp's page, Creating popups without HTML files.
Remy first explores the data: URI solution, and rejects it because of
the cross-origin problem, just as I did. But then he comes up with a
clever hack. It's ugly, as he acknowledges ... but it works.
The trick is to create the popup with the URL of the parent page that
created it, but with a named anchor appended:
parentPage.html#popup.
Then, in the Javascript, check whether #popup is in the
URL. If not, we're in the parent page and still need to call
window.open to create the popup. If it is there, then
the JS code is being executed in the popup. In that case, rewrite the
page as needed. In my case, since I want the popup to show only whatever
is in the div named #notes, and the slide content is all inside a div
called #page, I can do this:
function updateNoteWindow() {
if (window.location.hash.indexOf('#notes') === -1) {
window.open(window.location + '#notes', 'noteWin',
'width=300,height=300');
return;
}
// If here, it's the popup notes window.
// Remove the #page div
var pageDiv = document.getElementById("page");
pageDiv.remove();
// and rename the #notes div so it will be displayed in a different place
var notesDiv = document.getElementById("notes");
notesDiv.id = "fullnotes";
}
It works great, even in file: URIs, and even in QtWebEngine.
That's the solution I ended up using.
Tags: programming, web, javascript
[
19:44 Jan 09, 2020
More tech/web |
permalink to this entry |
]
Sun, 05 Jan 2020
I'm trying to update my
htmlpreso
HTML presentation slide system to allow for a separate notes window.
Up to now, I've just used display mirroring. I connect to the
projector at 1024x768, and whatever is on the first (topmost/leftmost)
1024x768 pixels of my laptop screen shows on the projector. Since my
laptop screen is wider than 1024 pixels, I can put notes to myself
to the right of the slide, and I'll see them but the audience won't.
That works fine, but I'd like to be able to make the screens completely
separate, so I can fiddle around with other things while still
displaying a slide on the projector. But since my slides are in HTML,
and I still want my presenter notes, that requires putting the notes
in a separate window, instead of just to the right of each slide.
The notes for each slide are in a <div id="notes">
on each page. So all I have to do is pop up another browser window
and mirror whatever is in that div to the new window, right?
Sure ...
except this is JavaScript, so nothing is simple. Every little thing
is going to be multiple days of hair-tearing frustration, and this
was no exception.
I should warn you up front that I eventually found a much simpler way
of doing this. I'm documenting this method anyway because it seems
useful to be able to communicate between two windows, but if you
just want a simple solution for the "pop up notes in another window"
problem, stay tuned for Part 2.
Step 0: Give Up On file:
Normally I use file: URLs for presentations. There's no need
to run a web server, and in fact, on my lightweight netbook I usually
don't start apache2 by default, only if I'm actually working on
web development.
But most of the methods of communicating between windows don't work in
file URLs, because of the "same-origin policy".
That policy is a good security measure: it ensures that a page
from innocent-url.com can't start popping up windows with content
from evilp0wnU.com without you knowing about it. I'm good with that.
The problem is that file: URLs have location.origin
of null, and every null-origin window is considered to be a
different origin -- even if they're both from the same directory. That
makes no sense to me, but there seems to be no way around it. So if I
want notes in a separate window, I have to run a web server and use
http://localhost.
Step 1: A Separate Window
The first step is to pop up the separate notes window, or get a
handle to it if it's already up.
JavaScript offers window.open(), but there's a trick:
if you just call
notewin = window.open("notewin.html", "notewindow")
you'll actually get a new tab, not a new window. If you actually
want a window, the secret code for that is to give it a size:
notewin = window.open("notewin.html", "notewindow",
"width=800,height=500");
There's apparently no way to just get a handle to an existing window.
The only way is to call window.open(),
pop up a new window if it wasn't there before, or reloads it if it's
already there.
I saw some articles implying that passing an empty string ""
as the first argument would return a handle to an existing window without
changing it, but it's not true: in Firefox and Chromium, at least,
that makes the existing window load about:blank instead of
whatever page it already has. So just give it the same page every time.
Step 2: Figure Out When the Window Has Loaded
There are several ways to change the content in the popup window from
the parent, but they all have one problem:
if you update the content right away after calling window.open,
whatever content you put there will be overwritten immediately when
the popup reloads its notewin.html page (or even about:blank).
So you need to wait until the popup is finished loading.
That sounds suspiciously easy. Assuming you have a function called
updateNoteWinContent(), just do this:
// XXX This Doesn't work:
notewin.addEventListener('load', updateNoteWinContent, false);
Except it turns out the "load" event listener isn't called on reloads,
at least not in popups.
So this will work the first time, when the
note window first pops up, but never after that.
I tried other listeners, like "DOMContentLoaded" and
"readystatechange", but none of them are called on reload.
Why not? Who knows?
It's possible this is because the listener gets set too early, and
then is wiped out when the page reloads, but that's just idle
speculation.
For a while, I thought I was going to have to resort to an ugly hack:
sleep for several seconds in the parent window to give the popup time
to load:
await new Promise(r => setTimeout(r, 3000));
(requires declaring the calling function as async).
This works, but ... ick.
Fortunately, there's a better way.
Step 2.5: Simulate onLoad with postMessage
What finally worked was a tricky way to use postMessage()
in reverse. I'd already experimented with using postMessage()
from the parent window to the popup, but it didn't work because the
popup was still loading and wasn't ready for the content.
What works is to go the other way. In the code loaded by the popup
(notewin.html in this example), put some code at the end
of the page that calls
window.opener.postMessage("Loaded");
Then in the parent, handle that message, and don't try to update the
popup's content until you've gotten the message:
function receiveMessageFromPopup(event) {
console.log("Parent received a message from the notewin:", event.data);
// Optionally, check whether event.data == "Loaded"
// if you want to support more than one possible message.
// Update the "notes" div in the popup notewin:
var noteDiv = notewin.document.getElementById("notes");
noteDiv.innerHTML = "Here is some content.
";
}
window.addEventListener("message", receiveMessageFromPopup, false);
Here's a complete working test:
Test of
Persistent Popup Window.
In the end, though, this didn't solve my presentation problem.
I got it all debugged and working, only to discover that
postMessage doesn't work in QtWebEngine, so
I couldn't use it in my slide presentation app.
Fortunately, I found a couple of other ways: stay tuned for Part 2.
(Update: Part 2: A Clever Hack.)
Debugging Multiple Windows: Separate Consoles
A note on debugging:
One thing that slowed me down was that JS I put in the popup didn't
seem to be running: I never saw its console.log() messages.
It took me a while to realize that each window has its own web console,
both in Firefox and Chromium. So you have to wait until the popup has
opened before you can see any debugging messages for it. Even then,
the popup window doesn't have a menu, and its context menu doesn't
offer a console window option. But it does offer Inspect element,
which brings up a Developer Tools window where you can click on
the Console tab to see errors and debugging messages.
Tags: programming, web, javascript
[
20:29 Jan 05, 2020
More tech/web |
permalink to this entry |
]
Thu, 10 Jan 2019
Years ago, I saw someone demonstrating an obscure slide presentation
system, and one of the tricks it had was to let you draw on slides
with the mouse. So you could underline or arrow specific points,
or, more important (since underlines and arrows are easily included
in slides), draw something in response to an audience question.
Neat feature, but there were other reasons I didn't want to switch to
that particular slide system.
Many years later, and quite happy with my home-grown
htmlpreso system
for HTML-based slides, I was sitting in an astronomy panel discussion
listening to someone explain black holes when it occurred to me:
with HTML Canvas being a fairly mature technology, how hard could
it be to add drawing to my htmlpreso setup? It would just take a javascript
snippet that creates a canvas on top of the existing slide, plus
some basic event handling and drawing code that surely someone else
has already written.
![[Drawing on top of an HTML slide]](http://shallowsky.com/blog/images/screenshots/htmlpreso-drawing.jpg)
Curled up in front of the fire last night with my laptop, it only took a
couple of hours to whip up a proof of concept that seems remarkably usable.
I've added it to htmlpreso.
I have to confess, I've never actually felt the need to draw on a slide
during a talk. But I still love knowing that it's possible.
It'll be interesting to see how often I actually use it.
To play with drawing on slides, go to my
HTMLPreso
self-documenting slide set (with JavaScript enabled)
and, on any slide, type Shift-D.
Some color swatches should appear in the upper right of the slide,
and now you can scribble over the tops of slides to your heart's content.
Tags: talks, programming, web
[
14:39 Jan 10, 2019
More speaking |
permalink to this entry |
]
Sun, 29 Jul 2018
In my several recent articles about building Firefox from source,
I omitted one minor change I made, which will probably sound a bit silly.
A self-built Firefox thinks its name is "Nightly", so, for example,
the Help menu includes About Nightly.
Somehow I found that unreasonably irritating. It's not
a nightly build; in fact, I hope to build it as seldom as possible,
ideally only after a git pull when new versions are released.
Yet Firefox shows its name in quite a few places, so you're constantly
faced with that "Nightly". After all the work to build Firefox,
why put up with that?
To find where it was coming from,
I used my recursive grep alias which skips the obj- directory plus
things like object files and metadata. This is how I define it in my .zshrc
(obviously, not all of these clauses are necessary for this Firefox
search), and then how I called it to try to find instances of
"Nightly" in the source:
gr() {
find . \( -type f -and -not -name '*.o' -and -not -name '*.so' -and -not -name '*.a' -and -not -name '*.pyc' -and -not -name '*.jpg' -and -not -name '*.JPG' -and -not -name '*.png' -and -not -name '*.xcf*' -and -not -name '*.gmo' -and -not -name '.intltool*' -and -not -name '*.po' -and -not -name 'po' -and -not -name '*.tar*' -and -not -name '*.zip' -or -name '.metadata' -or -name 'build' -or -name 'obj-*' -or -name '.git' -or -name '.svn' -prune \) -print0 | xargs -0 grep $* /dev/null
}
gr Nightly | grep -v '//' | grep -v '#' | grep -v isNightly | grep test | grep -v task | fgrep -v .js | fgrep -v .cpp | grep -v mobile >grep.out
Even with all those exclusions, that still ends up printing
an enormous list. But it turns out all the important hits
are in the browser directory, so you can get away with
running it from there rather than from the top level.
I found a bunch of likely files that all had very similar
"Nightly" lines in them:
- browser/branding/nightly/branding.nsi
- browser/branding/nightly/configure.sh
- browser/branding/nightly/locales/en-US/brand.dtd
- browser/branding/nightly/locales/en-US/brand.ftl
- browser/branding/nightly/locales/en-US/brand.properties
- browser/branding/unofficial/configure.sh
- browser/branding/unofficial/locales/en-US/brand.dtd
- browser/branding/unofficial/locales/en-US/brand.properties
- browser/branding/unofficial/locales/en-US/brand.ftl
Since I didn't know which one was relevant, I changed each of them to
slightly different names, then rebuilt and checked to see which names
I actually saw while running the browser.
It turned out that
browser/branding/unofficial/locales/en-US/brand.dtd
is the file that controls the application name in the Help menu
and in Help->About -- though the title of the
About window is still "Nightly" and I haven't found what controls that.
branding/unofficial/locales/en-US/brand.ftl controls the
"Nightly" references in the Edit->Preferences window.
I don't know what all the others do.
There may be other instances of "Nightly" that appear elsewhere in the app,
the other files, but I haven't seen them yet.
Past Firefox building articles:
Building Firefox Quantum;
Building Firefox for ALSA (non PulseAudio) Sound;
Firefox Quantum: Fixing Ctrl W (or other key bindings).
Tags: firefox, web, build, programming
[
18:23 Jul 29, 2018
More tech/web |
permalink to this entry |
]
Sat, 07 Jul 2018
A quick followup to my article on
Modifying
Firefox Files Inside omni.ja:
The steps for modifying the file are fairly easy, but they have to be
done a lot.
First there's the problem of Firefox updates: if a new omni.ja
is part of the update, then your changes will be overwritten, so
you'll have to make them again on the new omni.ja.
But, worse, even aside from updates they don't stay changed.
I've had Ctrl-W mysteriously revert back to its old wired-in
behavior in the middle of a Firefox session. I'm still not clear
how this happens: I speculate that something in Firefox's update mechanism
may allow parts of omni.ja to be overridden, even though I was
told by Mike Kaply, the onetime master of overlays, that they
weren't recommended any more (at least by users, though that doesn't
necessarily mean they're not used for updates).
But in any case, you can be browsing merrily along and suddenly one
of your changes doesn't work any more, even though the change is still
right there in browser/omni.ja. And the only fix I've found
so far is to download a new Firefox and re-apply the changes.
Re-applying them to the current version doesn't work -- they're
already there. And it doesn't help to keep the tarball you originally
downloaded around so you can re-install that; firefox updates every
week or two so that version is guaranteed to be out of date.
All this means that it's crazy not to script the omni changes so
you can apply them easily with a single command. So here's a shell
script that takes the path to the current Firefox, unpacks
browser/omni.ja, makes a couple of simple changes and
re-packs it. I called it
kitfox-patch
since I used to call my personally modified Firefox build "Kitfox".
Of course, if your changes are different from mine
you'll want to edit the script to change the sed commands.
I hope eventually to figure out how it is that omni.ja changes
stop working, and whether it's an overlay or something else,
and whether there's a way to re-apply fixes without having to
download a whole new Firefox.
If I figure it out I'll report back.
Tags: firefox, web
[
15:01 Jul 07, 2018
More tech/web |
permalink to this entry |
]
Sat, 23 Jun 2018
My article on
Fixing
key bindings in Firefox Quantum by modifying the source tree got
attention from several people who offered helpful suggestions via
Twitter and email on how
to accomplish the same thing using just files in omni.ja,
so it could be done without rebuilding the Firefox source.
That would be vastly better, especially for people who need to
change something like key bindings or browser messages but don't
have a souped-up development machine to build the whole browser.
Brian Carpenter had several suggestions and eventually pointed me to
an old post by Mike Kaply,
Don’t Unpack and Repack omni.ja[r]
that said there were better ways to override specific files.
Unfortunately, Mike Kaply responded that that article was written
for XUL extensions, which are now obsolete, so the article
ought to be removed. That's too bad, because it did sound like a much
nicer solution. I looked into trying it anyway, but the instructions
it points to for
Overriding
specific files is woefully short on detail on how to map a path
inside omni.ja like chrome://package/type/original-uri.whatever,
to a URL, and the single example I could find was so old that the file
it referenced didn't exist at the same location any more. After a fruitless
half hour or so, I took Mike's warning to heart and decided it wasn't
worth wasting more time chasing something that wasn't expected to work
anyway. (If someone knows otherwise, please let me know!)
But then Paul Wise offered a solution that actually worked, as an
easy to follow sequence of shell commands. (I've changed some of
them very slightly.)
$ tar xf ~/Tarballs/firefox-60.0.2.tar.bz2
# (This creates a "firefox" directory inside the current one.)
$ mkdir omni
$ cd omni
$ unzip -q ../firefox/browser/omni.ja
warning [../firefox-60.0.2/browser/omni.ja]: 34187320 extra bytes at beginning or within zipfile
(attempting to process anyway)
error [../firefox-60.0.2/browser/omni.ja]: reported length of central directory is
-34187320 bytes too long (Atari STZip zipfile? J.H.Holm ZIPSPLIT 1.1
zipfile?). Compensating...
zsh: exit 2 unzip -q ../firefox-60.0.2/browser/omni.ja
$ sed -i 's/or enter address/or just twiddle your thumbs/' chrome/en-US/locale/browser/browser.dtd chrome/en-US/locale/browser/browser.properties
I was a little put off by all the warnings unzip gave, but kept going.
Of course, you can just edit those two files rather than using sed;
but the sed command was Paul's way of being very specific about
the changes he was suggesting, which I appreciated.
Use these flags to repackage omni.ja:
$ zip -qr9XD ../omni.ja *
I had tried that before (without the q since I like to see what zip
and tar commands are doing) and hadn't succeeded. And indeed, when I
listed the two files, the new omni.ja I'd just packaged was
about a third the size of the original:
$ ls -l ../omni.ja ../firefox-60.0.2/browser/omni.ja
-rw-r--r-- 1 akkana akkana 34469045 Jun 5 12:14 ../firefox/browser/omni.ja
-rw-r--r-- 1 akkana akkana 11828315 Jun 17 10:37 ../omni.ja
But still, it's worth a try:
$ cp ../omni.ja ../firefox/browser/omni.ja
Then run the new Firefox. I have a spare profile I keep around for
testing, but Paul's instructions included a nifty way of running with
a brand new profile and it's definitely worth knowing:
$ cd ../firefox
$ MOZILLA_DISABLE_PLUGINS=1 ./firefox -safe-mode -no-remote -profile $(mktemp -d tmp-firefox-profile-XXXXXXXXXX) -offline about:blank
Also note the flags like safe-mode and no-remote, plus disabling
plugins -- all good ideas when testing something new.
And it worked! When I started up, I got the new message, "Search or
just twiddle your thumbs", in the URL bar.
Fixing Ctrl-W
Of course, now I had to test it with my real change. Since I like Paul's
way of using sed to specify exactly what changes to make, here's a
sed version of my Ctrl-W fix:
$ sed -i '/key_close/s/ reserved="true"//' chrome/browser/content/browser/browser.xul
Then run it. To test Ctrl-W, you need a website that includes a text
field you can type in, so -offline isn't an option unless you
happen to have a local web page that includes some text fields.
Google is an easy way to test ... and you might as well re-use that
firefox profile you just made rather than making another one:
$ MOZILLA_DISABLE_PLUGINS=1 ./firefox -safe-mode -no-remote -profile tmp-firefox-profile-* https://google.com
I typed a few words in the google search field that came up, deleted
them with Ctrl-W -- all was good! Thanks, Paul! And Brian, and
everybody else who sent suggestions.
Why are the sizes so different?
I was still puzzled by that threefold difference in size between the
omni.ja I repacked and the original that comes with Firefox.
Was something missing? Paul had the key to that too: use zipinfo
on both versions of the file to see what differed. Turned out
Mozilla's version, after a long file listing, ends with
2650 files, 33947999 bytes uncompressed, 33947999 bytes compressed: 0.0%
while my re-packaged version ends with
2650 files, 33947969 bytes uncompressed, 11307294 bytes compressed: 66.7%
So apparently Mozilla's omni.ja is using no compression at all.
It may be that that makes it start up a little faster; but Quantum
takes so long to start up that any slight difference in uncompressing
omni.ja isn't noticable to me.
I was able to run through this whole procedure on my poor slow netbook,
the one where building Firefox took something like 15 hours ... and
in a few minutes I had a working modified Firefox. And with the sed
command, this is all scriptable, so it'll be easy to re-do whenever
Firefox has a security update. Win!
Update: I have a simple shell script to do this:
Script to modify omni.ja for a custom Firefox.
Tags: firefox, web
[
20:37 Jun 23, 2018
More tech/web |
permalink to this entry |
]
Sat, 09 Jun 2018
I did the work to
built
my own Firefox primarily to fix a couple of serious regressions
that couldn't be fixed any other way. I'll start with the one that's
probably more common (at least, there are many people complaining
about it in many different web forums): the fact that Firefox won't
play sound on Linux machines that don't use PulseAudio.
There's a bug with a long discussion of the problem,
Bug 1345661 - PulseAudio requirement breaks Firefox on ALSA-only systems;
and the discussion in the bug links to another
discussion
of the Firefox/PulseAudio problem). Some comments in those
discussions suggest that some near-future version of Firefox may
restore ALSA sound for non-Pulse systems; but most of those comments
are six months old, yet it's still not fixed in the version Mozilla
is distributing now.
In theory, ALSA sound is easy to enable.
Build
pptions in Firefox are controlled through a file called mozconfig.
Create that file at the top level of your build directory, then add to it:
ac_add_options --enable-alsa
ac_add_options --disable-pulseaudio
You can see other options with ./configure --help
Of course, like everything else in the computer world, there were
complications. When I typed mach build, I got:
Assertion failed in _parse_loader_output:
Traceback (most recent call last):
File "/home/akkana/outsrc/gecko-dev/python/mozbuild/mozbuild/mozconfig.py", line 260, in read_mozconfig
parsed = self._parse_loader_output(output)
File "/home/akkana/outsrc/gecko-dev/python/mozbuild/mozbuild/mozconfig.py", line 375, in _parse_loader_output
assert not in_variable
AssertionError
Error loading mozconfig: /home/akkana/outsrc/gecko-dev/mozconfig
Evaluation of your mozconfig produced unexpected output. This could be
triggered by a command inside your mozconfig failing or producing some warnings
or error messages. Please change your mozconfig to not error and/or to catch
errors in executed commands.
mozconfig output:
------BEGIN_ENV_BEFORE_SOURCE
... followed by a many-page dump of all my environment variables, twice.
It turned out that was coming from line 449 of
python/mozbuild/mozbuild/mozconfig.py:
# Lines with a quote not ending in a quote are multi-line.
if has_quote and not value.endswith("'"):
in_variable = name
current.append(value)
continue
else:
value = value[:-1] if has_quote else value
I'm guessing this was added because some Mozilla developer sets
a multi-line environment variable that has a quote in it but doesn't
end with a quote. Or something. Anyway, some fairly specific case.
I, on the other hand, have a different specific case: a short
environment variable that includes one or more single quotes,
and the test for their specific case breaks my build.
(In case you're curious why I have quotes in an environment variable:
The prompt-setting code in my .zshrc includes a variable called
PRIMES. In a login shell, this is set to the empty string,
but in subshells, I add ' for each level of shell under the login shell.
So my regular prompt might be (hostname)-, but if I run a
subshell to test something, the prompt will be (hostname')-,
a subshell inside that will be (hostname'')-, and so on.
It's a reminder that I'm still in a subshell and need to exit when
I'm done testing. In theory, I could do that with SHLVL, but SHLVL
doesn't care about login shells, so my normal shells inside X are
all SHLVL=2 while shells on a console or from an ssh are
SHLVL=1, so if I used SHLVL I'd have to have some special case
code to deal with that.
Also, of course I could use a character other than a single-quote.
But in the thirty or so years I've used this, Firefox is the first
program that's ever had a problem with it. And apparently I'm not the
first one to have a problem with this:
bug 1455065
was apparently someone else with the same problem. Maybe that will show
up in the release branch eventually.)
Anyway, disabling that line fixed the problem:
# Lines with a quote not ending in a quote are multi-line.
if False and has_quote and not value.endswith("'"):
and after that,
mach build succeeded, I built a new
Firefox, and lo and behond! I can play sound in YouTube videos and
on Xeno-Canto again, without needing an additional browser.
Tags: web, firefox, linux
[
16:49 Jun 09, 2018
More tech/web |
permalink to this entry |
]
Thu, 31 May 2018
For the last year or so the Firefox development team has been making
life ever harder for users. First they broke all the old extensions
that were based on XUL and XBL, so a lot of customizations no longer
worked. Then they
made
PulseAudio mandatory on Linux bug (1345661), so on systems
like mine that don't run Pulse, there's no way to get sound in
a web page. Forget YouTube or XenoCanto unless you keep another
browser around for that purpose.
For those reasons I'd been avoiding the Firefox upgrade, sticking to
Debian's firefox-esr ("Extended Support Release"). But when
Debian updated firefox-esr to Firefox 56 ESR late last year, performance
became unusable. Like half a minute between when you hit Page Down
and when the page actually scrolls. It was time to switch browsers.
Pale Moon
I'd been hearing about the Firefox variant Pale Moon. It's a fork of
an older Firefox, supposedly with an emphasis on openness and configurability.
I installed the Debian palemoon package. Performance was fine,
similar to Firefox before the tragic firefox-56. It was missing a few
things -- no built-in PDF viewer or Reader mode -- but I don't use
Reader mode that often, and the built-in PDF viewer is an annoyance at
least as often as it's a help. (In Firefox it's fairly random about when
it kicks in anyway, so I'm never sure whether I'll get the PDF viewer
or a Save-as prompt on any given PDF link).
For form and password autofill, for some reason Pale Moon doesn't fill
out fields until you type the first letter. For instance, if I had an
account with name "myname" and a stored password, when I loaded the
page, both fields would be empty, as if there's nothing stored for that
page. But typing an 'm' in the username field makes both username and
password fields fill in. This isn't something Firefox ever did and I
don't particularly like it, but it isn't a major problem.
Then there were some minor irritations, like the fact that profiles
were stored in a folder named ~/.moonchild\ productions/ --
super long so it messed up directory listings, and with a space in the
middle. PaleMoon was also very insistent about using new tabs for
everything, including URLs launched from other programs -- there
doesn't seem to be any way to get it to open URLs in the active tab.
I used it as my main browser for several months, and it basically worked.
But the irritations started to get to me, and I started considering
other options. The final kicker when I saw
Pale Moon
bug 86, in which, as far as I can tell, someone working on the
PaleMoon in OpenBSD tries to use system libraries instead of
PaleMoon's patched libraries, and is attacked for it in the bug.
Reading the exchange made me want to avoid PaleMoon for two reasons.
First, the rudeness: a toxic community that doesn't treat contributors
well isn't likely to last long or to have the resources to keep on top
of bug and security fixes. Second, the technical question: if Pale
Moon's code is so quirky that it can't use standard system libraries
and needs a bunch of custom-patched libraries, what does that say
about how maintainable it will be in the long term?
Firefox Quantum
Much has been made in the technical press of the latest Firefox,
called "Quantum", and its supposed speed. I was a bit dubious of that:
it's easy to make your program seem fast after you force everybody
into a few years of working with a program that's degraded its
performance by an order of magnitude, like Firefox had. After
firefox 56, anything would seem fast.
Still, maybe it would at least be fast enough to be usable. But I had
trepidations too. What about all those extensions that don't work any
more? What about sound not working? Could I live with that?
Debian has no current firefox package, so I downloaded the tarball
from mozilla.org, unpacked it,
made a new firefox profile and ran it.
Initial startup performance is terrible -- it takes forever to bring
up the first window, and I often get a "Firefox seems slow to start up"
message at the bottom of the screen, with a link to a page of a bunch
of completely irrelevant hints.
Still, I typically only start Firefox once a day. Once it's up,
performance is a bit laggy but a lot better than firefox-esr 56 was,
certainly usable.
I was able to find replacements for most of the really important
extensions (the ones that control things like cookies and javascript).
But sound, as predicted, didn't work. And there were several other,
worse regressions from older Firefox versions.
As it turned out, the only way to make Firefox Quantum usable for me
was to build a custom version where I could fix the regressions.
To keep articles from being way too long, I'll write about all those
issues separately:
how to build Firefox,
how to fix broken key bindings,
and how to fix the PulseAudio problem.
Tags: web, firefox
[
16:07 May 31, 2018
More tech/web |
permalink to this entry |
]
Sun, 27 May 2018
After I'd
switched
from the Google Maps API to Leaflet get my trail map
working on my own website,
the next step was to move it to the Nature Center's website
to replace the broken Google Maps version.
PEEC, unfortunately for me, uses Wordpress (on the theory that this
makes it easier for volunteers and non-technical staff to add
content). I am not a Wordpress person at all; to me, systems
like Wordpress and Drupal mostly add obstacles that mean standard HTML
doesn't work right and has to be modified in nonstandard ways.
This was a case in point.
The Leaflet library for displaying maps relies on calling an
initialization function when the body of the page is loaded:
<body onLoad="javascript:init_trailmap();">
But in a Wordpress website, the <body> tag comes
from Wordpress, so you can't edit it to add an onload.
A web search found lots of people wanting body onloads, and
they had found all sorts of elaborate ruses to get around the problem.
Most of the solutions seemed like they involved editing
site-wide Wordpress files to add special case behavior depending
on the page name. That sounded brittle, especially on a site where
I'm not the Wordpress administrator: would I have to figure this out
all over again every time Wordpress got upgraded?
But I found a trick in a Stack Overflow discussion,
Adding onload to body,
that included a tricky bit of code. There's a javascript function to add
an onload to the
tag; then that javascript is wrapped inside a
PHP function. Then, if I'm reading it correctly, The PHP function registers
itself with Wordpress so it will be called when the Wordpress footer is
added; at that point, the PHP will run, which will add the javascript
to the
body tag in time for for the
onload
even to call the Javascript. Yikes!
But it worked.
Here's what I ended up with, in the PHP page that Wordpress was
already calling for the page:
<?php
/* Wordpress doesn't give you access to the <body> tag to add a call
* to init_trailmap(). This is a workaround to dynamically add that tag.
*/
function add_onload() {
?>
<script type="text/javascript">
document.getElementsByTagName('body')[0].onload = init_trailmap;
</script>
<?php
}
add_action( 'wp_footer', 'add_onload' );
?>
Complicated, but it's a nice trick; and it let us switch to Leaflet
and get the
PEEC
interactive Los Alamos area trail map
working again.
Tags: web, programming, javascript, php, wordpress, mapping
[
15:49 May 27, 2018
More tech/web |
permalink to this entry |
]
Thu, 24 May 2018
A while ago I wrote an
interactive
trail map page for the PEEC nature center website.
At the time, I wanted to use an open library, like OpenLayers or Leaflet;
but there were no good sources of satellite/aerial map tiles at the
time. The only one I found didn't work because they had a big blank
area anywhere near LANL -- maybe because of the restricted
airspace around the Lab. Anyway, I figured people would want a
satellite option, so I used Google Maps instead despite its much
more frustrating API.
This week we've been working on converting the website to https.
Most things went surprisingly smoothly (though we had a lot more
absolute URLs in our pages and databases than we'd realized).
But when we got through, I discovered the trail map was broken.
I'm still not clear why, but somehow the change from http to https
made Google's API stop working.
In trying to fix the problem, I discovered that Google's map API
may soon cease to be free:
New pricing and product changes will go into effect starting June 11,
2018. For more information, check out the
Guide for
Existing Users.
That has a button for "Transition Tool" which, when you click it,
won't tell you anything about the new pricing structure until you've
already set up a billing account. Um ... no thanks, Google.
Googling for google maps api billing led to a page headed
"Pricing
that scales to fit your needs", which has an elaborate pricing
structure listing a whole bnch of variants (I have no idea which
of these I was using), of which the first $200/month is free.
But since they insist on setting up a billing account, I'd probably
have to give them a credit card number -- which one? My personal
credit card, for a page that isn't even on my site? Does the nonprofit
nature center even have a credit card? How many of these API calls is
their site likely to get in a month, and what are the chances of going
over the limit?
It all rubbed me the wrong way, especially when the context
of "Your trail maps page that real people actually use has
broken without warning, and will be held hostage until you give usa
credit card number". This is what one gets for using a supposedly free
(as in beer) library that's not Free open source software.
So I replaced Google with the excellent open source
Leaflet library, which, as a
bonus, has much better documentation than Google Maps. (It's not that
Google's documentation is poorly written; it's that they keep changing
their APIs, but there's no way to tell the dozen or so different APIs
apart because they're all just called "Maps", so when you search for
documentation you're almost guaranteed to get something that stopped
working six years ago -- but the documentation is still there making
it look like it's still valid.)
And I was happy to discover that, in the time since I originally set
up the trailmap page, some open providers of aerial/satellite map
tiles have appeared. So we can use open source and have a
satellite view.
Our trail map is back online with Leaflet, and with any luck,
this time it will keep working.
PEEC
Los Alamos Area Trail Map.
Tags: mapping, web, programming, javascript
[
16:13 May 24, 2018
More programming |
permalink to this entry |
]
Tue, 22 May 2018
Humble Bundle has a great
bundle going right now (for another 15 minutes -- sorry, I meant to post
this earlier) on books by Nebula-winning science fiction authors,
including some old favorites of mine, and a few I'd been meaning to read.
I like Humble Bundle a lot, but one thing about them I don't like:
they make it very difficult to download books, insisting that you click
on every single link (and then do whatever "Download this link / yes, really
download, to this directory" dance your browser insists on) rather than
offering a sane option like a tarball or zip file. I guess part of their
business model includes wanting their customers to get RSI. This has
apparently been a problem for quite some time; a web search found lots
of discussions of ways of automating the downloads, most of which
apparently no longer work (none of the ones I tried did).
But a wizard friend on IRC quickly came up with a solution:
some javascript you can paste into Firefox's console. She started
with a quickie function that fetched all but a few of the files, but
then modified it for better error checking and the ability to get
different formats.
In Firefox, open the web console (Tools/Web Developer/Web Console)
and paste this in the single-line javascript text field at the bottom.
// How many seconds to delay between downloads.
var delay = 1000;
// whether to use window.location or window.open
// window.open is more convenient, but may be popup-blocked
var window_open = false;
// the filetypes to look for, in order of preference.
// Make sure your browser won't try to preview these filetypes.
var filetypes = ['epub', 'mobi', 'pdf'];
var downloads = document.getElementsByClassName('download-buttons');
var i = 0;
var success = 0;
function download() {
var children = downloads[i].children;
var hrefs = {};
for (var j = 0; j < children.length; j++) {
var href = children[j].getElementsByClassName('a')[0].href;
for (var k = 0; k < filetypes.length; k++) {
if (href.includes(filetypes[k])) {
hrefs[filetypes[k]] = href;
console.log('Found ' + filetypes[k] + ': ' + href);
}
}
}
var href = undefined;
for (var k = 0; k < filetypes.length; k++) {
if (hrefs[filetypes[k]] != undefined) {
href = hrefs[filetypes[k]];
break;
}
}
if (href != undefined) {
console.log('Downloading: ' + href);
if (window_open) {
window.open(href);
} else {
window.location = href;
}
success++;
}
i++;
console.log(i + '/' + downloads.length + '; ' + success + ' successes.');
if (i < downloads.length) {
window.setTimeout(download, delay);
}
}
download();
If you have "Always ask where to save files" checked in
Preferences/General, you'll still get a download dialog for each book
(but at least you don't have to click; you can hit return for each
one). Even if this is your preference, you might want to consider
changing it before downloading a bunch of Humble books.
Anyway, pretty cool! Takes the sting out of bundles, especially big
ones like this 42-book collection.
Tags: ebook, programming, web, firefox
[
17:49 May 22, 2018
More tech/web |
permalink to this entry |
]
Fri, 11 May 2018
I was working on a weather project to make animated maps of the
jet stream. Getting and plotting wind data is a much longer article
(coming soon), but once I had all the images plotted, I wanted to
combine them all into a time-lapse video showing how the jet stream moves.
Like most projects, it's simple once you find the right recipe.
If your images are named outdir/filename00.png, outdir/filename01.png,
outdir/filename02.png and so on,
you can turn them into an MPEG4 video with ffmpeg:
ffmpeg -i outdir/filename%2d.png -filter:v "setpts=6.0*PTS" -pix_fmt yuv420p jetstream.mp4
%02d, for non-programmers, just means a 2-digit decimal integer
with leading zeros, If the filenames just use 1, 2, 3, ... 10, 11 without
leading zeros, use %2d instead; if they have three digits, use %03d or
%3d, and so on.
Update:
If your first photo isn't numbered 00, you can set a
-start_number — but it must come before the -i and
filename template. For instance:
ffmpeg -start_number 17 --i outdir/filename%2d.png -filter:v "setpts=6.0*PTS" -pix_fmt yuv420p jetstream.mp4
That "setpts=6.0*PTS" controls the speed of the playback,
by adding or removing frames.
PTS stands for "Presentation TimeStamps",
which apparently is a measure of how far along a frame is in the file;
setpts=6.0*PTS means for each frame, figure out how far
it would have been in the file (PTS) and multiply that by 6. So if
a frame would normally have been at timestamp 10 seconds, now it will be at
60 seconds, and the video will be six times longer and six times slower.
And yes, you can also use values less than one to speed a video up.
You can also change a video's playback speed by
changing the
frame rate, either with the -r option, e.g. -r 30,
or with the fps filter, filter:v fps=30.
The default frame rate is 25.
You can examine values like the frame rate, number of frames and duration
of a video file with:
ffprobe -select_streams v -show_streams filename
or with the mediainfo program (not part of ffmpeg).
The -pix_fmt yuv420p turned out to be the tricky part.
The recipes I found online didn't include that part, but without it,
Firefox claims "Video can't be played because the file is corrupt",
even though most other browsers can play it just fine.
If you open Firefox's web console and reload, it offers the additional
information
"Details: mozilla::SupportChecker::AddMediaFormatChecker(const mozilla::TrackInfo&)::<lambda()>: Decoder may not have the capability to handle the requested video format with YUV444 chroma subsampling.":
Adding -pix_fmt yuv420p cured the problem and made the
video compatible with Firefox, though at first I had problems with
ffmpeg complaining "height not divisible by 2 (1980x1113)" (even though
the height of the images was in fact divisible by 2).
I'm not sure what was wrong; later ffmpeg stopped giving me that error
message and converted the video. It may depend on where in the ffmpeg
command you put the pix_fmt flag or what other flags are
present. ffmpeg arguments are a mystery to me.
Of course, if you're only making something to be uploaded to youtube,
the Firefox limitation probably doesn't matter and you may not need
the -pix_fmt yuv420p argument.
Animated GIFs
Making an animated GIF is easier. You can use ImageMagick's convert:
convert -delay 30 -loop 0 *.png jetstream.gif
The GIF will be a lot larger, though. For my initial test of thirty
1000 x 500 images, the MP4 was 760K while the GIF was 4.2M.
Tags: web, video, time-lapse, firefox
[
09:59 May 11, 2018
More linux |
permalink to this entry |
]
Thu, 01 Mar 2018
I updated my Debian Testing system via apt-get upgrade,
as one does during the normal course of running a Debian system.
The next time I went to a locally hosted website, I discovered PHP
didn't work. One of my websites gave an error, due to a directive
in .htaccess; another one presented pages that were full of PHP code
interspersed with the HTML of the page. Ick!
In theory, Debian updates aren't supposed to change configuration files
without asking first, but in practice, silent and unexpected Apache
bustage is fairly common. But for this one, I couldn't find anything
in a web search, so maybe this will help.
The problem turned out to be that /etc/apache2/mods-available/
includes four files:
$ ls /etc/apache2/mods-available/*php*
/etc/apache2/mods-available/php7.0.conf
/etc/apache2/mods-available/php7.0.load
/etc/apache2/mods-available/php7.2.conf
/etc/apache2/mods-available/php7.2.load
The appropriate files are supposed to be linked from there into
/etc/apache2/mods-enabled. Presumably, I previously had a link
to ../mods-available/php7.0.* (or perhaps 7.1?); the upgrade to
PHP 7.2 must have removed that existing link without replacing it with
a link to the new ../mods-available/php7.2.*.
The solution is to restore those links, either with ln -s
or with the approved apache2 commands (as root, of course):
# a2enmod php7.2
# systemctl restart apache2
Whew! Easy fix, but it took a while to realize what was broken, and
would have been nice if it didn't break in the first place.
Why is the link version-specific anyway? Why isn't there a file called
/etc/apache2/mods-available/php.* for the latest version?
Does PHP really change enough between minor releases to break websites?
Doesn't it break a website more to disable PHP entirely than to swap in
a newer version of it?
Tags: linux, debian, apache, web
[
10:31 Mar 01, 2018
More linux |
permalink to this entry |
]
Wed, 04 Jan 2017
A couple of days ago I blogged about using
Firefox's
"Delete Node" to make web pages more readable.
In a
subsequent Twitter
discussion someone pointed out that if the goal is to make a web
page's content clearer, Firefox's relatively new "Reader Mode" might be
a better way.
I knew about Reader Mode but hadn't used it. It only shows up on some
pages. as a little "open book" icon to the right of the URLbar just
left of the Refresh/Stop button. It did show up on the Pogue Yahoo article;
but when I clicked it, I just got a big blank page with an icon of a
circle with a horizontal dash; no text.
It turns out that to see Reader Mode content in noscript, you must
explicitly enable javascript from about:reader.
There are some reasons it's not automatically whitelisted:
see discussions in
bug 1158071
and
bug 1166455
-- so enable it at your own risk.
But it's nice to be able to use Reader Mode, and I'm glad the Twitter
discussion spurred me to figure out why it wasn't working.
Tags: firefox, web
[
11:37 Jan 04, 2017
More tech/web |
permalink to this entry |
]
Mon, 02 Jan 2017
It's trendy among web designers today -- the kind who care more about
showing ads than about the people reading their pages -- to use fixed
banner elements that hide part of the page. In other words, you have
a header, some content, and maybe a footer; and when you scroll the
content to get to the next page, the header and footer stay in place,
meaning that you can only read the few lines sandwiched in between them.
But at least you can see the name of the site no matter how far you
scroll down in the article! Wouldn't want to forget the site name!
Worse, many of these sites don't scroll properly. If you Page Down,
the content moves a full page up, which means that the top of the new
page is now hidden under that fixed banner and you have to scroll back
up a few lines to continue reading where you left off.
David Pogue wrote about that problem recently and it got a lot of play
when Slashdot picked it up:
These 18 big websites fail the space-bar scrolling test.
It's a little too bad he concentrated on the spacebar. Certainly it's
good to point out that hitting the spacebar scrolls down -- I was
flabbergasted to read the Slashdot discussion and discover that lots
of people didn't already know that, since it's been my most common way
of paging since browsers were invented. (Shift-space does a Page Up.)
But the Slashdot discussion then veered off into a chorus of "I've
never used the spacebar to scroll so why should anyone else care?",
when the issue has nothing to do with the spacebar: the issue is
that Page Down doesn't work right, whichever key you use to
trigger that page down.
But never mind that. Fixed headers that don't scroll are bad even
if the content scrolls the right amount, because it wastes precious
vertical screen space on useless cruft you don't need.
And I'm here to tell you that you can get rid of those annoying fixed
headers, at least in Firefox.
![[Article with intrusive Yahoo headers]](http://shallowsky.com/blog/images/delete-node/pogue-article.jpg)
Let's take Pogue's article itself, since Yahoo is a perfect example of
annoying content that covers the page and doesn't go away. First
there's that enormous header -- the bottom row of menus ("Tech Home" and
so forth) disappear once you scroll, but the rest stay there forever.
Worse, there's that annoying popup on the bottom right ("Privacy | Terms"
etc.) which blocks content, and although Yahoo! scrolls the right
amount to account for the header, it doesn't account for that privacy
bar, which continues to block most of the last line of every page.
The first step is to call up the DOM Inspector. Right-click on the
thing you want to get rid of and choose Inspect Element:
![[Right-click menu with Inspect Element]](http://shallowsky.com/blog/images/delete-node/inspect-menu.jpg)
That brings up the DOM Inspector window, which looks like this
(click on the image for a full-sized view):
![[DOM Inspector]](http://shallowsky.com/blog/images/delete-node/inspector.jpg)
The upper left area shows the hierarchical structure of the web page.
Don't Panic! You don't have to know HTML or understand any of
this for this technique to work.
Hover your mouse over the items in the hierarchy. Notice that as you
hover, different parts of the web page are highlighted in translucent blue.
Generally, whatever element you started on will be a small part of the
header you're trying to eliminate. Move up one line, to the element's
parent; you may see that a bigger part of the header is highlighted.
Move up again, and keep moving up, one line at a time, until the whole
header is highlighted, as in the screenshot. There's also a dark grey
window telling you something about the HTML, if you're interested;
if you're not, don't worry about it.
Eventually you'll move up too far, and some other part of the page,
or the whole page, will be highlighted. You need to find the element
that makes the whole header blue, but nothing else.
Once you've found that element, right-click on it to get a context menu,
and look for Delete Node (near the bottom of the menu).
Clicking on that will delete the header from the page.
Repeat for any other part of the page you want to remove, like that
annoying bar at the bottom right. And you're left with a nice, readable
page, which will scroll properly and let you read every line,
and will show you more text per page so you don't have to scroll as often.
![[Article with intrusive Yahoo headers]](http://shallowsky.com/blog/images/delete-node/pogue-fixed.jpg)
It's a useful trick.
You can also use Inspect/Delete Node for many of those popups that
cover the screen telling you "subscribe to our content!" It's
especially handy if you like to browse with NoScript, so you
can't dismiss those popups by clicking on an X.
So happy reading!
Addendum on Spacebars
By the way, in case you weren't aware that the spacebar did a page
down, here's another tip that might come in useful: the spacebar also
advances to the next slide in just about every presentation program,
from PowerPoint to Libre Office to most PDF viewers. I'm amazed at how
often I've seen presenters squinting with a flashlight at the keyboard
trying to find the right-arrow or down-arrow or page-down or whatever
key they're looking for. These are all ways of advancing to the next
slide, but they're all much harder to find than that great big
spacebar at the bottom of the keyboard.
Tags: web, firefox
[
16:23 Jan 02, 2017
More tech/web |
permalink to this entry |
]
Thu, 09 Jul 2015
For a year or so, I've been appending "output=classic" to any Google
Maps URL. But Google disabled Classic mode last month.
(There have been
a
few other ways to get classic Google maps back, but Google is gradually
disabling them one by one.)
I have basically three problems with the new maps:
- If you search for something, the screen is taken up by a huge
box showing you what you searched for; if you click the "x" to dismiss
the huge box so you can see the map underneath, the box disappears but
so does the pin showing your search target.
- A big swath at the bottom of the screen is taken up by a filmstrip
of photos from the location, and it's an extra click to dismiss that.
- Moving or zooming the map is very, very slow: it relies on OpenGL
support in the browser, which doesn't work well on Linux in general,
or on a lot of graphics cards on any platform.
Now that I don't have the "classic" option any more, I've had to find
ways around the problems -- either that, or switch to Bing maps.
Here's how to make the maps usable in Firefox.
First, for the slowness: the cure is to disable webgl in Firefox.
Go to about:config and search for webgl.
Then doubleclick on the line for webgl.disabled to make it
true.
For the other two, you can add userContent lines to tell
Firefox to hide those boxes.
Locate your
Firefox profile.
Inside it, edit chrome/userContent.css (create that file
if it doesn't already exist), and add the following two lines:
div#cards { display: none !important; }
div#viewcard { display: none !important; }
Voilà! The boxes that used to hide the map are now invisible.
Of course, that also means you can't use anything inside them; but I
never found them useful for anything anyway.
Tags: web, tech, mapping, GIS, firefox
[
10:54 Jul 09, 2015
More tech/web |
permalink to this entry |
]
Tue, 23 Jun 2015
Although Ant
builds
have made Android development much easier, I've long been curious
about the cross-platform phone development apps: you write a simple
app in some common language, like HTML or Python, then run something
that can turn it into apps on multiple mobile platforms, like
Android, iOS, Blackberry, Windows phone, UbuntoOS, FirefoxOS or Tizen.
Last week I tried two of the many cross-platform mobile frameworks:
Kivy and PhoneGap.
Kivy lets you develop in Python, which sounded like a big plus. I went
to a Kivy talk at PyCon a year ago and it looked pretty interesting.
PhoneGap takes web apps written in HTML, CSS and Javascript and
packages them like native applications. PhoneGap seems much more
popular, but I wanted to see how it and Kivy compared.
Both projects are free, open source software.
If you want to skip the gory details, skip to the
summary: how do Kivy and PhoneGap compare?
PhoneGap
I tried PhoneGap first.
It's based on Node.js, so the first step was installing that.
Debian has packages for nodejs, so
apt-get install nodejs npm nodejs-legacy did the trick.
You need nodejs-legacy to get the "node" command, which you'll
need for installing PhoneGap.
Now comes a confusing part. You'll be using npm to install ...
something. But depending on which tutorial you're following, it may
tell you to install and use either phonegap or cordova.
Cordova is an Apache project which is intertwined with PhoneGap. After
reading all their FAQs on the subject, I'm as confused as ever about
where PhoneGap ends and Cordova begins, which one is newer, which one
is more open-source, whether I should say I'm developing in PhoneGap
or Cordova, or even whether I should be asking questions on the
#phonegap or #cordova channels on Freenode. (The one question I had,
which came up later in the process, I asked on #phonegap and got a
helpful answer very quickly.) Neither one is packaged in Debian.
After some searching for a good, comprehensive tutorial, I ended up on a
The Cordova
tutorial rather than a PhoneGap one. So I typed:
sudo npm install -g cordova
Once it's installed, you can create a new app, add the android platform
(assuming you already have android development tools installed) and
build your new app:
cordova create hello com.example.hello HelloWorld
cordova platform add android
cordova build
Oops!
Error: Please install Android target: "android-22"
Apparently Cordova/Phonegap can only build with its own
preferred version of android, which currently is 22.
Editing files to specify android-19 didn't work for me;
it just gave errors at a different point.
So I fired up the Android SDK manager, selected android-22 for install,
accepted the license ... and waited ... and waited. In the end it took
over two hours to download the android-22 SDK; the system image is 13Gb!
So that's a bit of a strike against PhoneGap.
While I was waiting for android-22 to download, I took a look at Kivy.
Kivy
As a Python enthusiast, I wanted to like Kivy best.
Plus, it's in the Debian repositories: I installed it with
sudo apt-get install python-kivy python-kivy-examples
They have a nice
quickstart
tutorial for writing a Hello World app on their site. You write
it, run it locally in python to bring up a window and see what the
app will look like. But then the tutorial immediately jumps into more
advanced programming without telling you how to build and deploy
your Hello World. For Android, that information is in the
Android
Packaging Guide. They recommend an app called Buildozer (cute name),
which you have to pull from git, build and install.
buildozer init
buildozer android debug deploy run
got started on building ... but then I noticed that it was attempting
to download and build its own version of apache
ant
(sort of a Java version of
make). I already have ant --
I've been using it for weeks for building my own Java android apps.
Why did it want a different version?
The file buildozer.spec in your project's
directory lets you uncomment and customize variables like:
# (int) Android SDK version to use
android.sdk = 21
# (str) Android NDK directory (if empty, it will be automatically downloaded.)
# android.ndk_path =
# (str) Android SDK directory (if empty, it will be automatically downloaded.)
# android.sdk_path =
Unlike a lot of Android build packages, buildozer will not inherit
variables like ANDROID_SDK, ANDROID_NDK and ANDROID_HOME from your
environment; you must edit buildozer.spec.
But that doesn't help with ant.
Fortunately, when I inspected the Python code for buildozer itself, I
discovered there was another variable that isn't mentioned in the
default spec file. Just add this line:
android.ant_path = /usr/bin
Next, buildozer gave me a slew of compilation errors:
kivy/graphics/opengl.c: No such file or directory
... many many more lines of compilation interspersed with errors
kivy/graphics/vbo.c:1:2: error: #error Do not use this file, it is the result of a failed Cython compilation.
I had to ask on #kivy to solve that one. It turns out that the current
version of cython, 0.22, doesn't work with kivy stable. My choices were
to uninstall kivy and pull the development version from git, or to uninstall
cython and install version 0.21.2 via pip. I opted for the latter option.
Either way, there's no "make clean", so removing the dist and build
directories let me start over with the new cython.
apt-get purge cython
sudo pip install Cython==0.21.2
rm -rf ./.buildozer/android/platform/python-for-android/dist
rm -rf ./.buildozer/android/platform/python-for-android/build
Buildozer was now happy, and proceeded to download and build Python-2.7.2,
pygame and a large collection of other Python libraries for the ARM platform.
Apparently each app packages the Python language and all libraries it needs
into the Android .apk file.
Eventually I ran into trouble because I'd named my python file hello.py
instead of main.py; apparently this is something you're not allowed to change
and they don't mention it in the docs, but that was easily solved.
Then I ran into trouble again:
Exception: Unable to find capture version in ./main.py (looking for `__version__ = ['"](.*)['"]`)
The buildozer.spec file offers two types of versioning: by default "method 1"
is enabled, but I never figured out how to get past that error with
"method 1" so I commented it out and uncommented "method 2".
With that, I was finally able to build an Android package.
The .apk file it created was quite large because of all the embedded
Python libraries: for the little 77-line pong demo,
/usr/share/kivy-examples/tutorials/pong
in the Debian kivy-examples package, the apk came out 7.3Mb.
For comparison, my FeedViewer native java app, roughly 2000 lines of
Java plus a few XML files, produces a 44k apk.
The next step was to make a real mini app.
But when I looked through the Kivy examples, they all seemed highly
specialized, and I couldn't find any documentation that addressed issues
like what widgets were available or how to lay them out. How do I add a
basic text widget? How do I put a button next to it? How do I get
the app to launch in portrait rather than landscape mode?
Is there any way to speed up the very slow initialization?
I'd spent a few hours on Kivy and made a Hello World app, but I
was having trouble figuring out how to do anything more. I needed a
change of scenery.
PhoneGap, redux
By this time, android-22 had finally finished downloading.
I was ready to try PhoneGap again.
This time,
cordova platforms add android
cordova build
worked fine. It took a long time, because it downloaded the huge gradle
build system rather than using something simpler like ant. I already have
a copy of gradle somewhere (I downloaded it for the OsmAnd build), but
it's not in my path, and I was too beaten down by this point to figure
out where it was and how to get cordova to point to it.
Cordova eventually produced a 1.8Mb "hello world" apk --
a quarter the size of the Kivy package,
though 20 times as big as a native Java app.
Deployed on Android, it initialized much faster than the Kivy app, and
came up in portrait mode but rotated correctly if I rotated the phone.
Editing the HTML, CSS and Javascript was fairly simple. You'll want
to replace pretty much all of the default CSS if you don't want your app
monopolized by the Cordova icon.
The only tricky part was file access: opening a file:// URL
didn't work. I asked on #phonegap and someone helpfully told me I'd
need the file plugin. That was easy to find in the documentation, and
I added it like this:
cordova plugin search file
cordova plugin add org.apache.cordova.file
My final apk, for a small web app I use regularly on Android,
was almost the same size as their hello world example: 1.8Mb.
And it works great: phonegap had no problem playing an audio clip,
something that was tricky when I was trying to do the same thing
from a native Android java WebView class.
Summary: How do Kivy and PhoneGap compare?
This has been a long article, I know. So how do Kivy and PhoneGap compare,
and which one will I be using?
They both need a large amount of disk space for the development environment.
I wish I had good numbers to give you, but I was working with
both systems at the same time, and their packages are scattered all
over the disk so I haven't found a good way of measuring their size. I
suspect PhoneGap is quite a bit bigger, because it uses gradle rather
than ant and because it insists on android-22.
On the other hand, PhoneGap wins big on packaged application size:
its .apk files are a quarter the size of Kivy's.
PhoneGap definitely wins on documentation. Kivy has seemingly lots of
documentation, but its tutorials jumped around rather than following
a logical sequence, and I had trouble finding answers to basic
questions like "How do I display a text field with a button?"
PhoneGap doesn't need that, because the UI is basic HTML and CSS --
limited though they are, at least most people know how to use them.
Finally, PhoneGap wins on startup speed. For my very simple test app,
startup was more or less immediate, while the Kivy Hello World app
required several seconds of startup time on my Galaxy S4.
Kivy is an interesting project. I like the ant-based build, the
straightforward .spec file, and of course the Python language.
But it still has some catching up to do in performance and documentation.
For throwing together a simple app and packaging it for Android, I
have to give the win to PhoneGap.
Tags: android, programming, PhoneGap, Kivy, Cordova, python, web
[
12:09 Jun 23, 2015
More programming |
permalink to this entry |
]
Wed, 06 May 2015
I saw on Slashdot that Google is going to start down-rating sites
that don't meet its criteria of "mobile-friendly":
Are you ready for Google's 'Mobilegeddon' on Tuesday?.
And from the the Slashdot
discussion, it was pretty clear that Google's definition included
some arbitrary hoops to jump through.
So I headed over to
Google's
Mobile-friendly test to check out some of my pages.
Now, most of my website seemed to me like it ought to be pretty mobile
friendly. It's size agnostic: I don't specify any arbitrary page widths
in pixels, so most of my pages can resize down as far as necessary
(I was under the impression that was what "responsive design" meant
for websites, though I've been doing it for many years and it seems now
that "responsive design" includes a whole lot of phone-specific tweaks
and elaborate CSS for moving things around based on size.)
I also don't set font sizes that might make the page less accessible to
someone with vision problems -- or to someone on a small screen with high
pixel density. So I was pretty confident.
![[Google's mobile-friendly test page]](http://shallowsky.com/blog/images/screenshots/mobile/unfriendly.jpg) I shouldn't have been. Basically all of my pages failed. And in chasing
down some of the problems I've learned a bit about Google's mobile rules,
as well as about some weird quirks in how current mobile browsers
render websites.
I shouldn't have been. Basically all of my pages failed. And in chasing
down some of the problems I've learned a bit about Google's mobile rules,
as well as about some weird quirks in how current mobile browsers
render websites.
Basically, all of my pages failed with the same three errors:
- Text too small to read
- Links too close together
- Mobile viewport not set
What? I wasn't specifying text size at all -- if the text is too small
to read with the default font, surely that's a bug in the mobile browser,
not a bug in my website. Same with links too close together, when I'm
using the browser's default line spacing.
But it turned out that the first two points were meaningless. They were
just a side effect of that third error: the mobile viewport.
The mandatory meta viewport tag
It turns out that any page that doesn't add a new meta tag, called
"viewport", will automatically fail Google's mobile friendly test
and be downranked accordingly. What's that all about?
Apparently it's originally Apple's fault.
iPhones, by default, pretend their screen is 980 pixels wide instead
of the actual 320 or 640, and render content accordingly, and so they
shrink everything down by a factor of 3 (980/320).
They do this assuming that most website designers will set a hard
limit of 980 pixels (which I've always considered to be bad design)
... and further assuming that their users care more about seeing the
beautiful layout of a website than about reading the website's text.
And Google apparently felt, at some point during the Android development
process, that they should copy Apple in this silly behavior.
I'm not sure when Android started doing this; my Android 2.3 Samsung
doesn't do it, so it must have happened later than that.
Anyway, after implementing this, Apple then introduced a meta tag you
can add to an HTML file to tell iPhone browsers not to do this scaling,
and to display the text at normal text size. There are various
forms for this tag, but the most common is:
<meta name="viewport" content="width=device-width, initial-scale=1">
(A lot of examples I found on the web at first suggested this:
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1">
but
don't do that -- it prevents people from zooming in to see
more detail, and hurts the accessibility of the page, since people who
need to zoom in won't be able to. Here's more on that:
Stop
using the viewport meta tag (until you know how to use it.)
Just to be clear, Google is telling us that in order not to have our pages
downgraded, we have to add a new tag to every page on the web
to tell mobile browsers not to do something silly that they shouldn't
have been doing in the first place, and which Google implemented
to copy a crazy thing Apple was doing.
How width and initial-scale relate
Documentation on how width and initial-scale relate to
each other, and which takes precedence, are scant. Apple's
documentation
on the meta viewport tag says that setting
initial-scale=1 automatically sets width=device-width.
That implies that the two are basically equivalent: that they're only
different if you want to do something else, like set a page width in
pixels (use width=) or set the width to some ratio of the
device width other than 1 (use initial-scale=.
That means that using initial-scale=1 should
imply width=device-width -- yet nearly everyone on the web
seems to use both. So I'm doing that, too.
Apparently there was once a point to it: some older iPhones had a bug
involving switching orientation to landscape mode, and specifying
both initial-scale=1 and width=device-width helped,
but supposedly that's long since been fixed.
initial-scale=2, by the way, sets the viewport to half what it would
have been otherwise; so if the width would have been 320, it sets it
to 160, so you'll see half as much. Why you'd want to set
initial-scale to anything besides 1 in a web page, I don't know.
If the width specified by initial-scale conflicts with that
specified by width, supposedly iOS browsers will
take the larger of the two, while Android won't accept a width
directive less than 320, according to
Quirks mode:
testing Meta viewport.
It would be lovely to be able to test this stuff; but my only Android
device is running Android 2.3, which doesn't do all this silly zooming out.
It does what a sensible small-screen device should do: it shows text at
normal, readable size by default, and lets you zoom in or out if you need to.
(Only marginally related, but interesting if you're doing elaborate
stylesheets that take device resolution into account, is
A List Apart's discussion,
A
Pixel Identity Crisis.)
Control width of images
![[Image with max-width 100%]](http://shallowsky.com/blog/images/screenshots/mobile/nonotchka-tail.jpg) Once I added meta viewport tags, most of my pages passed the test.
But I was seeing something else on some of my photo pages, as well as
blog pages where I have inline images:
Once I added meta viewport tags, most of my pages passed the test.
But I was seeing something else on some of my photo pages, as well as
blog pages where I have inline images:
- Content wider than screen
- Links too close together
Image pages are all about showing an image. Many of my images are wider
than 320 pixels ... and thus get flagged as too wide for the screen.
Note the scrollbars, and how you can only see a fraction of the image.
There's a simple way to fix this, and unlike the meta viewport thing,
it actually makes sense.
The solution is to force images to be no wider than the screen
with this little piece of CSS:
<style type="text/css">
img { max-width: 100%; height: auto; }
</style>
![[Image with max-width 100%]](http://shallowsky.com/blog/images/screenshots/mobile/nonotchka-fixed.jpg) I've been using similar CSS in my RSS reader for several months, and I
know how much better it made the web, on news sites that insist on
using 1600 pixel wide images inline in stories.
So I'm happy to add it to my photo pages. If someone on a mobile
browser wants to view every hair in a squirrel's tail, they can
still zoom in to the page, or long-press on the image to view it at
full resolution. Or rotate to landscape mode.
I've been using similar CSS in my RSS reader for several months, and I
know how much better it made the web, on news sites that insist on
using 1600 pixel wide images inline in stories.
So I'm happy to add it to my photo pages. If someone on a mobile
browser wants to view every hair in a squirrel's tail, they can
still zoom in to the page, or long-press on the image to view it at
full resolution. Or rotate to landscape mode.
The CSS rule works for those wide page banners too. Or you can use
overflow: hidden if the right side of your banner isn't
all that important.
Anyway, that takes care of the "page too wide" problem. As for the
"Links too close together" even after I added the meta viewport tag,
that was just plain bad HTML and CSS, showing that I don't do enough
testing on different window sizes. I fixed it so the buttons lay out
better and don't draw on top of each other on super narrow screens,
which I should have done long ago. Likewise for some layout problems
I found on my blog.
So despite my annoyance with the whole viewport thing, Google's mandate
did make me re-examine some pages that really needed fixing,
and should have improved my website quite a bit for anyone looking at
it on a small screen. I'm glad of that.
It'll be a while before I have all my pages converted, especially
that business of adding the meta tag to all of them. But readers, if
you see usability problems with my site, whether on mobile devices or
otherwise, please tell me about them!
Tags: web, android
[
15:48 May 06, 2015
More tech/web |
permalink to this entry |
]
Tue, 21 Apr 2015
I recently took over a website that's been neglected for quite a
while. As well as some bad links, I noticed a lot of old files, files
that didn't seem to be referenced by any of the site's pages.
Orphaned files.
So I went searching for a link checker that
also finds orphans. I figured that would be easy. It's
something every web site maintainer needs, right? I've gotten by
without one for my own website, but I know there are some bad links
and orphans there and I've often wanted a way to find them.
An intensive search turned up only one possibility: linklint, which
has a -orphan flag. Great! But, well, not really: after a few hours of
fiddling with options, I couldn't find any way to make it actually
find orphans. Either you run it on a http:// URL,
and it says it's searching for orphans but didn't find any (because it
ignors any local directory you specify); or you can run it just on a
local directory, in which case it finds a gazillion orphans
that aren't actually orphans, because they're referenced by files
generated with PHP or other web technology. Plus it flags all the
bad links in all those supposed orphans, which get in the way of
finding the real bad links you need to worry about.
I tried asking on a couple of technical mailing lists and IRC channels.
I found a few people who had managed to use linklint, but only by spidering
an entire website to local files (thus getting rid of any server side
dependencies like PHP, CGI or SSI) and then running linklint on the
local directory. I'm sure I could do that one time, for one website.
But if it's that much hassle, there's not much chance I'll keep
using to to keep websites maintained.
What I needed was a program that could look at a website and local
directory at the same time, and compare them, flagging any file
that isn't referenced by anything on the website. That sounded like it
would be such a simple thing to write.
So, of course, I had to try it. This is a tool that needs to exist --
and if for some bizarre reason it doesn't exist already, I was
going to remedy that.
Naturally, I found out that it wasn't quite as easy to write as it
sounded. Reconciling a URL like "http://mysite.com/foo/bar.html"
or "../asdf.html" with the corresponding path on disk turned
out to have a lot of twists and turns.
But in the end I prevailed. I ended up with a script called
weborphans
(on github). Give it both a local directory for the files making
up your website, and the URL of that website, for instance:
$ weborphans /var/www/ http://localhost/
It's still a little raw, certainly not perfect. But it's good
enough that I was able to find the 10 bad links and 606 orphaned
files on this website I inherited.
Tags: weborphan, programming, web
[
14:55 Apr 21, 2015
More tech/web |
permalink to this entry |
]
Mon, 06 Apr 2015
The local bird community has gotten me using
eBird.
It's sort of social networking for birders -- you can report sightings,
keep track of what birds you've seen where, and see what other people
are seeing in your area.
The only problem is the user interface for that last part. The data is
all there, but asking a question like "Where in this county have people
seen broad-tailed hummingbirds so far this spring?" is a lengthy
process, involving clicking through many screens and typing the
county name (not even a zip code -- you have to type the name).
If you want some region smaller than the county, good luck.
I found myself wanting that so often that I wrote an entry page for it.
My Bird Maps page
is meant to be used as a smart bookmark (also known as bookmarklets
or keyword bookmarks),
so you can type birdmap hummingbird or birdmap golden eagle
in your location bar as a quick way of searching for a species.
It reads the bird you've typed in, and looks through a list of
species, and if there's only one bird that matches, it takes you
straight to the eBird map to show you where people have reported
the bird so far this year.
If there's more than one match -- for instance, for birdmap hummingbird
or birdmap sparrow -- it will show you a list of possible matches,
and you can click on one to go to the map.
Like every Javascript project, it was both fun and annoying to write.
Though the hardest part wasn't programming; it was getting a list of
the nonstandard 4-letter bird codes eBird uses. I had to scrape one
of their HTML pages for that.
But it was worth it: I'm finding the page quite useful.
How to make a smart bookmark
I think all the major browsers offer smart bookmarks now, but I can
only give details for Firefox.
But
here's a page about using them in Chrome.
Firefox has made it increasingly difficult with every release to make
smart bookmarks. There are a few extensions, such as "Add Bookmark Here",
which make it a little easier. But without any extensions installed,
here's how you do it in Firefox 36:
![[Firefox bookmarks dialog]](http://shallowsky.com/blog/images/screenshots/bookmark-dialogT.jpg) First, go to the birdmap page
(or whatever page you want to smart-bookmark) and click on the * button
that makes a bookmark. Then click on the = next to the *, and in the
menu, choose Show all bookmarks.
In the dialog that comes up, find the bookmark you just made (maybe in
Unsorted bookmarks?) and click on it.
First, go to the birdmap page
(or whatever page you want to smart-bookmark) and click on the * button
that makes a bookmark. Then click on the = next to the *, and in the
menu, choose Show all bookmarks.
In the dialog that comes up, find the bookmark you just made (maybe in
Unsorted bookmarks?) and click on it.
Click the More button at the bottom of the dialog.
(Click on the image at right for a full-sized screenshot.)
![[Firefox bookmarks dialog showing keyword]](http://shallowsky.com/blog/images/screenshots/bookmark-dialog-birdmap.jpg)
Now you should see a Keyword entry under the Tags entry
in the lower right of that dialog.
Change the Location to
http://shallowsky.com/birdmap.html?bird=%s.
Then give it a Keyword of birdmap
(or anything else you want to call it).
Close the dialog.
Now, you should be able to go to your location bar and type:
birdmap common raven
or
birdmap sparrow
and it will take you to my birdmap page. If the bird name specifies
just one bird, like common raven, you'll go straight from there to
the eBird map. If there are lots of possible matches, as with sparrow,
you'll stay on the birdmap page so you can choose which sparrow you want.
How to change the default location
If you're not in Los Alamos, you probably want a way to set your own
coordinates. Fortunately, you can; but first you have to get those
coordinates.
Here's the fastest way I've found to get coordinates for a region on eBird:
- Click "Explore a Region"
- Type in your region and hit Enter
- Click on the map in the upper right
Then look at the URL: a part of it should look something like this:
env.minX=-122.202087&env.minY=36.89291&env.maxX=-121.208778&env.maxY=37.484802
If the map isn't right where you want it, try editing the URL, hitting
Enter for each change, and watch the map reload until it points where
you want it to. Then copy the four parameters and add them to your
smart bookmark, like this:
http://shallowsky.com/birdmap.html?bird=%s&minX=-122.202087&minY=36.89291&maxX=-121.208778&maxY=37.484802
Note that all of the the "env." have been removed.
The only catch is that I got my list of 4-letter eBird codes from an
eBird page for New Mexico.
I haven't found any way of getting the list for the entire US.
So if you want a bird that doesn't occur in New Mexico, my page might
not find it. If you like birdmap but want to use it in a different
state, contact me and tell me which state
you need, and I'll add those birds.
Tags: nature, birds, eBird, web, programming, javascript, firefox, bookmarklets
[
14:30 Apr 06, 2015
More nature/birds |
permalink to this entry |
]
Fri, 27 Mar 2015
Lately, Google is wasting space at the top of every search with a
begging plea to be my default search engine.
![[Google begging: Switch your default search engine to Google]](http://shallowsky.com/blog/images/screenshots/google-begT.jpg) Google already is
my default search engine -- that's how I got to that page.
But if you don't have persistent Google cookies set,
you have to see this begging every time you do a search.
(Why they think pestering users is the way to get people to switch to
them is beyond me.)
Google already is
my default search engine -- that's how I got to that page.
But if you don't have persistent Google cookies set,
you have to see this begging every time you do a search.
(Why they think pestering users is the way to get people to switch to
them is beyond me.)
Fortunately, in Firefox you can hide the begging with a userContent trick.
Find the chrome directory inside your Firefox profile, and
edit userContent.css in that directory. (Create a new file
with that name if you don't already have one.) Then add this:
#taw { display: none !important; }
Restart Firefox, do a Google search and the begs should be gone.
In case you have any similar pages where there's pointless content
getting in the way and you want to hide it:
what I did was to right-click inside
the begging box and choose Inspect element. That brings up
Firefox's DOM inspector. Mouse over various lines in the inspector
and watch what gets highlighted in the browser window. Find the
element that highlights everything you want to remove -- in this
case, it's a div with id="taw". Then you can write CSS to address
that: hide it, change its style or whatever you're trying to do.
You can even use Inspect element to remove elements immediately.
That won't help you prevent them from showing up later, but it can be
wonderful if you need to use a page that has an annoying blinking ad
on it, or a mis-designed page that has images covering the content
you're trying to read.
Tags: web, firefox, google
[
08:17 Mar 27, 2015
More tech/web |
permalink to this entry |
]
Sat, 14 Mar 2015
It's getting so that I dread Firefox's roughly weekly "There's a new
version -- do you want to upgrade?" With every new upgrade, another new
crucial feature I use every day disappears and I have to spend hours
looking for a workaround.
Last week, upgrading to Firefox 36.0.1, it was keyword search: the
feature where, if I type something in the location bar that isn't a
URL, Firefox would instead search using the search URL specified in
the "keyword.URL" preference.
In my case, I use Google but I try to turn off the autocomplete feature,
which I find it distracting and unhelpful when typing new search terms.
(I say "try to" because complete=0 only works sporadically.)
I also add the prefix allintext: to tell Google that I only
want to see pages that contain my search term. (Why that isn't the
default is anybody's guess.) So I set keyword.URL to:
http://www.google.com/search?complete=0&q=allintext%3A+
(%3A is URL code for the colon character).
But after "up"grading to 36.0.1, search terms I typed in the location
bar took me to Yahoo search. I guess Yahoo is paying Mozilla more than
Google is now.
Now, Firefox has a Search tab under Edit->Preferences
-- but that just gives you a list of standard
search engines' default searches. It would let me use Google, but
not with my preferred options.
If you follow the long discussions in bugzilla, there are a lot of
people patting each other on the back about how much easier the
preferences window is, with no discussion of how to specify custom searches
except vague references to "search plugins".
So how do these search plugins work, and how do you make one?
Fortunately a friend had a plugin installed, acquired from who knows
where. It turns out that what you need is an XML file inside a
directory called searchplugins in your profile directory.
(If you're not sure where your profile lives, see
Profiles - Where Firefox stores your bookmarks, passwords and other user data,
or do a systemwide search for "prefs.js" or "search.json" or "cookies.sqlite"
and it should lead you to your profile.)
Once you have one plugin installed, it's easy to edit it and modify it
to do anything you want. The XML file looks roughly like this:
<SearchPlugin xmlns="http://www.mozilla.org/2006/browser/search/" xmlns:os="http://a9.com/-/spec/opensearch/1.1/">
<os:ShortName>MySearchPlugin</os:ShortName>
<os:Description>The search engine I prefer to use</os:Description>
<os:InputEncoding>UTF-8</os:InputEncoding>
<os:Image width="16" height="16">data:image/x-icon;base64,ICON GOES HERE</os:Image>
<SearchForm>http://www.google.com/</SearchForm>
<os:Url type="text/html" method="GET" template="https://www.google.com/search">
<os:Param name="complete" value="0"/>
<os:Param name="q" value="allintext: {searchTerms}"/>
<!--os:Param name="hl" value="en"/-->
</os:Url>
</SearchPlugin>
There are four things you'll want to modify. First, and most
important, os:Url and os:Param control the base URL
of the search engine and the list of parameters it takes.
{searchTerms} in one of those Param arguments will be replaced
by whatever terms you're searching for. So
<os:Param name="q" value="allintext: {searchTerms}"/>
gives me that allintext: parameter I wanted.
(The other parameter I'm specifying,
<os:Param name="complete" value="0"/>, used to
make Google stop the irritating autocomplete every time you try to
modify your search terms. Unfortunately, this has somehow stopped
working at exactly the same time that I upgraded Firefox. I don't
see how Firefox could be causing it, but the timing is suspicious.
I haven't been able to figure out another way of getting rid of the
autocomplete.)
Next, you'll want to give your plugin a ShortName and
Description so you'll be able to recognize it and choose it
in the preferences window.
Finally, you may want to modify the icon: I'll tell you how to do that
in a moment.
Using your new search plugin
![[Firefox search prefs]](http://shallowsky.com/blog/images/screenshots/firefox-searchplugin.jpg)
You've made all your modifications and saved the file to something inside
the searchplugins folder in your Firefox profile. How do you
make it your default?
I restarted firefox to make sure it saw the new plugin, though that
may not have been necessary. Then Edit->Preferences and
click on the Search icon at the top. The menu near the top
under Default search engine is what you want: your new plugin
should show up there.
Modifying the icon
Finally, what about that icon?
In the plugin XML file I was copying, the icon line looked like:
<os:Image width="16"
height="16">data:image/x-icon;base64,AAABAAEAEBAAAAEAIABoBAAAFgAAACgAAAAQAAAAIAAAAAEAIAAAAAAAAAAAAAAA
... many more lines like this then ... ==</os:Image>
So how do I take that and make an image I can customize in GIMP?
I tried copying everything after "base64," and pasting it into a file,
then opening it in GIMP. No luck. I tried base64 decoding it (you do
this with base64 -d filename >outfilename) and reading it
in with GIMP. Still no luck: "Unknown file type".
The method I found is roundabout, but works:
- Copy everything inside the tag: data:image/x-icon;base64,AA ... ==
- Paste that into Firefox's location bar and hit return. You'll see
the icon from the search plugin you're modifying.
- Right-click on the image and choose Save image as...
- Save it to a file with the extension .ico -- GIMP won't
open it without that extension.
- Open it in GIMP -- a 16x16 image -- and edit to your heart's content.
- File->Export as...
- Use the type "Microsoft Windows icon (*.ico)"
- Base64 encode the file you just saved, like this:
base64 yourfile.ico >newfile
- Copy the contents of newfile and paste that into your
os:Image line, replacing everything after
data:image/x-icon;base64, and before </os:Image>
Whew! Lots of steps, but none of them are difficult. (Though if you're
not on Linux and don't have the base64 command, you'll have to
find some other way of encoding and decoding base64.)
But if you don't want to go through all the steps, you can download
mine, with its lame yellow smiley icon, as a starting point:
Google-clean
plug-in.
Happy searching! See you when Firefox 36.0.2 comes out and they
break some other important feature.
Tags: firefox, web
[
12:35 Mar 14, 2015
More tech/web |
permalink to this entry |
]
Mon, 23 Feb 2015
Generally, when I work on a website, I maintain a local copy of all
the files. Ideally, I use version control (git, svn or whatever),
but failing that, I use rsync over ssh to keep my files in sync with the
web server's files.
But I'm helping with a local nonprofit's website, and the cheap web
hosting plan they chose doesn't offer ssh, just ftp.
While I have to question the wisdom of an ISP that insists that its
customers use insecure ftp rather than a secure encrypted protocol, that's
their problem. My problem is how to keep my files in sync with theirs.
And the other folks working on the website aren't developers and are
very resistant to the idea of using any version control system, so
I have to be careful to check for changed files before modifying anything.
In web searches, I haven't found much written about reasonable workflows
on an ftp-only web host. I struggled a lot with scripts calling ncftp
or lftp.
But then I discovered curftpfs, which makes things much easier.
I put a line in /etc/fstab like this:
curlftpfs#user:password@example.com/ /servername fuse rw,allow_other,noauto,user 0 0
Then all I have to do is type mount /servername and the
ftp connection is made automagically. From then on, I can treat it like a
(very slow and somewhat limited) filesystem.
Well, that's not quite all I had to do. There are a few other steps.
Of course, you have to install curlftpfs (duh). But then you'll also
need permission to write the local directory where you're trying to
mount. I suggest using group permissions for that:
# chmod 775 /servername
# chgrp adm /servername
and then edit /etc/group and add yourself to the adm group.
Unfortunately, that means you'll have to log in again, since
/etc/group is only reset on login.
For instance, if I want to rsync, I can
rsync -avn --size-only /servername/subdir/ ~/servername/subdir/
for any particular subdirectory I want to check. A few things to know
about this:
- I have to use --size-only because timestamps aren't reliable.
I'm not sure whether this is a problem with the ftp protocol, or
whether this particular ISP's server has problems with its dates.
I suspect it's a problem inherent in ftp, because if I ls -l,
I see things like this:
-rw-rw---- 1 root root 7651 Feb 23 2015 guide-geo.php
-rw-rw---- 1 root root 1801 Feb 14 17:16 guide-header.php
-rw-rw---- 1 root root 8738 Feb 23 2015 guide-table.php
Note that a file modified a week ago shows a modification time,
but files modified today show only a day and year, not a time.
I'm not sure what to make of this.
- Note the -n flag. I don't automatically rsync from the server
to my local directory, because if I have any local changes newer
than what's on the server they'd be overwritten. So I check the
diffs by hand with tkdiff or meld before copying.
- It's important to rsync only the specific directories you're
working on. You really don't want to see how long it takes to get
the full file tree of a web server recursively over ftp.
How do you change and update files?
It is possible to edit the files on the curlftpfs
filesystem directly. But at least with emacs, it's incredibly slow:
emacs likes to check file modification dates whenever you change anything,
and that requires an ftp round-trip so it could be ten or twenty seconds
before anything you type actually makes it into the file, with even
longer delays any time you save.
So instead, I edit my local copy, and when I'm ready to push to the server,
I cp filename /servername/path/to/filename.
Of course, I have aliases and shell functions to make all of this
easier to type, especially the long pathnames: I can't rely on
autocompletion like I usually would, because autocompleting a
file or directory name on /servername requires an ftp round-trip to ls
the remote directory.
Oh, and version control? I use a local git repository. Just because the
other people working on the website don't want version control is no
reason I can't have a record of my own changes.
None of this is as satisfactory as a nice git or svn repository and
a good ssh connection. But it's a lot better than struggling with
ftp clients every time you need to test a file.
Tags: linux, web
[
19:46 Feb 23, 2015
More linux |
permalink to this entry |
]
Thu, 30 Oct 2014
Today dinner was a bit delayed because I got caught up dealing with an
RSS feed that wasn't feeding. The website was down, and Python's
urllib2, which I use in my
"feedme" RSS fetcher,
has an inordinately long timeout.
That certainly isn't the first time that's happened, but I'd like it
to be the last. So I started to write code to set a shorter timeout,
and realized: how does one test that? Of course, the offending site
was working again by the time I finished eating dinner, went for a
little walk then sat down to code.
I did a lot of web searching, hoping maybe someone had already set up
a web service somewhere that times out for testing timeout code.
No such luck. And discussions of how to set up such a site
always seemed to center around installing elaborate heavyweight Java
server-side packages. Surely there must be an easier way!
How about PHP? A web search for that wasn't helpful either. But I
decided to try the simplest possible approach ... and it worked!
Just put something like this at the beginning of your HTML page
(assuming, of course, your server has PHP enabled):
<?php sleep(500); ?>
Of course, you can adjust that 500 to be any delay you like.
Or you can even make the timeout adjustable, with a
few more lines of code:
<?php
if (isset($_GET['timeout']))
sleep($_GET['timeout']);
else
sleep(500);
?>
Then surf to yourpage.php?timeout=6 and watch the page load
after six seconds.
Simple once I thought of it, but it's still surprising no one
had written it up as a cookbook formula. It certainly is handy.
Now I just need to get some Python timeout-handling code working.
Tags: web, tech, programming, php
[
19:38 Oct 30, 2014
More tech/web |
permalink to this entry |
]
Thu, 11 Sep 2014
I don't use web forums, the kind you have to read online, because they
don't scale. If you're only interested in one subject, then they work fine:
you can keep a browser tab for your one or two web forums perenially open
and hit reload every few hours to see what's new.
If you're interested in twelve subjects, each of which has several
different web forums devoted to it -- how could
you possibly keep up with that? So I don't bother with forums unless
they offer an email gateway, so they'll notify me by email when new
discussions get started, without my needing to check all those web
pages several times per day.
LinkedIn discussions mostly work like a web forum.
But for a while, they had a reasonably usable email gateway. You
could set a preference to be notified of each new conversation.
You still had to click on the web link to read the conversation so far,
but if you posted something, you'd get the rest of the discussion
emailed to you as each message was posted.
Not quite as good as a regular mailing list, but it worked pretty well.
I used it for several years to keep up with the very active Toastmasters
group discussions.
About a year ago, something broke in their software, and they lost
the ability to send email for new conversations. I filed a trouble
ticket, and got a note saying they were aware of the problem and
working on it. I followed up three months later (by filing another
ticket -- there's no way to add to an existing one) and got a response
saying be patient, they were still working on it. 11 months later,
I'm still being patient, but it's pretty clear they have no intention
of ever fixing the problem.
Just recently I fiddled with something in my LinkedIn prefs, and
started getting "Popular Discussions" emails every day or so.
The featured "popular discussion" is always something stupid that
I have no interest in, but it's followed by a section headed
"Other Popular Discussions" that at least gives me some idea what's
been posted in the last few days. Seemed like it might be worth
clicking on the links even though it means I'd always be a few days
late responding to any conversations.
Except -- none of the links work. They all go to a generic page with a red
header saying "Sorry it seems there was a problem with the link you followed."
I'm reading the plaintext version of the mail they send out. I tried
viewing the HTML part of the mail in a browser, and sure enough, those
links worked. So I tried comparing the text links with the HTML:
Text version:
http://www.linkedin.com/e/v2?e=3x1l-hzwzd1q8-6f&t=gde&midToken=AQEqep2nxSZJIg&ek=b2_anet_digest&li=82&m=group_discussions&ts=textdisc-6&itemID=5914453683503906819&itemType=member&anetID=98449
HTML version:
http://www.linkedin.com/e/v2?e=3x1l-hzwzd1q8-6f&t=gde&midToken=AQEqep2nxSZJIg&ek=b2_anet_digest&li=17&m=group_discussions&ts=grouppost-disc-6&itemID=5914453683503906819&itemType=member&anetID=98449
Well, that's clear as mud, isn't it?
HTML entity substitution
I pasted both links one on top of each other, to make it easier to
compare them one at a time. That made it fairly easy to find the first
difference:
Text version:
http://www.linkedin.com/e/v2?e=3x1l-hzwzd1q8-6f&t=gde&midToken= ...
HTML version:
http://www.linkedin.com/e/v2?e=3x1l-hzwzd1q8-6f&t=gde&midToken= ...
Time to die laughing: they're doing HTML entity substitution on the
plaintext part of their email notifications, changing & to &
everywhere in the link.
If you take the link from the text email and replace & with &,
the link works, and takes you to the specific discussion.
Pagination
Except you can't actually read the discussion. I went to a discussion
that had been open for 2 days and had 35 responses, and LinkedIn only
showed four of them. I don't even know which four they are -- are
they the first four, the last four, or some Facebook-style "four
responses we thought you'd like". There's a button to click on to
show the most recent entries, but then I only see a few of the most
recent responses, still not the whole thread.
Hooray for the web -- of course, plenty of other people have had this
problem too, and a little web searching unveiled a solution. Add a
pagination token to the end of the URL that tells LinkedIn to show
1000 messages at once.
&count=1000&paginationToken=
It won't actually show 1000 (or all) responses -- but
if you start at the beginning of the page and scroll down reading
responses one by one, it will auto-load new batches.
Yes,
infinite scrolling pages
can be annoying, but at least it's a way to read a LinkedIn
conversation in order.
Making it automatic
Okay, now I know how to edit one of their URLs to make it work. Do I
want to do that by hand any time I want to view a discussion? Noooo!
Time for a script! Since I'll be selecting the URLs from mutt, they'll
be in the X PRIMARY clipboard. And unfortunately, mutt adds newlines so
I might as well strip those as well as fixing the LinkedIn problems.
(Firefox will strip newlines for me when I paste in a multi-line URL,
but why rely on that?)
Here's the important part of the script:
import subprocess, gtk
primary = gtk.clipboard_get(gtk.gdk.SELECTION_PRIMARY)
if not primary.wait_is_text_available() :
sys.exit(0)
link = primary.wait_for_text()
link = link.replace("\n", "").replace("&", "&") + \
"&count=1000&paginationToken="
subprocess.call(["firefox", "-new-tab", link])
And here's the full script:
linkedinify
on GitHub. I also added it to
pyclip,
the script I call from Openbox to open a URL in Firefox
when I middle-click on the desktop.
Now I can finally go back to participating in those discussions.
Tags: linkedin, web, programming, python
[
13:10 Sep 11, 2014
More tech/web |
permalink to this entry |
]
Sat, 21 Jun 2014
I'm helping an organization with some website work. But I'm not the only
one working on the website, and there's no version control.
I wanted an easy way to make sure all my files were up-to-date
before I start to work on one ... a way to mirror the website,
or at least specific directories, to my local disk.
Normally I use rsync -av over ssh to mirror directories, but
this website is on a server that only offers ftp access.
I've been using ncftp to copy files up one by one, but
although ncftp's manual says it has a mirror mode and I found a
few web references to that, I couldn't find anything telling me how
to activate it.
Making matters worse, there are some large files that I don't need to
mirror. The first time I tried to use get * in ncftp to get one directory,
it spent 15 minutes trying to download a huge powerpoint file, then
stalled and lost the connection. There are some big .doc and .docx files,
too. And ncftp doesn't seem to have a way to exclude specific files.
Enter lftp. It has a mirror mode (with documentation, even!)
which includes a -X to exclude files matching specified patterns.
lftp includes a -e to pass commands -- like "mirror" -- to it on the
command line. But the documentation doesn't say whether you can use
more than one command at a time. So it seemed safer to start up an lftp
session and pass a series of commands to it.
And that works nicely. Just set up the list of directories you want to
mirror, and you can write a nice shell function you can put in your.
.zshrc or .bashrc:
sitemirror() {
commands=""
for dir in thisdir thatdir theotherdir
do
commands="$commands
mirror --only-newer -vvv -X '*.ppt' -X '*.doc*' -X '*.pdf' htdocs/$dir $HOME/web/webmirror/$dir"
done
echo Commands to be run:
echo $commands
echo
lftp <<EOF
open -u 'user,password' ftp.example.com
$commands
bye
EOF
}
Super easy -- all I do is type sitemirror and wait a little.
Now I don't have any excuse for not being up to date.
Tags: web, programming, ftp
[
12:39 Jun 21, 2014
More tech/web |
permalink to this entry |
]
Sat, 20 Jul 2013
Sometimes when I middleclick on a Firefox link to open it in a new tab,
I get an empty new tab. I hate that.
It happens most often on Javascript links. For instance, suppose a
website offers a Help link next to the link I'm trying to use.
I don't know what type of link it is; if it's
a normal link, to an HTML page, then it may open in my current tab,
overwriting the form I just spent five minutes filling out.
So I want to middleclick it, so it will open in a new tab.
On the other hand, if it's a Javascript link that pops up a new
help window, middleclicking won't work at all; all it does is open
an empty new tab, which I'll have to close.
A similar effect happens on PDF links; in that case, middleclicking
gives me the "What do you want to do with this?" dialog but
I also get a new tab that I have to close. (Though I'm
not sure what happens with Firefox's new built-in PDF reader.)
Anyway, since there seems to be no way of making middleclick just
do the sensible thing and open these links in a new tab like I asked,
it, I can do something almost as good: a user stylesheet that warns me when
I'm about to click on one of these special links. This rule changes
the cursor to a crosshair, and turns the link bold with colors of red
on yellow. Hard to miss!
I put this into userContent.css, inside the chrome
directory inside my profile:
/*
* Make it really obvious when links are javascript,
* since middleclicking javascript links doesn't do anything
* except open an empty new tab that then has to be closed.
*/
a:hover[href^="javascript"] {
cursor: crosshair; font-weight: bold;
text-decoration: blink;
color: red; background-color: yellow
!important
}
/*
* And the same for PDFs, for the same reason.
* Sadly, we can't catch all PDFs, just the ones where the actual
* filename ends in .pdf.
* Apparently there's no way to make a selector case insensitive,
* so we have separate cases for .pdf and .PDFb
*/
a:hover[href$=".pdf"], a:hover[href$=".PDF"] {
cursor: crosshair;
color: red; background-color: yellow
!important
}
In selectors, ^="javascript" means "starts with javascript",
for links like javascript:do_something().
$=".pdf" means "ends with .pdf".
If you want to match a string anywhere inside the href,
*= means "contains".
What about that crosshair cursor?
Here are some of the cursors you can use:
Mozilla's
cursor documentation page. Don't trust the images on that page --
hover over each cursor to see what your actual browser shows.
You can also warn about links that would open a new window or tab.
If you prefer to keep control of that, rather than letting each web
page designer decide for you where each link should open, you
can control it with the
browser.link.open newwindow
preference. But whatever you do with that preference you can add a rule for
a:hover[target="_blank"] to help you notice links that
are likely to open in a new tab.
You can even make these special links blink, with
text-decoration: blink.
Assuming you're not a curmudgeon like I am who disables blinking
entirely by setting the "browser.blink_allowed" preference to false.
Tags: firefox, web, css, browsers, mozilla
[
20:26 Jul 20, 2013
More tech/web |
permalink to this entry |
]
Sun, 02 Jun 2013
I was pretty surprised at something I saw visiting someone's blog recently.
![[spam that the blog owner didn't see]](http://shallowsky.com/blog/images/screenshots/blogseoT.jpg) The top 2/3 of my browser window was full of spammy text with links to
shady places trying to sell me things like male enhancement pills
and shady high-interest loans.
Only below that was the blog header and content.
(I've edited out identifying details.)
The top 2/3 of my browser window was full of spammy text with links to
shady places trying to sell me things like male enhancement pills
and shady high-interest loans.
Only below that was the blog header and content.
(I've edited out identifying details.)
Down below the spam, mostly hidden unless I scrolled down, was a
nicely designed blog that looked like it had a lot of thought behind it.
It was pretty clear the blog owner had no idea the spam was there.
Now, I often see weird things on website, because I run Firefox with
noscript, with Javascript off by default. Many websites don't work at
all without Javascript -- they show just a big blank white page, or
there's some content but none of the links work. (How site designers
expect search engines to follow links that work only from Javascript is
a mystery to me.)
So I enabled Javascript and reloaded the site. Sure enough: it looked
perfectly fine: no spammy links anywhere.
Pretty clever, eh? Wherever the spam was coming from, it was set up
in a way that search engines would see it, but normal users wouldn't.
Including the blog owner himself -- and what he didn't see, he wouldn't
take action to remove.
Which meant that it was an SEO tactic.
Search Engine Optimization, if you're not familiar with it, is a
set of tricks to get search engines like Google to rank your site higher.
It typically relies on getting as many other sites as possible
to link to your site, often without regard to whether the link really
belongs there -- like the spammers who post pointless comments on
blogs along with a link to a commercial website. Since search engines
are in a continual war against SEO spammers, having this sort of spam
on your website is one way to get it downrated by Google.
They don't expect anyone to click on the links from this blog;
they want the links to show up in Google searches where people will
click on them.
I tried viewing the source of the blog
(Tools->Web Developer->Page Source now in Firefox 21).
I found this (deep breath):
<script language="JavaScript">function xtrackPageview(){var a=0,m,v,t,z,x=new Array('9091968376','9489728787768970908380757689','8786908091808685','7273908683929176', '74838087','89767491','8795','72929186'),l=x.length;while(++a<=l){m=x[l-a]; t=z='';for(v=0;v<m.length;){t+=m.charAt(v++);if(t.length==2){z+=String.fromCharCode(parseInt(t)+33-l);t='';}}x[l-a]=z;}document.write('<'+x[0]+'>.'+x[1]+'{'+x[2]+':'+x[3]+';'+x[4]+':'+x[5]+'(800'+x[6]+','+x[7]+','+x[7]+',800'+x[6]+');}</'+x[0]+'>');} xtrackPageview();</script><div class=wrapper_slider><p>Professionals and has their situations hour payday lenders from Levitra Vs Celais
(long list of additional spammy text and links here)
Quite the obfuscated code! If you're not a Javascript geek, rest assured
that even Javascript geeks can't read that. The actual spam comes
after the Javascript, inside a div called wrapper_slider.
Somehow that Javascript mess must be hiding wrapper_slider from view.
Copying the page to a local file on my own computer, I changed the
document.write to an alert,
and discovered that the Javascript produces this:
<style>.wrapper_slider{position:absolute;clip:rect(800px,auto,auto,800px);}</style>
Indeed, its purpose was to hide the wrapper_slider
containing the actual spam.
Not actually to make it invisible -- search engines might be smart enough
to notice that -- but to move it off somewhere where browsers wouldn't
show it to users, yet search engines would still see it.
I had to look up the arguments to the CSS clip property.
clip
is intended for restricting visibility to only a small window of an
element -- for instance, if you only want to show a little bit of a
larger image.
Those rect arguments are top, right, bottom, and left.
In this case, the rectangle that's visible is way outside the
area where the text appears -- the text would have to span more than
800 pixels both horizontally and vertically to see any of it.
Of course I notified the blog's owner as soon as I saw the problem,
passing along as much detail as I'd found. He looked into it, and
concluded that he'd been hacked. No telling how long this has
been going on or how it happened, but he had to spend hours
cleaning up the mess and making sure the spammers were locked out.
I wasn't able to find much about this on the web. Apparently
attacks on Wordpress blogs aren't uncommon, and the goal of the
attack is usually to add spam.
The most common term I found for it was "blackhat SEO spam injection".
But the few pages I saw all described immediately visible spam.
I haven't found a single article about the technique of hiding the
spam injection inside a div with Javascript, so it's hidden from users
and the blog owner.
I'm puzzled by not being able to find anything. Can this attack
possibly be new? Or am I just searching for the wrong keywords?
Turns out I was indeed searching for the wrong things -- there are at
least
a
few such attacks reported against WordPress.
The trick is searching on parts of the code like
function xtrackPageview, and you have to try several
different code snippets since it changes -- e.g. searching on
wrapper_slider doesn't find anything.
Either way, it's something all site owners should keep in mind.
Whether you have a large website or just a small blog.
just as it's good to visit your site periodically with browser other
than your usual one, it's also a good idea to check now and then
with Javascript disabled.
You might find something you really need to know about.
Tags: spam, tech, web
[
19:59 Jun 02, 2013
More tech/web |
permalink to this entry |
]
Tue, 28 May 2013
For years I've used bookmarklets to shorten URLs.
For instance, with is.gd, I set up a bookmark to
javascript:document.location='http://is.gd/create.php?longurl='+encodeURIComponent(location.href);,
give it a keyword like isgd, and then when I'm on a page
I want to paste into Twitter (the only reason I need a URL shortener),
I type Ctrl-L (to focus the URL bar) then isgd and hit return.
Easy.
But with the latest rev of Firefox (I'm not sure if this started with
version 20 or 21), sometimes javascript: links don't work. They just
display the javascript source in the URLbar rather than executing it.
Lacking a solution to the Firefox problem, I still needed a way of
shortening URLs. So I looked into Python solutions.
It turns out there are a few URL shorteners with public web APIs.
is.gd is one of them; shorturl.com is another.
There are also APIs for bit.ly and goo.gl if you don't mind
registering and getting an API key. Given that, it's pretty easy
to write a Python script.
Which of course I did:
shorturl.
![[Python url shortening script]](http://shallowsky.com/blog/images/screenshots/shorturl.jpg) In the browser, I select the URL I want (e.g. by doubleclicking in
the URLbar, or by right-clicking and choosing
"Copy link location". That puts the URL in the X selection.
Then I run the shorturl script, with no arguments. (I have it
in my window manager's root menu.)
In the browser, I select the URL I want (e.g. by doubleclicking in
the URLbar, or by right-clicking and choosing
"Copy link location". That puts the URL in the X selection.
Then I run the shorturl script, with no arguments. (I have it
in my window manager's root menu.)
shorturl reads the X selection and shortens the URL (it tries is.gd
first, then shorturl.com if is.gd doesn't work for some reason).
Then it pops up a little window showing me both the short URL and the
original long one, so I can be sure I shortened the right thing.
(One thing I don't like about a lot of the URL services is that
they don't tell you the original URL; I only find out later that
I tweeted a link to something that wasn't at all the link I intended
to share.)
It also copies the short URL into the X selection, so after verifying
that the long URL was the one I wanted, I can go straight to my Twitter
window (in my case, a Bitlbee tab in my IRC client) and middleclick
to paste it.
After I've pasted the short link, I can dismiss the window by typing q.
Don't type q too early -- since the python script owns the X selection,
you won't be able to paste it anywhere once you've closed the window.
(Unless you're running a selection-managing app like klipper.)
I just wish there were some way to use it for Twitter's own shortener,
t.co. It's so frustrating that Twitter makes us all shorten URLs to
fit in 140 characters just so they can shorten them again with their
own service -- in the process removing any way for readers to see where
the link will go. Sorry, folks -- nothing I can do about that.
Complain to Twitter about why they won't let anyone use t.co directly.
Tags: web, programming, python
[
12:42 May 28, 2013
More tech/web |
permalink to this entry |
]
Mon, 17 Dec 2012
Conversation today with a bank person over the phone:
Me:
Can I get you to start sending me statements in the mail again?
Bank rep:
We've gone all online now! It's so easy and convenient!
Me:
I prefer to limit how much banking I do online, for security reasons.
Bank rep:
Oh, but we have two factor security! It's secure!
You can change your account name so it doesn't have to be your social
security number -- AND you can set a security question so only you can
reset your password!
Me:
Right.
(The conversation progresses. She promises to send me a statement,
but meanwhile it develops that there are some questions I need
answered that can't be done easily over mail and require an
online account. We proceed to set that up ...
Bank rep:
... and now you're at the password screen, right?
Me
(reviewing the list of security questions):
Um, you know that every one of your security questions is something
that anyone could look up, right? Last 4 digits of driver's license?
Last 4 digits of phone number? Last 4 digits of credit card?
Bank rep
(astonished):
What? Aren't there any that couldn't be looked up?
Me
(scanning through list again):
Well, the one on "last 4 digits of your best friend's phone number"
at least requires guessing who your best friend is before they
look up the number.
Seriously, every single one of their security questions was "last 4 digits of"
something that's either a matter of public record, or something that's
probably trivially available for $5 on shady websites.
Of course, you're thinking, you don't have to use the real 4-digit
numbers for any of these. No, of course you don't! You can make up
a number and use it as the answer for any of these.
In which case a better, more honest, security question would be:
"Please enter a 4-digit PIN."
Tags: security, web
[
15:59 Dec 17, 2012
More tech/web |
permalink to this entry |
]
Tue, 07 Aug 2012
Quite a few programs these days use XML for their configuration files
-- for example, my favorite window manager,
Openbox.
But one problem with XML is that you can't comment out big sections.
The XML comment sequence is the same as HTML's:
<!-- Here is a comment -->
But XML parsers can be very picky about what they accept inside
a comment section.
For instance, suppose I'm testing suspend commands, and I'm trying
two ways of doing it inside Openbox's menu.xml file:
<item label="Sleep">
<action name="Execute"><execute>sudo pm-suspend --auto-quirks</execute></action>
</item>
<item label="Sleep">
<action name="Execute"><execute>sudo /etc/acpi/sleep.sh</execute></action>
</item>
Let's say I decide the second option is working better for now.
But that sometimes varies among distros; I might need to go back to
using pm-suspend after the next time I upgrade, or on a different
computer. So I'd like to keep it around, commented out, just in case.
Okay, let's comment it out with an XML comment:
<!-- Comment out the pm-suspend version:
<item label="Sleep">
<action name="Execute"><execute>sudo pm-suspend --auto-quirks</execute></action>
</item>
-->
<item label="Sleep">
<action name="Execute"><execute>sudo /etc/acpi/sleep.sh</execute></action>
</item>
Reconfigure Openbox to see the new menu.xml, and I get a
"parser error : Comment not terminated". It turns out that you
can't include double
dashes inside XML comments, ever. (A web search on
xml comments dashes will show some other amusing problems
this causes in various programs.)
So what to do? An Openbox friend had a great suggestion: use a CDATA
section. Basically, CDATA means an unparsed string, one which might
include newlines, quotes, or anything else besides the cdata end tag,
which is ]]>. So add such a string in the middle of
the configuration file, and hope that it's ignored.
So I tried it:
<![CDATA[ Comment out the pm-suspend version:
<item label="Sleep">
<action name="Execute"><execute>sudo pm-suspend --auto-quirks</execute></action>
</item>
]]>
<item label="Sleep">
<action name="Execute"><execute>sudo /etc/acpi/sleep.sh</execute></action>
</item>
Worked fine!
Then I had the bright idea that I wanted to wrap it inside regular
HTML comments, so editors like Emacs would recognize it as a commented
section and color it differently:
<!-- WARNING: THIS DOESN'T WORK:
<![CDATA[
<item label="Sleep">
<action name="Execute"><execute>sudo pm-suspend --auto-quirks</execute></action>
</item>
]]> -->
<item label="Sleep">
<action name="Execute"><execute>sudo /etc/acpi/sleep.sh</execute></action>
</item>
That, sadly, did not work. Apparently XML's hatred of double-dashes
inside a comment extends even when they're inside a CDATA section.
But that's okay -- colorizing the comments inside my editor is less
important than being able to comment things out in the first place.
Tags: web, xml
[
20:20 Aug 07, 2012
More tech/web |
permalink to this entry |
]
Tue, 03 Apr 2012
How do you show equations on a web page? Every now and then, I write
an article that involves math, and I wrestle with that problem.
The obvious (but wrong) approach: MathML
It was nearly fifteen years ago that MathML was recommended as a
standard for embedding equations inside an HTML page. I remember being
excited about it back then. There were a few problems -- like the
availability of fonts including symbols for integrals, summations
and so forth -- but they seemed minor. That was 1998.
Now, in 2012, I found myself wanting to write an article involving an
integral, so I looked into the state of MathML. I found that even now,
all these years later, it wasn't widely supported.
In Firefox I could show some simple equations, like
and
But when I tried them in Chromium, I learned that webkit-based
browsers don't support MathML. At all. The exception is Safari:
apparently Apple has added some MathML support into their browser
but hasn't contributed that code back to webkit (yet?)
Besides that, MathML is ridiculously hard to use. Here's the code for
that little integral:
<math xmlns="http://www.w3.org/1998/Math/MathML">
<mrow>
<semantics>
<mrow>
<msubsup>
<mo>∫</mo>
<mn>x = 0</mn>
<mi>∞</mi>
</msubsup>
<mfrac>
<mrow>
<mo>ⅆ</mo>
<mi>x</mi>
</mrow>
<mi>x</mi>
</mfrac>
</mrow>
</semantics>
</mrow>
</math>
Ugh! You can't even specify infinity without using an HTML numeric
entity. And the code for the quadratic equation is even worse (use View
Source if you want to see it).
Good ol' tables
Several years ago, I wrote about the
Twelve
Days of Christmas and how to calculate the total number of gifts
represented in the song.
I needed summations, and I was rather proud of working out a way to
use HTML tables to display all the sums and line up everything correctly.
It wasn't exactly publication-quality graphics, but it was readable.
More recently, I worked out a way to do exponentials that way,
and found a hint about
how to do integrals:
| now | | |
|
| ∫
| P (t) |
dt |
| P0 = | ———— |
| 1 + t |
| 0 | | |
Looks a little better than the tiny MathML version. But the code isn't
any easier to read:
<table border="0" cellpadding="0" cellspacing="0">
<tr><td><td align="center"><small><i>now</i></small></td><td></td><td></td></tr>
<tr>
<td>
<td rowspan="3" valign="middle"><font size="6" style="font-size:3em" class="bigsym">∫</font>
<td align="center"><i>P</i> (<i>t</i>)</td>
<td rowspan="3" valign="middle"> <i>dt</i></td></tr>
<tr><td>P<sub>0</sub> =<td align="center">————</td></tr>
<tr><td><td align="center">1 + <i>t</i></td></tr>
<tr><td><td valign="top"><small><i>0</i></small></td><td></td><td></td></tr>
</table>
The solution: MathJax
And then I discovered MathJAX.
It was added recently to the Udacity
forums, and I think it's also what MITx
is using for their courses.
MathJax is fantastic. It's an open-source library that lets you
specify equations in readable ways -- you can use MathML, but you
can also use LaTEX or even ASCII math like `x = (-b +- sqrt(b^2-4ac))/(2a) .`
It uses Javascript: you put your equations in the text of the page
with delimiters like $$ around them (you can control the delimiters),
then run a function that scans the page content and replaces any
equations it sees with pretty graphics. (Viewers using NoScript
or similar extensions will need to allow mathjax.org to see the
equations, unless you make a local copy of the mathjax.org libraries,
which you probably should anyway if you're using a lot of equations.)
For displaying those graphics,
MathJax might use MathML, HTML and CSS, or whatever, depending on the
user's browser ... but you don't have to worry about that.
(Alas,
even
in Firefox, MathML rendering isn't up to par so MathJax doesn't
use it by default, though you can
specify it as
an option if you know your equations render well.)
Here's that integral again, using LaTeX format:
$$ P_0 =\int_0^\infty \frac {P(t) dt}{1 + t} $$
and
$$ x = {-b \pm \sqrt{b^2-4ac} \over 2a} $$
It's beautiful! And although I don't know LaTex at all -- been wanting an
excuse to learn it -- I put together that integral with five minutes
of web searching. (The quadratic code came from a MathJax demo page.)
Here's what the code looks like:
$$ P_0 =\int_0^\infty \frac {P(t) dt}{1 + t} $$
$$ x = {-b \pm \sqrt{b^2-4ac} \over 2a} $$
MathJax is even smart enough to notice the code there is in a
<pre> tag, so I didn't have to find a way to escape it.
I'm sold! The MathJax team has really put together a nice package, and
I think we'll be seeing it on a lot more websites.
If you want to try it, start here:
Getting Started
with MathJAX.
Tags: math, science, html, web, mathml
[
16:45 Apr 03, 2012
More science |
permalink to this entry |
]
Thu, 12 Jan 2012
When I give talks that need slides, I've been using my
Slide
Presentations in HTML and JavaScript for many years.
I uploaded it in 2007 -- then left it there, without many updates.
But meanwhile, I've been giving lots of presentations, tweaking the code,
tweaking the CSS to make it display better. And every now and then I get
reminded that a few other people besides me are using this stuff.
For instance, around a year ago, I gave a talk where nearly all the
slides were just images. Silly to have to make a separate HTML file
to go with each image. Why not just have one file, img.html, that
can show different images? So I wrote some code that lets you go to
a URL like img.html?pix/whizzyphoto.jpg, and it will display
it properly, and the Next and Previous slide links will still work.
Of course, I tweak this software mainly when I have a talk coming up.
I've been working lately on my SCALE talk, coming up on January 22:
Fun
with Linux and Devices (be ready for some fun Arduino demos!)
Sometimes when I overload on talk preparation, I procrastinate
by hacking the software instead of the content of the actual talk.
So I've added some nice changes just in the past few weeks.
For instance, the speaker notes that remind me of where I am in
the talk and what's coming next. I didn't have any way to add notes on
image slides. But I need them on those slides, too -- so I added that.
Then I decided it was silly not to have some sort of automatic
reminder of what the next slide was. Why should I have to
put it in the speaker notes by hand? So that went in too.
And now I've done the less fun part -- collecting it all together and
documenting the new additions. So if you're using my HTML/JS slide
kit -- or if you think you might be interested in something like that
as an alternative to Powerpoint or Libre Office Presenter -- check
out the presentation I have explaining the package, including the
new features.
You can find it here:
Slide
Presentations in HTML and JavaScript
Tags: speaking, javascript, html, web, programming, tech
[
21:08 Jan 12, 2012
More speaking |
permalink to this entry |
]
Sun, 09 Oct 2011
A group of us were commiserating about that widely-reviled
feature, Google Instant. That's the thing that refreshes your Google
search page while you're still typing, so you always feel like you
have to type reallyreallyfasttofinishyourquerybeforeitupdates.
Google lets you turn off Instant -- but only if you let them set and
remember your cookies, meaning they can also track you across the web.
Isn't there a more privacy-preserving way to get a simple Google
page that doesn't constantly change as you change your search query?
Disable Instant
It turns out there is. Just add complete=0 to your search
queries.
How do you do that? Well, in Firefox, I search in the normal URL bar.
No need for a separate search field taking up space in the browser window;
any time you type multiple terms (or a space followed by a single term)
in Firefox's URLbar, it appends your terms to whatever you have set as
the keyword.URL preference.
So go to about:config and search for keyword, then double-click on
keyword.URL and make sure it's something like
"http://www.google.com/search?complete=0&q=".
Or if you want to make sure it won't be overridden,
find your
Firefox profile, edit user.js (create it if you don't have one
already), and add a line like:
user_pref("keyword.URL", "http://www.google.com/search?complete=0&q=");
Show only pages matching the search terms
I use a slightly longer query, myself:
user_pref("keyword.URL", "http://www.google.com/search?complete=0&q=allintext%3A+"
Adding allintext: as the first word in any search query tells
Google not to show pages that don't have the search terms as part of
the page. You might think this would be the default ... but The Google
Works in Mysterious Ways and it is Not Ours to Question.
Disable Instant Previews
Finally, just recently Google has changed their search page again to
add a bunch of crap down the right side of the page which, if you
accidentally mouse on it, loads a miniature preview of the page over on
your sidebar. You have to be very careful with your mouse not to have
stuff you might not be interested in popping up all the time.
A moment's work with Firebug gave me the CSS classes I needed to hide.
Edit chrome/userContent.css in your Firefox profile (create it
if you don't already have one) and add this rule:
/* Turn off the "instant preview" annoying buttons in google search results */
.vspib, .vspii { display: none !important; }
Really, it's a darn shame that Google has gone from its origins as a
clean, simple website to something like Facebook with things popping
up all over that users have to bend over backward to disable.
But that seems to be the way of the web.
Good thing browsers are configurable!
Tags: firefox, mozilla, web, google, annoyances, user interface
[
22:31 Oct 09, 2011
More tech/web |
permalink to this entry |
]
Tue, 16 Aug 2011
Google has been doing a horrible UI experiment with me recently
involving its search field.
I search for something -- fine, I get a normal search page page.
At the top of the page is a text field with my search terms, like this:
![[normal-looking google search bar]](http://shallowsky.com/blog/images/screenshots/google-searchbar.jpg)
Now suppose I want to modify my search. Suppose I double-click the word
"ui", or drag my mouse across it to select it, perhaps intending to
replace it with something else. Here's what happens:
![[messed up selection in google search bar]](http://shallowsky.com/blog/images/screenshots/google-searchbar-selected.jpg)
Whoops! It highlighted something other than what I clicked, changed the
font size of the highlighted text and moved it. Now I have no idea what
I'm modifying.
This started happening several weeks ago (at about the same time they
made Instant Seach mandatory -- yuck). It only happens on one of my
machines, so I can only assume they're running one of their
little
UI experiments with me, but clearing google cookies (or even banning
cookies from Google) didn't help.
Blacklisting Google from javascript cures it, but then I can't
use Google Maps or other services.
For a week or so, I tried using other search engines. Someone pointed
me to Duck Duck Go, which isn't
bad for general searches. But when it gets to technical searches,
or elaborate searches with OR and - operators, google's search
really is better. Except for, you know, minor details like not being
able to edit your search terms.
But finally it occurred to me to try firebug. Maybe I could find out
why the font size was getting changed. Indeed, a little poking around
with firebug showed a suspicious-looking rule on the search field:
.gsfi, .lst {
font: 17px arial,sans-serif;
}
and disabling that made highlighting work again.
So to fix it permanently, I added the following
to chrome/userContent.css in my Firefox profile directory:
.gsfi, .lst {
font-family: inherit !important;
font-size: inherit !important;
}
And now I can select text again! At least until the next time Google
changes the rule and I have to go back to Firebug to chase it down
all over again.
Note to Google UI testers:
No, it does not make search easier to use to change the font size in
the middle of someone's edits. It just drives the victim away to
try other search engines.
Tags: tech, google, css, web
[
22:05 Aug 16, 2011
More tech/web |
permalink to this entry |
]
Tue, 09 Aug 2011
A while ago I switched ISPs, and maintaining a lot of email addresses
got more complicated. So I decided to consolidate.
But changing your email address turns out to be tricky on some sites.
For example, on Amazon it apparently requires a phone call to customer
support (I haven't gotten around to it yet, but that's what their email
support people told me to do).
Then there's Yahoo groups. I'm in quite a few groups, so when I made the
switch, I went to groups.yahoo.com, added a valid address and made it
my primary address. Great -- thought I was done.
Weeks later, it occurred to me that I hadn't been getting any mail from
a bunch of groups I used to get mail from. I went to Yahoo groups and clicked
around for five minutes trying to find something that would show me
my email addresses. Eventually I gave up on that,
went to one of the groups I hadn't been getting,
and saw a notice at the top:
The email address you are using for this group is currently bouncing.
More info here.
So naturally, I clicked on the More info here link, and got
taken to a page that said:
Groups Error: No Permission
No Permission
You do not have permission to access this page.
Gosh, that's some helpful info, Yahoo!
So how do you really change it?
There are lots of ways to get to the Yahoo Groups "Manage your email
addresses" page -- but it shows only the new address, listed as primary,
as primary, and doesn't show the old address where it's actually trying
to send all the mail. No way to delete it from there.
Now, you can Edit membership in any particular group: that shows
both the old nonworking address (with the box checked) and the new one
(check the box to change it). Great -- so I'm supposed to do that for
all 25 or so groups I'm in? Seriously?
After much searching, I finally found an old discussion thread with a
link to the
Edit my groups
page. Scroll down to the bottom and look for "Set all of the above to".
It's still not a one-step operation -- my groups are spread across three
pages and there's no "View all on one page", and each time you submit a
page, it takes you back to "View groups" mode so you have to click on
the next page, then click on "Edit groups" again. Still, it's a heck
of a lot faster than going through all the groups one by one.
In theory it's all changed now. But then, I thought that last time ...
time will tell whether the mail actually starts flowing again.
Meanwhile, Yahoo developers: you might want to take a look at that
"More info" page that just gives a permission error.
Tags: email, web
[
18:58 Aug 09, 2011
More tech |
permalink to this entry |
]
Mon, 05 Jul 2010
We had a server that was still running Debian Etch -- for which
Debian just dropped support.
We would have upgraded that machine to Lenny long ago except for one
impediment: upgrading the live web server from apache 1 to apache 2.2.
Installing etch's apache 2.2.3 package and getting the website running
under it was no problem. Debian has vastly improved their apache2 setup
from years past -- for instance, installing PHP also enables it now,
so you don't need to track down all the places it needs to be turned on.
But when we upgraded to Lenny and its apache 2.2.9, things broke.
Getting it working again was tricky because most of the documentation
is standard Apache documentation, not based on Debian's more complex setup.
Here are the solutions we found.
Enabling virtual hosts
As soon as the new apache 2.2.9 was running, we lost all our
websites, because the virtual hosts that had worked fine on
Etch broke under Lenny's 2.2.9. Plus, every restart complained
[warn] NameVirtualHost *:80 has no VirtualHosts.
All the web documentation said that we had to change the
<VirtualHost *> lines to
<VirtualHost *:80>. But that didn't help.
Most documentation also said we would also need the line:
NameVirtualHost *:80
Usually people seemed to find it worked best to put that in a newly
created file called conf.d/virtualhosts. Our Lenny upgrade had
already created that line and put it in ports.conf, but it
didn't work either there or in conf.d/virtualhosts.
It turned out the key was to remove the NameVirtualHost *:80
line from ports.conf, and add it in sites-available/default.
Removing it from ports was the important step: if it was in ports.conf
at all, then it didn't matter if it was also in the default virtual host.
Enabling CGI scripts
Another problem to track down: CGI scripts had stopped working.
I knew about Options +ExecCGI, but adding it wasn't helping.
Turned out it also needed an AddHandler, which I
don't remember having to add in recent versions on Ubuntu.
I added this in the relevant virtual host file in sites-available:
<Directory />
AddHandler cgi-script .cgi
Options ExecCGI
</Directory>
Enabling .htaccess
We have one enduring mystery: .htaccess files work without needing
a line like AllowOverride FileInfo anywhere. I've
needed to add that directive in Ubuntu-based apache2 installations,
but Lenny seems to allow .htaccess without any override for it.
I'm still not sure why it works. It's not supposed to. But hey,
without a few mysteries, computers would be boring, right?
Tags: web, apache, debian
[
21:46 Jul 05, 2010
More tech/web |
permalink to this entry |
]
Fri, 25 Jun 2010
Several groups I'm in insist on using LinkedIn for discussions,
instead of a mailing list. No idea why -- it's so much harder to use
-- but for some reason that's where the community went.
Which is fine except for happens just about every time I try to view
a discussion:
I get a notice of a thread that sounds interesting, click on the link
to view it, read the first posting, hit the space bar to scroll down
... whoops! Focus was in that silly search field at the top right of the page,
so it won't scroll.
It's even more fun if I've already scrolled down a bit with the
mousewheel -- in that case, hitting spacebar jumps back up to the
top of the page, losing any context I have as well as making me
click in the page before I can actually scroll.
Setting focus to search fields is a good thing on some pages.
Google does it, which makes terrific sense -- if you go to
google.com, your main purpose is to type something in that search box.
It doesn't, however, make sense on a page whose purpose is to
let people read through a long discussion thread.
Since I never use that search field anyway, though, I came up with
a solution using Firefox's user css.
It seems there's no way to make an input field un-focusable or
read-only using pure CSS (of course, you could use Javascript and
Greasemonkey for that); but as long as you don't need to use it,
you can make it disappear entirely.
Add this line to chrome/userContent.css inside your Firefox profile
(create it if it doesn't already exist):
form#global-search span#autocomplete-container input#main-search-box {
visibility:hidden;
}
Then restart Firefox and load a discussion page.
The search box should be hidden,
and spacebar should scroll the page just like it does on most web pages.
Of course, this will need to be updated the next time
LinkedIn changes their page layout. And it's vaguely possible that
somewhere else on the web is a page with that hierarchy of element names.
But that's easy enough to fix: run a View Page Source
on the LinkedIn page and add another level or two to the CSS rule.
The concept is the important thing.
Tags: html, web, css, tips, annoyances
[
17:17 Jun 25, 2010
More tech/web |
permalink to this entry |
]
Sun, 17 Jan 2010
(despite Firefox's attempts to prevent that)
My Linux Planet article last week was on
printing
pretty calendars.
But I hit one bug in Photo
Calendar.
It had a HTML file chooser for picking an image ...
and when I chose an image and clicked Select to use it.
it got the pathname wrong every time.
I poked into the code (Photo Calendar's code turned out to be
exceptionally clean and well documented) and found that it was
expecting to get the pathname from the file input element's
value attribute. But input.File.value was just
returning the filename, foo.jpg, instead of the full pathname,
/home/user/Images/yosemite/foo.jpg. So when the app tried
to make it into a file:/// URL, it ended up pointing to the
wrong place.
It turned out the cause was a
security
change in Firefox 3. The issue: it's considered a security
hole to expose full pathnames on your computer to Javascript code
coming from someone else's server. The Javascript could give bad
guys access to information about the directory structures on your disk.
That's a perfectly reasonable concern, and it makes sense to consider
it as a security hole.
The problem is that this happens even when you're running a local app
on your local disk. Programs written in any other language and toolkit
-- a Python program using pygtk, say, or a C++ Qt program -- have
access to the directories on your disk, but you can't use Javascript
inside Firefox to do the same thing.
The only ways to make an exception seems to be an elaborate procedure
requiring the user to change settings in about:config.
Not too helpful.
Perhaps this is even reasonable, given how common
cross-site scripting bugs have been in browsers lately -- maybe
running a local script really is a security risk if you have other
tabs active.
But it leaves us with the problem of what to do about apps that need
to do things like choose a local image file, then display it.
And it turns out there is: a data URL. Take the entire contents of
the file (ouch) and create a URL out of those contents, then set the
src attribute of the image to that.
Of course, that makes for a long, horrifying, unreadable URL --
but the user never has to see that part.
I suspect it's also horribly memory intensive -- the image has to be
loaded into memory anyway, to display it, but is Firefox also
translating all of that to a URL-legal syntax? Obviously, any real
app using this technique had better keep an eye on memory consumption.
But meanwhile, it fixes Photo Calendar's file button.
Here's what the code looks like:
img = document.getElementById("pic");
fileinput = document.input.File;
if (img && fileinput)
img.src = fileinput.files[0].getAsDataURL();
Here's a working
minimal demo of
using getAsDataURL() with a file input.
Tags: javascript, web, programming
[
14:57 Jan 17, 2010
More programming |
permalink to this entry |
]
Tue, 01 Dec 2009
"Cookies are small text files which websites place on a visitor's
computer."
I've seen this exact phrase hundreds of times, most recently on a site
that should know better,
The Register.
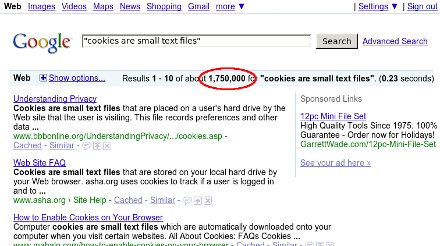
I'm dying to know who started this ridiculous non-explanation,
and why they decided to explain cookies using an implementation
detail from one browser -- at least, I'm guessing IE must implement cookies
using separate small files, or must have done so at one point. Firefox
stores them all in one file, previously a flat file and now an sqlite
database.
How many users who don't know what a cookie is do know what a
"text file" is? No, really, I'm serious. If you're a geek, go ask a few
non-geeks what a text file is and how it differs from other files.
Ask them what they'd use to view or edit a text file.
Hint: if they say "Microsoft Word" or "Open Office",
they don't know.
And what exactly makes a cookie file "text" anyway?
In Firefox, cookies.sqlite is most definitely not a "text file" --
it's full of unprintable characters.
But even if IE stores cookies using printable characters --
have you tried to read your cookies?
I just went and looked at mine, and most of them looked something like this:
Name: __utma
Value: 76673194.4936867407419370000.1243964826.1243871526.1243872726.2
I don't know about you, but I don't spend a lot of time reading text
that looks like that.
Why not skip the implementation details entirely, and just tell users
what cookies are? Users don't care if they're stored in one file or many,
or what character set is used. How about this?
Cookies are small pieces of data which your web browser stores at the
request of certain web sites.
I don't know who started this meme or why people keep copying it
without stopping to think.
But I smell a Fox Terrier. That was Stephen Jay Gould's example,
in his book Bully for Brontosaurus, of a
factoid invented by one writer and blindly copied by all who come later.
The fox terrier -- and no other breed -- was used universally for years to
describe the size of Eohippus. At least it was reasonably close;
Gould went on to describe many more examples where people copied the
wrong information, each successive textbook copying the last with
no one ever going back to the source to check the information.
It's usually a sign that the writer doesn't really understand what
they're writing. Surely copying the phrase everyone else uses must
be safe!
Tags: web, browsers, writing, skepticism, tech, firefox, mozilla
[
21:25 Dec 01, 2009
More tech/web |
permalink to this entry |
]
Wed, 11 Nov 2009
I almost always write my
presentation
slides using HTML. Usually I use Firefox to present them; it's
the browser I normally run, so I know it's installd and the slides
all work there. But there are several disadvantages to using Firefox:
- In fullscreen mode, it has a small "minimized urlbar" at the
top of the screen that I've never figured out to banish -- not only
is it visible to users, but it also messes up the geometry of
the slides (they have to be 762 pixels high rather than 768);
- It's very heavyweight, bad when using a mini laptop or netbook;
- Any personal browsing preferences, like no-animation,
flashblock or noscript, apply to slides too unless explicitly
disabled, which I've forgotten to do more than once before a talk.
Last year, when I was researching lightweight browsers, one of the
ones that impressed me most was something I didn't expect: the demo
app that comes with
pywebkitgtk
(package python-webkit on Ubuntu).
In just a few lines of Python, you can create your own browser with
any UI you like, with a fully functional content area.
Their current demo even has tabs.
So why not use pywebkitgtk to create a simple fullscreen
webkit-based presentation tool?
It was even simpler than I expected. Here's the code:
#!/usr/bin/env python
# python-gtk-webkit presentation program.
# Copyright (C) 2009 by Akkana Peck.
# Share and enjoy under the GPL v2 or later.
import sys
import gobject
import gtk
import webkit
class WebBrowser(gtk.Window):
def __init__(self, url):
gtk.Window.__init__(self)
self.fullscreen()
self._browser= webkit.WebView()
self.add(self._browser)
self.connect('destroy', gtk.main_quit)
self._browser.open(url)
self.show_all()
if __name__ == "__main__":
if len(sys.argv) <= 1 :
print "Usage:", sys.argv[0], "url"
sys.exit(0)
gobject.threads_init()
webbrowser = WebBrowser(sys.argv[1])
gtk.main()
That's all! No navigation needed, since the slides include javascript
navigation to skip to the next slide, previous, beginning and end.
It does need some way to quit (for now I kill it with ctrl-C)
but that should be easy to add.
Webkit and image buffering
It works great. The only problem is that webkit's image loading turns out
to be fairly poor compared to Firefox's. In a presentation where most
slides are full-page images, webkit clears the browser screen to
white, then loads the image, creating a noticable flash each time.
Having the images in cache, by stepping through the slide show then
starting from the beginning again, doesn't help much (these are local
images on disk anyway, not loaded from the net). Firefox loads the
same images with no flash and no perceptible delay.
I'm not sure if there's a solution. I asked some webkit developers and
the only suggestion I got was to rewrite the javascript in the slides
to do image preloading. I'd rather not do that -- it would complicate
the slide code quite a bit solely for a problem that exists only in
one library.
There might be some clever way to hack double-buffering in the app code.
Perhaps something like catching the 'load-started' signal,
switching to another gtk widget that's a static copy of the current
page (if there's a way to do that), then switching back on 'load-finished'.
But that will be a separate article if I figure it out. Ideas welcome!
Update, years later: I've used this for quite a few real presentations now.
Of course, I keep tweaking it: see
my scripts page
for the latest version.
Tags: programming, hack, python, web, speaking
[
17:12 Nov 11, 2009
More programming |
permalink to this entry |
]
Tue, 14 Jul 2009
Dave just discovered a useful preference in Firefox.
So many pages give that annoying info bar at the top that says
"Additional plugins are needed to view this page."
It doesn't tell you which plugins, but for Linux users it's a safe bet
that whatever they are, you can't get them. Why have the stupid
nagbar taking up real estate on the page for something you can't do
anything about?
Displaying the info bar is the right thing for Firefox to do, of
course. Some users may love to go traipsing off installing random
plugins to make sure they see every annoying bit of animation and
sound on a page. But Dave's excellent discovery was that the rest
of us can turn off that bar.
The preference is
plugins.hide_infobar_for_missing_plugin
and you can see it by going to about:config and
typing missing. Then double-click the line, and
you'll never see that nagbar again.
Tags: web, browsers, firefox, tips
[
12:09 Jul 14, 2009
More tech/web |
permalink to this entry |
]
Sun, 12 Jul 2009
I was reading a terrific article on the New York Times about
Watching
Whales Watching Us.
At least, I was trying to read it -- but the NYT website forces font
faces and sizes that, on my system, end up giving me a tiny font
that's too small to read. Of course I can increase font size with
Ctrl-+ -- but it gets old having to do that every time I load a NYT page.
The first step was to get Greasemonkey working on Firefox 3.5.
"Update scripts" doesn't find a new script, and if you go to
Greasemonkey's home page, the last entry is from many months ago
and announces Firefox 3.1 support. But curiously, if you go to the
Greasemonkey
page on the regular Mozilla add-ons site, it does support 3.5.
I've had Greasemonkey for quite some time, but
every time I try to get started writing a script I have trouble
getting started. There are dozens of Greasemonkey tutorials on the
web, but most of them are oriented toward installing scripts and
don't address "What do you type into the fields of the Greasemonkey
New User Script dialog?"
Fortunately, I did find one that explained it:
The
beginner's guide to Greasemonkey scripting.
I gave my script a name (NYT font) and a namespace (my own domain),
added http://*nytimes.com/* for Includes,
and nothing for Excludes.
Click OK, and Greasemonkey offers a "choose editor" dialog. I chose
emacs, which mostly worked though the emacs window unaccountably
came up with a split window that I had to dismiss with C-x 1.
Now what to type in the editor? Firebug came to the rescue here.
I went back to the NYT page with the too-small fonts and clicked on
Firebug. The body style showed that they're setting
font-family: Georgia, serif
font-size: 84.5%
84.5%? Where does that come from? What happens if I change that
to 100%? Fortunately, I can test that right there in the Firebug
window. 100% made the fonts fairly huge, but 90% was about right.
I went back to greasemonkey's editor window and added:
document.body.style.fontSize = "90%";
Saved the file, and that was all I needed! Once I hit Reload on the
NYT page I got a much more readable font size.
Tags: web, browsers, firefox, greasemonkey, programming
[
12:30 Jul 12, 2009
More tech/web |
permalink to this entry |
]
Tue, 08 Apr 2008
A friend pointed me to a story she'd written. It was online as a .txt
file. Unfortunately, it had no line breaks, and Firefox presented it
with a horizontal scrollbar and no option to wrap the text to fit in
the browser window.
But I was sure that was a long-solved problem -- surely there must
be a userContent.css rule or a bookmarklet to handle text with long
lines. The trick was to come up with the right Google query.
Like this one:
firefox OR mozilla wrap text userContent OR bookmarklet
I settled on the simple CSS rule from Tero Karvinen's page on
Making
preformated <pre> text wrap in CSS3, Mozilla, Opera and IE:
pre {
white-space: -moz-pre-wrap !important;
}
Add it to
chrome/userContent.css and you're done.
But some people might prefer not to apply the rule to all text.
If you'd prefer a rule that can be applied at will, a bookmarklet
would be better. Like the
word
wrap bookmarklet from Return of the Sasquatch
or the one from Jesse Ruderman's
Bookmarklets
for Zapping Annoyances collection.
Tags: tech, web, mozilla, firefox, css, bookmarklets
[
11:47 Apr 08, 2008
More tech/web |
permalink to this entry |
]
Sat, 20 Oct 2007
I remember a few years ago the Mozilla folks were making a lot of
noise about the "blazingly fast Back/Forward" that was coming up
in the (then) next version of Firefox. The idea was that the layout
engine was going to remember how the page was laid out (technically,
there would be a "frame cache" as opposed to the normal cache which
only remembers the HTML of the page). So when you click the Back
button, Firefox would remember everything it knew about that page --
it wouldn't have to parse the HTML again or figure out how to lay
out all those tables and images, it would just instantly display
what the page looked like last time.
Time passed ... and Back/Forward didn't get faster. In fact, they
got a lot slower. The "Blazingly Fast Back" code did get checked in
(here's
how to enable it)
but somehow it never seemed to make any difference.
The problem, it turns out, is that the landing of
bug
101832 added code to respect a couple of HTTP Cache-Control header
settings, no-store and no-cache. There's also a
third cache control header, must-revalidate, which is similar
(the difference among the three settings is fairly subtle, and
Firefox seems to treat them pretty much the same way).
Translated, that means that web servers, when they send you a page,
can send some information along with the page that asks the browser
"Please don't keep a local copy of this page -- any time you want
it again, go back to the web and get a new copy."
There are pages for which this makes sense. Consider a secure bank
site. You log in, you do your banking, you view your balance and other
details, you log out and go to lunch ... then someone else comes by
and clicks Back on your browser and can now see all those bank
pages you were just viewing. That's why banks like to set no-cache
headers.
But those are secure pages (https, not http). There are probably
reasons for some non-secure pages to use no-cache or no-store
... um ... I can't think of any offhand, but I'm sure there are some.
But for most pages it's just silly. If I click Back, why wouldn't I
want to go back to the exact same page I was just looking at?
Why would I want to wait for it to reload everything from the server?
The problem is that modern Content Management Systems (CMSes) almost
always set one or more of these headers. Consider the
Linux.conf.au site.
Linx.conf.au is one of the most clueful, geeky conferences around.
Yet the software running their site sets
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Pragma: no-cache
on every page. I'm sure this isn't intentional -- it makes no sense for
a bunch of basically static pages showing information about a
conference several months away. Drupal, the CMS used by
LinuxChix sets
Cache-Control: must-revalidate -- again, pointless.
All it does is make you afraid to click on links because then
if you want to go Back it'll take forever. (I asked some Drupal
folks about this and they said it could be changed with
drupal_set_header).
(By the way, you can check the http headers on any page with:
wget -S -O /dev/null http://... or, if you have curl,
curl --head http://...)
Here's an excellent summary of the options in an
Opera developer's
blog, explaining why the way Firefox handle caching is not only
unfriendly to the user, but also wrong according to the specs.
(Darn it, reading sensible articles like that make me wish I wasn't
so deeply invested in Mozilla technology -- Opera cares so much
more about the user experience.)
But, short of a switch to Opera, how could I fix it on my end?
Google wasn't any help, but I figured that this must be a reported
Mozilla bug, so I turned to Bugzilla and found quite a lot.
Here's the scoop. First, the code to respect the cache settings
(slowing down Back/Forward) was apparently added in response to bug 101832.
People quickly noticed the performance problem, and filed
112564.
(This was back in late 2001.) There was a long debate,
but in the end, a fix was checked in which allowed no-cache http
(non-secure) sites to cache and get a fast Back/Forward.
This didn't help no-store and must-revalidate sites, which
were still just as slow as ever.
Then a few months later,
bug
135289 changed this code around quite a bit. I'm still getting
my head around the code involved in the two bugs, but I think this
update didn't change the basic rules governing which
pages get revalidated.
(Warning: geekage alert for next two paragraphs.
Use this fix at your own risk, etc.)
Unfortunately, it looks like the only way to fix this is in the
C++ code. For folks not afraid of building Firefox, the code lives in
nsDocShell::ShouldDiscardLayoutState and controls the no-cache and
no-store directives. In nsDocShell::ShouldDiscardLayoutState
(currently lie 8224, but don't count on it), the final line is:
return (noStore || (noCache && securityInfo));
Change that to
return ((noStore || noCache) && securityInfo);
and Back/Forward will get instantly faster, while still preserving
security for https. (If you don't care about that security issue
and want pages to cache no matter what, just replace the whole
function with
return PR_FALSE; )
The must-validate setting is handled in a completely different
place, in nsHttpChannel.
However, for some reason, fixing nsDocShell also fixes Drupal pages
which set only must-validate. I don't quite understand why yet.
More study required.
(End geekage.)
Any Mozilla folks are welcome to tell me why I shouldn't be doing
this, or if there's a better way (especially if it's possible in a
way that would work from an extension or preference).
I'd also be interested in from Drupal or other CMS folks defending why
so many CMSes destroy the user experience like this. But please first
read the Opera article referenced above, so that you understand why I
and so many other users have complained about it. I'm happy to share
any comments I receive (let me know if you want your comments to
be public or not).
Tags: tech, web, mozilla, firefox, performance
[
20:32 Oct 20, 2007
More tech/web |
permalink to this entry |
]
Wed, 04 Jul 2007
I like buying from Amazon, but it's gotten a lot more difficult since
they changed their web page design to assume super-wide browser
windows. On the browser sizes I tend to use, even if I scroll right
I can't read the reviews of books, because the content itself is wider
than my browser window. Really, what's up with the current craze of
insisting that everyone upgrade their screen sizes then run browser
windows maximized?
(I'd give a lot for a browser that had the concept of "just show me
the page in the space I have". Opera has made some progress on this
and if they got it really working it might even entice me away from
Firefox, despite my preference for open source and my investment in
Mozilla technology ... but so far it isn't better enough to justify a
switch.)
I keep meaning to try the
greasemonkey extension,
but still haven't gotten around to it.
Today, I had a little time, so I googled to see if
anyone had already written a greasemonkey script to make Amazon readable.
I couldn't find one, but I did find a
page
from last October trying to fix a similar problem on another
website, which mentioned difficulties in keeping scripts working
under greasemonkey, and offered a Javascript bookmarklet with
similar functionality.
Now we're talking! A bookmarklet sounds a lot simpler and more secure
than learning how to program Greasemonkey. So I grabbed the
bookmarklet, a copy of an Amazon page, and my trusty DOM Inspector
window and set about figuring out how to make Amazon fit in my window.
It didn't take long to realize that what I needed was CSS, not
Javascript. Which is potentially a lot easier: "all" I needed to do
was find the right CSS rules to put in userContent.css. "All" is in
quotes because getting CSS to do anything is seldom a trivial task.
But after way too much fiddling, I did finally come up with a rule
to get Amazon's Editorial Reviews to fit. Put this in
chrome/userContent.css inside your Firefox profile directory
(if you don't know where your profile directory is, search your disk
for a file called prefs.js):
div#productDescription div.content { max-width: 90% !important; }
You can replace that 90% with a pixel measurement, like 770px,
or with a different percentage.
I spent quite a long time trying to get the user reviews (a table with
two columns) to fit as well, without success. I was trying things like:
#customerReviews > div.content > table > tbody > tr > td { max-width: 300px; min-width: 10px !important; }
div#customerReviews > div.content > table { margin-right: 110px !important; }
but nothing worked, and some of it (like the latter of those two
lines) actually interfered with the div.content rule for reasons
I still don't understand. (If any of you CSS gurus want to enlighten
me, or suggest a better or more complete solution, or solutions that
work with other web pages, I'm all ears!)
I'll try for a more complete solution some other time, but for now,
I'm spending my July 4th celebrating my independance from Amazon's
idea of the one true browser width.
Tags: tech, web, css, mozilla, firefox
[
21:01 Jul 04, 2007
More tech/web |
permalink to this entry |
]
Sat, 30 Jun 2007
Today's topics are three: the excellent comic called xkcd,
the use of google to search a site but exclude parts of that site,
and, most important, the useful Mozilla technique called Bookmarklets.
I found myself wanting to show someone a particular xkcd comic
(the one about dreams).
Xkcd, for anyone who hasn't been introduced, is a wonderfully
geeky, smart, and thoughtful comic strip drawn by Randall
Munroe.
How to search for a comic strip? Xkcd has an archive page but that
seems to have a fairly small subset of all the comics. But fortunately
the comics also have titles and alt tags, which google can index.
But googling for dreams site:xkcd.org gets me lots of
hits on xkcd's forum and blag pages (which I hadn't even known
existed) rather than just finding the comic I wanted. After some
fiddling, though, I managed to find a way to exclude all the fora
and blag pages: google for
xkcd dreams site:xkcd.com -site:forums.xkcd.com -site:fora.xkcd.com -site:blag.xkcd.com
Nifty!
In fact, it was so nifty that I decided I might want to use it again.
Fortunately, Mozilla browsers like Firefox have a great feature called
bookmarklets. Bookmarklets are like shell aliases in Linux:
they let you assign an alias to a bookmark, then substitute in your
own terms each time you use it.
That's probably not clear, so here's how it works in this specific
case:
- I did the google search I listed above, which gave me this long
and seemingly scary URL:
http://www.google.com/search?hl=en&q=xkcd+dreams+site%3Axkcd.com+-site%3Aforums.xkcd.com+-site%3Afora.xkcd.com+-site%3Ablag.xkcd.com&btnG=Search
- Bookmarks->Bookmark this page. Unfortunately Firefox
doesn't let you change any bookmark properties at the time you make
the bookmark, so:
- Bookmarks->Organize Bookmarks, find the new bookmark
(down at the bottom of the list) and Edit->Properties...
- Change the Name to something useful (I called it
Xkcd search)
then choose a simple word for the Keyword field. This is the "alias"
you'll use for the bookmark. I chose xkcd.
- In the Location field, find the term you want to be
variable. In this case, that's "dreams", because I won't always be
searching for the comic about dreams, I might want to search for anything.
Change that term to %s.
(Note to non-programmers: %s is a term often used in programming
languages to mean "replace the %s with a string I'll provide
later.")
So now the Location looks like:
http://www.google.com/search?hl=en&q=xkcd+%s+site%3Axkcd.com+-site%3Aforums.xkcd.com+-site%3Afora.xkcd.com+-site%3Ablag.xkcd.com&btnG=Search
- Save the bookmarklet (click OK) and, optionally, drag it
into a folder somewhere where it won't clutter up your bookmarks menu.
You aren't ever going to be choosing this from the menu.
Now I had a new bookmarklet. To test it, I went to the urlbar in
Firefox and typed:
xkcd "regular expressions"
Voila! The first hit was exactly the comic I wanted.
(You'll find many more useful bookmarklets by
googling on
bookmarklets.)
Tags: tech, web, bookmarklets
[
22:13 Jun 30, 2007
More tech/web |
permalink to this entry |
]
Sun, 27 May 2007
For a
bit
over a year I've been running a patched version of Firefox,
which I call
Kitfox,
as my main browser. I patch it because there are a few really
important features that the old Mozilla suite had which Firefox
removed; for a long time this kept me from using Firefox
(and I'm
not
the only one who feels that way), but when the Mozilla Foundation
stopped supporting the suite and made Firefox the only supported
option, I knew my only choice was to make Firefox do what I needed.
The patches were pretty simple, but they meant that I've been building
my own Firefox all this time.
Since all my changes were in JavaScript code, not C++,
I knew this was probably all achievable with a Firefox extension.
But never around to it;
building the Mozilla source isn't that big a deal to me. I did it as
part of my job for quite a few years, and my desktop machine is fast
enough that it doesn't take that long to update and rebuild, then
copy the result to my laptop.
But when I installed the latest Debian, "Etch", on the laptop, things
got more complicated. It turns out Etch is about a year behind in
its libraries. Programs built on any other system won't run on Etch.
So I'd either have to build Mozilla on my laptop (a daunting prospect,
with builds probably in the 4-hour range) or keep another
system around for the purpose of building software for Etch.
Not worth it. It was time to learn to build an extension.
There are an amazing number of good tutorials on the web for writing
Firefox extensions (I won't even bother to link to any; just google
firefox extension and make your own choices).
They're all organized as step by step examples with sample code.
That's great (my favorite type of tutorial) but it left my real
question unanswered: what can you do in an extension?
The tutorial examples all do simple things like add a new menu or toolbar
button. None of them override existing Javascript, as I needed to do.
Canonical
URL to the rescue.
It's an extension that overrides one of the very behaviors I wanted to
override: that of adding "www." to the beginning and ".com" or ".org"
to the end of whatever's in the URLbar when you ctrl-click.
(The Mozilla suite behaved much more usefully: ctrl-click opened the
URL in a new tab, just like ctrl-clicking on a link. You never need
to add www. and .com or .org explicitly because the URL loading code
will do that for you if the initial name doesn't resolve by itself.)
Canonical URL showed me that all you need to do is make an overlay
containing your new version of the JavaScript method you want to
override. Easy!
So now I have a tiny Kitfox extension
that I can use on the laptop or anywhere else. Whee!
Since extensions are kind of a pain to unpack,
I also made a source tarball which includes a simple Makefile:
kitfox-0.1.tar.gz.
Tags: tech, web, mozilla, firefox, programming
[
11:59 May 27, 2007
More tech/web |
permalink to this entry |
]
Sun, 13 May 2007
In the last installment,
I got the Visor driver working. My sitescooper process also requires
that I have a local web server (long story), so I needed Apache. It
was already there and running (curiously, Apache 1.3.34, not Apache 2),
and it was no problem to point the DocumentRoot to the right place.
But when I tested my local site,
I discovered that although I could see the text on my website, I
couldn't see any of the images. Furthermore, if I right-clicked on any
of those images and tried "View image", the link was pointing to the
right place (http://localhost/images/foo.jpg). The file
(/path/to/mysite/images/foo.jpg) existed with all the right
permissions. What was going on?
/var/log/apache/error.log gave me the clue. When I was trying to
view http://localhost/images/foo.jpg, apache was throwing this error:
[error] [client 127.0.0.1] File does not exist: /usr/share/images/foo.jpg
/usr/share/images? Huh?
Searching for usr/share/images in /etc/apache/httpd.conf gave the
answer. It turns out that Ubuntu, in their infinite wisdom, has
decided that no one would ever want a directory called images
in their webspace. Instead, they set up an alias so that any
reference to /images gets redirected to /usr/share/images.
WTF?
Anyway, the solution is to comment out that stanza of httpd.conf:
<IfModule mod_alias.c>
# Alias /icons/ /usr/share/apache/icons/
#
# <Directory /usr/share/apache/icons>
# Options Indexes MultiViews
# AllowOverride None
# Order allow,deny
# Allow from all
# </Directory>
#
# Alias /images/ /usr/share/images/
#
# <Directory /usr/share/images>
# Options MultiViews
# AllowOverride None
# Order allow,deny
# Allow from all
# </Directory>
</IfModule>
I suppose it's nice that they provided an example for how to use
mod_alias. But at the cost of breaking any site that has directories
named /images or /icons? Is it just me, or is that a bit crazy?
Tags: linux, ubuntu, web
[
22:55 May 13, 2007
More linux |
permalink to this entry |
]
Sat, 05 May 2007
For quite some time, I've been seeing all too frequently the dialog
in Firefox which says:
A script on this page may be busy, or it may have stopped
responding. You can stop the script now, or continue to see if the
script will complete.
[Continue] [Stop script]
Googling found lots of pages offering advice on how to increase the
timeout for scripts from the default of 5 seconds to 20 or more
(change the preference dom.max_script_run_time in
about:config. But that seemed wrong. I was seeing the
dialog on lots of pages where other people didn't see it, even
on my desktop machine, which, while it isn't the absolute latest
and greatest in supercomputing, still is plenty fast for basic
web tasks.
The kicker came when I found the latest page that triggers this
dialog: Firefox' own cache viewer. Go to about:cache and
click on "List Cache Entries" under Disk cache device.
After six or seven seconds I got an Unresponsive script dialog
every time. So obviously this wasn't a problem with the web sites
I was visiting.
Someone on #mozillazine pointed me to Mozillazine's page
discussing this dialog, but it's not very useful. For instance,
it includes advice like
To determine what script is running too long, open the Error Console
and tell it to stop the script. The Error Console should identify
the script causing the problem.
Error console? What's that? I have a JavaScript Console, but it
doesn't offer any way to stop scripts. No one on #mozillazine
seemed to have any idea where I might find this elusive Error
console either.
Later Update: turns out this is new with Firefox 2.0.
I've edited the Mozillazine page to say so. Funny that no one on
IRC knew about it.
But there's a long and interesting
MozillaZine discussion of the problem
in which it's clear that it's often caused by extensions
(which the Mozillazine page had also suggested).
I checked the suggested list of Problematic
extensions, but I didn't see anything that looked likely.
So I backed up my Firefox profile and set to work, disabling my
extensions one at a time. First was Adblock, since it appeared
in the Problematic list, but removing it didn't help: I still got
the Unresponsive script when viewing my cache.
The next try was Media Player Connectivity. Bingo! No more
Unresponsive dialog. That was easy.
Media Player Connectivity never worked right for me anyway.
It's supposed to help with pages that offer videos not as a simple
video link, like movie.mpeg or movie.mov or whatever,
but as an embedded object in the page which insists on a
specific browser plug-in
(like Apples's QuickTime or Microsoft's Windows Media Player).
Playing these videos in Firefox is a huge pain in the keister -- you
have to View Source and crawl through the HTML trying to find the URL
for the actual video. Media Player Connectivity is supposed to help
by doing the crawl for you and presenting you with video links
for any embedded video it finds. But it typically doesn't find
anything, and its user interface is so inconsistent and complicated
that it's hard to figure out what it's telling you. It also can't
follow the playlists and .SMIL files that so many sites use now.
So I end up having to crawl through HTML source anyway.
Too bad! Maybe some day someone will find a way to make it easier
to view video on Linux Firefox. But at least I seem to have gotten
rid of those Unresponsive Script errors. That should make for nicer
browsing!
Tags: tech, web, mozilla, firefox
[
13:07 May 05, 2007
More tech/web |
permalink to this entry |
]
Sat, 24 Mar 2007
Every time I do a system upgrade on my desktop machine,
I end up with a web server that can't do PHP or CGI,
and I have to figure out all over again how to enable all the
important stuff. It's all buried in various nonobvious places.
Following Cory Doctorow's
"My
blog, my outboard brain" philosophy,
I shall record here the steps I needed this time, so next time I can
just look them up:
-
Install apache2.
-
Install an appropriate mod-php package (or, alternately, a full fledged
PHP package).
-
Edit /etc/apache2/sites-enabled/000-default, find the stanza
corresponding to the default site, and change AllowOverride
from None to something more permissive. This controls what's
allowed through .htaccess files. For testing, use All;
for a real environment you'll probably want something
more fine grained than that.
-
While you're there, look for the Options line in the same stanza
and add +ExecCGI to the end.
-
Edit /etc/apache2/apache2.conf and search for PHP. No, not
the line that already includes index.php; keep going to the lines
that look something like
#AddType application/x-httpd-php .php
#AddType application/x-httpd-php-source .phps
Uncomment these. Now PHP should work. The next step is to enable CGI.
-
Still in /etc/apache2/apache2.conf, search for CGI.
Eventually you'll get to
# To use CGI scripts outside /cgi-bin/:
#
#AddHandler cgi-script .cgi
Uncomment the AddHandler line.
- Finally, disable automatic start of apache at boot time (I don't
need a web server running on my workstation every day, only on days
when I'm actually doing web development). I think some upcoming Ubuntu
release may offer a way to do that through Upstart, but for now, I
mv /etc/init.d/apache /etc/noinit.d
(having previously created /etc/noinit.d for that purpose).
Tags: tech, web, apache
[
18:54 Mar 24, 2007
More tech/web |
permalink to this entry |
]
Tue, 24 Oct 2006
I get tons of phishing scam emails spoofing Amazon. You know, the
ones that say "Your Amazon account may have been compromised: please
click here to log in and verify your identity", and if you look at the
link, it goes to
http://123.45.67.8/morestuff instead of
http://www.amazon.com/morestuff. I get lots of similar phishing
emails spoofing ebay and various banks.
But yesterday's was different. The URL was this:
http://www.amazon.com/gp/amabot/?pf_rd_url=http://211.75.237.149/%20%20/amazon/xec.php?cmd=sign-in
Check it out: they're actually using amazon.com, and Amazon has a 'bot
called amabot that redirects you to somewhere else. Try this, for
example:
http://www.amazon.com/gp/amabot/?pf_rd_url=http://bn.com
-- you start on Amazon's site and end up at Barnes & Noble.
When a family member got tricked by a phish email a few months ago
(fortunately she became suspicious and stopped before revealing
anything important)
I gave her a quick lesson in how URLs work and how to recognize the
host part. "If the host part isn't what you think it should be,
it's probably a scam," I told her. That's pretty much the same as what
Amazon says (#6 on their "Identifying Phishing or Spoofed E-mails"
page). I guess now I need to teach her how to notice
that there's another URL embedded in the original one, even when the
original one goes to the right place. That's a bit more advanced.
I suspect a lot of anti-phishing software uses the same technique and
wouldn't have flagged this URL.
I reported the phish to Amazon (so far, just an automated reply, but
it hasn't been very long). I hope they look into this use of their
amabot and consider whether such a major phishing target really needs
a 'bot that can redirect anywhere on the net.
Tags: tech, web, security
[
11:34 Oct 24, 2006
More tech/web |
permalink to this entry |
]
Mon, 04 Sep 2006
I've been updating some web pages with tricky JavaScript and CSS,
and testing to see if they work in IE (which they never do) is
a hassle involving a lot of pestering of long suffering friends.
I've always heard people talk about how difficult it is to get
IE working on Linux under WINE. It works in
Crossover Office
(which is a good excuse to get Crossover: the company, Codeweavers,
is a good open source citizen and has contributed lots of work
to WINE, and I've bought from them in the past) but most people
who try installing IE under regular WINE seem to have problems.
Today someone pointed me to
IEs 4
Linux. It's a script that downloads IE and installs it under WINE.
You need wine and cabextract installed.
I was sure it couldn't be that simple, but it seemed easy enough to try.
It works great! Asked me a couple of questions, downloaded IE,
installed it, gave me an easy-to-run link in ~/bin, and it runs fine.
Now I can test my pages myself without pestering my friends.
Good stuff!
Tags: tech, web, linux
[
15:21 Sep 04, 2006
More tech/web |
permalink to this entry |
]
Fri, 04 Aug 2006
Every time I click on a mailto link, Firefox wants to bring up
Evolution. That's a fairly reasonable behavior (I'm sure Evolution
is configured as the default mailer somewhere on my system even
though I've never used it) but it's not what I want, since I
have mutt running through a remote connection to another machine
and that's where I'd want to send mail. Dismissing the dialog is
an annoyance that I keep meaning to find a way around.
But I just learned about two excellent solutions:
First: network.protocol-handler.warn-external.mailto
Set this preference to TRUE (either by going to about:config
and searching for mailto, then doubleclicking on the line for
this preference, or by editing the config.js or user.js file
in your firefox profile) and the next time you click on a
mailto link, you'll get a confirmation dialog asking whether
you really want to launch an external mailer.
"Ew! Cancelling a dialog every time is nearly as bad as cancelling
the Evolution launch!" Never fear: this dialog has a
"Don't show me this again" checkbox, so check it and click Cancel
and Firefox will remember. From then on, clicks on mailto links
will be treated as no-ops.
"But wait! It's going to be confusing having links that do
nothing when clicked on. I'm not going to know why that
happened!"
Happily, there's a solution to that, too:
you can set up a custom user style
(in your chrome/userContent.css directory) to show a custom
icon when you mouse over any mailto link. Shiny!
Tags: tech, web, firefox, mozilla
[
21:19 Aug 04, 2006
More tech/web |
permalink to this entry |
]
Tue, 25 Apr 2006
I've long been an advocate of making
presentations
in HTML rather than using more complex presentation software such as
PowerPoint, Open Office Presenter, etc. For one thing, those
presentation apps are rather heavyweight for my poor slow laptop.
For another, you can put an HTML presentation on the web and everyone
can see it right away, without needing to download the whole
presentation and fire up extra software to see it.
The problem is that Mozilla's fullscreen mode doesn't give you an easy
way to get rid of the URL/navigation bar, so your presentations look
like you're showing web pages in a browser. That's fine for some
audiences, but in some cases it looks a bit unpolished.
In the old Mozilla suite, I solved the problem by having a separate
profile which I used only for presentations, in which I customized
my browser to show no urlbar. But having separate profiles means you
always have to specify one when you start up, and you can't quickly
switch into presentation mode from a running browser. Surely there was
a better way.
After some fruitless poking in the source, I decided to ask around
on IRC, and Derek Pomery (nemo) came up with a wonderful CSS hack to
do it. Just add one line to your chrome/userChrome.css file.
In Firefox:
#toolbar-menubar[moz-collapsed=true] + #nav-bar { display: none !important; }
In Seamonkey:
#main-menubar[moz-collapsed=true] + #nav-bar { display: none !important; }
This uses a nice CSS trick I hadn't seen before, adjacent
sibling selectors, to set the visibility of one item based on the state
of a sibling which appears earlier in the DOM tree.
(A tip for using the DOM Inspector to find out the names of
items in fullscreen mode: since the menus are no longer visible, use
Ctrl-Shift-I to bring up the DOM Inspector window.
Then File->Inspect a Window and select the main content window,
which gets you the chrome of the window, not just the content.
Then you can explore the XUL hierarchy.)
This one-line CSS hack turns either Firefox or Seamonkey
into an excellent presentation tool. If you haven't tried using
HTML for presentations, I encourage you to try it. You may find
that it has a lot of advantages over dedicated presentation
software.
Addendum: I probably should have mentioned that
View->Toolbars->Navigation Controls
turns off the toolbar if you just need it for a one-time
presentation or can't modify userChrome.css.
You have to do it before you flip to fullscreen, of course,
since the menus won't be there afterward,
and then again when you flip back.
I wasn't happy with this solution myself because of the two
extra steps required every time, particularly because the steps
are awkward since they require using the laptop's trackpad.
Tags: tech, web, firefox, speaking
[
17:59 Apr 25, 2006
More tech/web |
permalink to this entry |
]
Fri, 14 Apr 2006
I'm not very consistent about looking at the statistics on my web site.
Every now and then I think of it, and take a look at who's been
visiting, why, and with what, and it's always entertaining.
The first thing I do is take the apache log and run webalizer
on it, to give me a breakdown of some of the "top" lists.
Of course, I'm extremely interested in the user agent list:
which browsers are being used most often? As of last month, the Shallowsky
list still has MSIE 6.0 in the lead ... but it's not as big a lead
as it used to be, at 56.04%. Mozilla 5.0 (which includes all Gecko-
based browsers, as far as I know, including Mozilla, Firefox, Netscape
6 and 7, Camino, etc.) is second with 20.31%. Next are four search
engine 'bots, and then we're into the single digit percentages with
a couple of old IE versions and Opera.
AvantGo (they're still around?) is number 11 with 0.37% -- interesting.
It looks like they're grabbing the Hitchhiker's Guide to the Moon;
then there are a bunch of lines like:
sync37.avantgo.com - - [05/Apr/2006:14:29:25 -0700] "GET / HTTP/1.0" 200 4549 "http://www.nineplanets.org/" "Mozilla/4.0 (compatible; AvantGo 6.0; FreeBSD)"
and I'm not sure how to read that (nineplanets.org is
The Nine Planets, Bill Arnett's
excellent and justifiably popular planetary site, and he and I have
cross-links, but I'm not sure what that has to do with avantgo and my
site). Not that it's a problem: of course, anyone is welcome to read
my site on a PDA, via AvantGo or otherwise. I'm just curious.
Amusingly, the last user agent in the top fifteen is GIMP Layers, syndicating this blog.
Another interesting list is the search queries: what search terms did
people use which led them to my site? Sometimes that's more
interesting than other times: around Christmas, people were searching
for "griffith park light show" and ending up at my lame collection of
photos from a previous year's light show. I felt so sorry for them:
Griffith Park never puts any information on the web so it's impossible
to find out what hours and dates the light show will be open, so I
know perfectly well why they were googling, and they certainly weren't
getting any help from me. I would have put the information there if
I'd known -- but I tried to find out and couldn't find it either.
But this month, no one is searching on anything unusual. The top
searches leading to my site for the past two months are terms like
birds, gimp plugins, linux powerpoint, mini laptops, debian chkconfig,
san andreas fault, pandora, hummingbird pictures, fiat x1/9,
jupiter's features, linux photo,
and a rather large assortment of dirt bike queries. (I have very
little dirt bike content on my site, but people must be desperate to
find web pages on dirt bikes because those always show up very
prominently in the search string list.)
Most popular pages are this blog (maybe just because of RSS readers),
the Hitchhiker's Guide to the Moon, and bird photos, with an
assortment of other pages covering software, linux tips, assorted
photo collections, and, of course, dirt bikes.
That's most of what I can get from webalizer. Now it's time to look at
the apache error logs. I have quite a few 404s (missing files).
I can clean up some of the obvious ones, and others are coming from
external sites I can't do anything about that for some reason link
to filenames I deleted seven years ago; but how can I get a list of
all the broken internal links on my site, so at least I can fix
the errors that are my own fault?
Kathryn on Linuxchix pointed me to dead-links.com, a rather cool
site. But it turns out it only looks for broken external
links, not internal ones. That's useful, too, just not what I
was after this time.
Warning: if you try to save the page from firefox, it will
start running all over again. You have to copy the content and paste
it into a file if you want to save it.
But Kathryn and Val opined that wget was probably the way to go
for finding internal links. Turns out wget has an option to delete
each file after downloading it, so you can wget a whole site but not
actually need to use the local space to duplicate the site.
Use this command:
wget --recursive -nd -nv --delete-after --domains=domain.com http://domain.com/ | tee wget.out 2>&1
Now open the resulting file in an editor and search repeatedly for
ERROR to find all the broken links. Unfortunately the errors are on
a separate line from the filenames they reference,
so you can't just use a grep. wget also
gets some things wrong: for instance, it tries to download the .class
file of a Java applet inside a .jar, then reports an error when the
class doesn't exist. (--reject .class might help that.)
Still, it's not hard to skip past these errors,
and wget does seem to be a fairly good way of finding broken internal links.
There's one more check left to do in the access log.
But that's a longer story, and a posting for another day.
Tags: tech, web
[
21:43 Apr 14, 2006
More tech/web |
permalink to this entry |
]
Mon, 10 Oct 2005
Ever want to look for something in your browser cache, but when you
go there, it's just a mass of oddly named files and you can't figure
out how to find anything?
(Sure, for whole pages you can use the History window, but what if
you just want to find an image you saw this morning
that isn't there any more?)
Here's a handy trick.
First, change directory to your cache directory (e.g.
$HOME/.mozilla/firefox/blahblah/Cache).
Next, list the files of the type you're looking for, in the order in
which they were last modified, and save that list to a file. Like this:
% file `ls -1t` | grep JPEG | sed 's/: .*//' > /tmp/foo
In English:
ls -t lists in order of modification date, and -1 ensures
that the files will be listed one per line. Pass that through
grep for the right pattern (do a file * to see what sorts of
patterns get spit out), then pass that through sed to get rid of
everything but the filename. Save the result to a temporary file.
The temp file now contains the list of cache files of the type you
want, ordered with the most recent first. You can now search through
them to find what you want. For example, I viewed them with Pho:
pho `cat /tmp/foo`
For images, use whatever image viewer you normally use; if you're
looking for text, you can use grep or whatever search you lke.
Alternately, you could
ls -lt `cat foo` to see what was
modified when and cut down your search a bit further, or any
other additional paring you need.
Of course, you don't have to use the temp file at all. I could
have said simply:
pho `ls -1t` | grep JPEG | sed 's/: .*//'`
Making the temp file is merely for your convenience if you think you
might need to do several types of searches before you find what
you're looking for.
Tags: tech, web, mozilla, firefox, pipelines, CLI, shell, regexp
[
22:40 Oct 10, 2005
More tech/web |
permalink to this entry |
]
Tue, 04 Oct 2005
Mozilla Firefox's model has always been to dumb down the basic
app to keep it simple, and require everything else to be implemented as
separately-installed extensions.
There's a lot to be said for this model, but aside from security
(the need to download extensions of questionable parentage from unfamiliar
sites) there's another significant down side: every time you upgrade your
browser, all your extensions become disabled, and it may be months
before they're updated to support the new Firefox version (if indeed
they're ever updated).
When you need extensions for basic functionality, like controlling
cookies, or basic sanity, like blocking flash, the intervening
months of partial functionality can be painful, especially when
there's no reason for it (the plug-in API usually hasn't changed,
merely the version string).
It turns out it's very easy to tweak your installed plug-ins
to run under your current Firefox version.
- Locate your profile directory (e.g. $HOME/firefox/blah.blah
for Firefox on Linux).
- Edit profiledirectory/extensions/*/install.rdf
- Search for maxVersion.
- Update it to your current version (as shown in the
Tools->Extensions dialog).
- Restart the browser.
Disclaimer: Obviously, if the Firefox API really has changed
in a way that makes it incompatible with your installed extensions,
this won't be enough. Your extensions may fail to work, crash your
browser, delete all your files, or cause a massive meteorite to
strike the earth causing global extinction. Consider this a
temporary solution; do check periodically to see if there's a real
extension update available.
More
information on extension versioning (may be out of date).
Tags: tech, web, mozilla, firefox
[
19:47 Oct 04, 2005
More tech/web |
permalink to this entry |
]
Sun, 11 Sep 2005
In the wake of the Hurricane Katrina devastation, one of FEMA's many
egregious mistakes is that their web site requires IE 6 in order for
victims to register for relief.
It's mostly academic. The Katrina victims who need help the
most didn't own computers, have net access, or, in many cases, even
know how to use the web. Even if they owned computers, those
computers are probably underwater and their ISP isn't up.
Nevertheless, some evacuees, staying with friends or relatives,
or using library or other public access computers, may need to
register for help using FEMA's web site.
It turns out that it's surprisingly difficult to google for the
answer to the seemingly simple question, "How do I make my browser
spoof IE6?" Here's the simple answer.
Opera: offers a menu to do this, and always has.
Mozilla or Firefox: the easiest way is to install the
User
Agent Switcher extension. Install it, restart the browser and
you get a user-agent switching menu which includes an IE6 option.
To change the user agent on Mozilla-based browsers without the
extension:
- type about:config into your urlbar
- Right-click in the window (on Mac I think that's
cmd-click to get a context menu?) and select New->String
- Use general.useragent.override for the preference name,
and Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1) for the value.
I think this takes effect immediately, no need to restart the
browser.
Safari (thanks to
Rick
Moen on svlug:
- Exit Safari. Open Terminal.
- Type defaults write com.apple.Safari IncludeDebugMenu
-boolean true
- Restart Safari.
Safari's menu bar will now include
Debug, which has an option
to change the user agent.
If you do change your user agent, please change it back after
you've finished whatever business required it. Otherwise, web site
administrators will think you're another IE user, and they they'll
use that as justification for making more ridiculous IE-only pages
like FEMA's. The more visits they see from non IE browsers, the more
they'll realize that not everyone uses IE.
Tags: tech, web
[
13:35 Sep 11, 2005
More tech/web |
permalink to this entry |
]
Mon, 27 Jun 2005
I spent a little time this afternoon chasing down a couple of recent
Firefox regressions that have been annoying me.
First, the business where, if you type a url into the urlbar and hit
alt-Enter (ctrl-Enter in my Kitfox variant) to open a new tab,
if you go back to the old tab you still see the new url in the
urlbar, which doesn't match the page being displayed there.
That turns out to be bug
227826, which was fixed a week and a half ago. Hooray!
Reading that bug yielded a nice Mozilla tip I hadn't previously
known: hitting ESC when focus is in the urlbar will revert the
urlbar to what it should be, without needing to Reload.
The other annoyance I wanted to chase down is the new failure of
firefox -remote to handle URLs with commas in them (as so
many news stories have these days); quoting the url is no help,
because it no longer handles quotes either. That means that trying
to call a browser from another program such as an IRC client is
doomed to fail for any complex url.
That turns out to be a side effect of the check-in for bug
280725, which had something to do with handling non-ASCII
URLs on Windows. I've filed bug
298960 to cover the regression.
That leaves only one (much more minor) annoyance: the way the
selection color has changed, and quite often seems to give me white
text on a dingy mustard yellow background. I think that's because of
bug
56314, which apparently makes it choose a background color
that's the reverse of the page's background, but which then doesn't
seem to choose a contrasting foreground color.
It turns out you can override this if you don't mind specifying a
single fixed set of selection colors (instead of having them change
with the colors of every page). In userChrome.css (for the urlbar)
and userContent.css (for page content):
::-moz-selection {
background-color: magenta;
color: white;
}
(obviously, pick any pair of colors which strikes your fancy).
Tags: tech, web, mozilla, firefox
[
21:45 Jun 27, 2005
More tech/web |
permalink to this entry |
]
Tue, 08 Feb 2005
Turns out the
Novell
Ad requires flash 7, and just runs partially (but with no errors
explaining the problem) with flash 6. About 2/3 of the linux users
I polled on #linuxchix had the same problem as I did (still on flash 6).
I installed flash 7.0r25, and now I get video and sound (albeit with
the usual flash "way out of sync" problem), but mozilla 1.8a6 crashes
when leaving the page (I filed a talkback report).
Still not a great face to show migrating customers.
Oh, well, maybe it works better on Novell Linux ...
Tags: linux, marketing, web
[
18:33 Feb 08, 2005
More linux |
permalink to this entry |
]
Someone on IRC posted a link to a
Novell
ad trying to persuade people to migrate from Windows to Linux.
It's flash, so I saw the flash click-to-view button. I clicked it,
and something downloaded and showed play controls (a percent-done slider
and a pause button). The controls respond, but no video ever appears.
Thinking maybe it was a problem with click-to-view, I tried it in my
debug profile, with mostly default settings. No dice: even without
click-to-view, the page just plain doesn't work in Linux Mozilla.
Didn't work in Firefox either (though I don't have a Firefox profile
without click-to-view, admittedly). People on Windows and Mac
report that it works on those platforms.
I thought to myself, Novell is trying to be pro-Linux, they'll
probably want to know about this. So I went up one level to try to
find a contact address (there isn't one on the migration page).
I didn't find any email addresses but I did find a feedback link,
so I clicked it. It popped up an empty window, which sat empty
for a minute or two, then filled with "Novell Account:
Mal-formed reply from origin s". Any text which might follow
that is cut off, doesn't fit in the window size they specified.
What does Novell expect customers to think when they migrate
one machine to Linux, start using it to surf the web, and
discover that they can't even read Novell's own pro-Linux pages
from Linux? What sort of impression is that going to make on
someone considering migrating a whole shop?
Fortunately sites like Novell's which don't work in Linux and
Mozilla are the exception, not the rule. I can surf most
of the web just fine; it's only a few bad apples who can't manage
to write cross-platform web pages. But someone early in the
migration process doesn't know that. They're more likely to just
stop right there.
Tags: linux, marketing, web
[
12:30 Feb 08, 2005
More linux |
permalink to this entry |
]
Mon, 17 Jan 2005
Investigating some of the disappointing recent regressions in
Mozilla (in particular in handling links that would open new windows,
bug 278429),
I stumbled upon this useful little tidbit from manko, in the old
bug
78037:
You can use CSS to make your browser give different highlighting
for links that would open in a different window.
Put something like this in your
[moz_profile_dir]/chrome/userContent.css:
a[target="_blank"] {
-moz-outline: 1px dashed invert !important;
/* links to open in new window */
}
a:hover[target="_blank"] {
cursor: crosshair; text-decoration: blink;
color: red; background-color: yellow
!important
}
a[href^="http://"] {
-moz-outline: 1px dashed #FFCC00 !important;
/* links outside from current site */
}
a[href^="http://"][target="_blank"] {
-moz-outline: 1px dashed #FF0000 !important;
/* combination */
}
I questioned the use of outlines rather than colors, but then
realized why manko uses outlines instead: it's better to preserve
the existing colors used by each page, so that link colors go along
with the page's background color.
I tried adding a text-decoration: blink; to the a:hover
style, but it didn't work.
I don't know whether mozilla ignores blink, or if it's being
overridden by the line I already had in userContent.css,
blink { text-decoration: none ! important; }
though I doubt that, since that should apply to the blink tag,
not blink styles on other tags.
In any case, the crosshair cursor should make new-window links
sufficiently obvious, and I expect the blinking (even only on hover)
would have gotten on my nerves before long.
Incidentally, for any web designers reading this (and who isn't,
these days?), links that try to open new browser windows are a
longstanding item on usability guru Jakob Neilsen's Top Ten Mistakes in
Web Design, and he has a good explanation why.
I'm clearly not the only one who hates them.
For a few other mozilla hacks, see
my current userChrome.css
and userContent.css.
Tags: tech, web, mozilla, firefox
[
14:03 Jan 17, 2005
More tech/web |
permalink to this entry |
]
Thu, 13 Jan 2005
For years I've been plagued by having web pages occasionally display
in a really ugly font that looks like some kind of ancient OCR font
blockily scaled up from a bitmap font.
For instance, look at West Valley College
page, or this news page.
I finally discovered today that pages look like this because Mozilla
thinks they're in Cyrillic! In the case of West Valley, their
server is saying in the http headers:
Content-Type: text/html; charset=WINDOWS-1251
-- WINDOWS-1251 is Cyrillic --
but the page itself specifies a Western character set:
<META http-equiv=Content-Type content="text/html; charset=iso-8859-1">
On my system, Mozilla believes the server instead of the page,
and chooses a Cyrillic font to display the page in. Unfortunately,
the Cyrillic font it chooses is extremely bad -- I have good ones
installed, and I can't figure out where this bad one is coming from,
or I'd terminate it with extreme prejudice. It's not even readable
for pages that really are Cyrillic.
The easy solution for a single page is to use Mozilla's View menu:
View->Character Encoding->Western (ISO-8851-1).
Unfortunately, that has to be done again for each new link
I click on the site; there seems to be no way to say "Ignore
this server's bogus charset claims".
The harder way: I sent mail to the contact address on the server
page, and filed bug
278326 on Mozilla's ignoring the page's meta tag (which you'd
think would override the server's default), but it was closed with
the claim that the standard requires that Mozilla give precedence
to the server. (I wonder what IE does?)
At least that finally inspired me to install Mozilla 1.8a6, which
I'd downloaded a few days ago but hadn't installed yet, to verify
that it saw the same charset. It did, but almost immediately I hit
a worse bug: now mozilla -remote always opens a new window,
even if new-tab or no directive at all is specified.
The release notes have nothing matching "remote, but
someone had already filed bug
276808.
Tags: tech, web, fonts, linux
[
20:15 Jan 13, 2005
More tech/web |
permalink to this entry |
]
Sat, 07 Aug 2004
The Mozilla Dev Conference yesterday went well. Shaver and Brendan
showed off a new implementation they'd hacked up with Stuart allowing
drawing into a graphics area from JavaScript, modelled after Apple's
Canvas API. The API looked pretty simple from the code snippet they
showed briefly, with commands for line, polygon, fill, and so forth.
It also included full transparency support.
This is all implemented in terms of Cairo.
Someone asked how this compared to SVG. The answer was to think of
Canvas as an image you can change from JS -- simpler than an SVG
document.
Brendan was funny, playing Vanna as Shaver did the brunt of the
talking. "Ooh, that's pretty. What's that?"
Roc then gave a talk on "New Rendering Features for Gecko".
Probably what attracted the most interest there was transparency:
he has a new hack (not yet checked in) where you can add a parameter
to a XUL window to make it transparent. X only supports 1-bit
transparency, but in Windows implementation XUL windows can be
fully transparent.
He began his talk talking about Cairo and about the changed hardware
expectations these days. He stated that everyone has 3D now, or at
least, anyone who doesn't, doesn't care about rendering and doesn't
expect much. I found that rather disturbing, given that I sure
don't want to see rendering stop working well on my laptop, and
I'd hate to see Mozilla ignore education, developing countries and
other markets where open source on cheap hardware is starting to
gain a strong foothold.
The other bothersome thing Roc talked about was high-res displays.
He mentioned people at IBM and other places using 200dpi displays,
which (as anyone who's used even 100dpi and has imperfect vision
knows) leads to tiny text and other display problems on a lot of
pages due to the ubiquity of page designers who use pixel-based
sizing. Roc's answer to this was to have an automatic x2 or x3
zoom for people at high resolutions like 200dpi. This seems to
me a very poor solution: text will either be too big or too small,
and images will be scaled weirdly. Perhaps if it's implemented as
a smart font size scaling, without any mandatory image scaling, it
could be helpful. I wish more work were going into Mozilla's text
scaling, rather than things like automatic 2x zooms. Maybe this
will be part of the work. Guess I need to seek out the bugs and get
involved before I worry too much about right or wrong solutions.
Then AaronL gave his accessibility talk, stressing that
"accessibility helps everybody" and that the minimum everyone should
do is check pages and new XUL objects for keyboard accessibility.
He talked a bit about how screen reading software works, with a demo,
color-blindness issues (don't ever use color as the only cue), and
accessibility problems with the current fad of implementing fake
menus using JS and DHTML (such menus are almost never accessible to
screen reading software, and often can't be triggered with keyboard
events either). Hopefully awareness of these issues will increase
as legislation mandates better accessibility. Aaron's talk was
unfortunately cut short because he was scheduled as the last talk
before lunch; people seemed interested and there was a lot of
information on his slides which got skipped due to time constraints.
After lunch, Nigel spoke on writing XUL applications, Bob Clary
presented an automated site testing tool he'd written (which runs
in Mozilla) to validate HTML, CSS and JS, roc spoke again on the
question of how backwards compatible and quirk-compatible Mozilla
should be, Myk presented his RSS reading addition to Thunderbird
mail, Pav gave a longer demo of the Cairo Canvas, and several
other demos were presented.
Tags: tech, web, mozilla
[
11:30 Aug 07, 2004
More tech/web |
permalink to this entry |
]
![[Firefox bookmarks dialog]](http://shallowsky.com/blog/images/screenshots/bookmark-dialog.jpg)
![[Google begging: Switch your default search engine to Google]](http://shallowsky.com/blog/images/screenshots/google-beg.jpg)
![[spam that the blog owner didn't see]](http://shallowsky.com/blog/images/screenshots/blogseo.jpg)
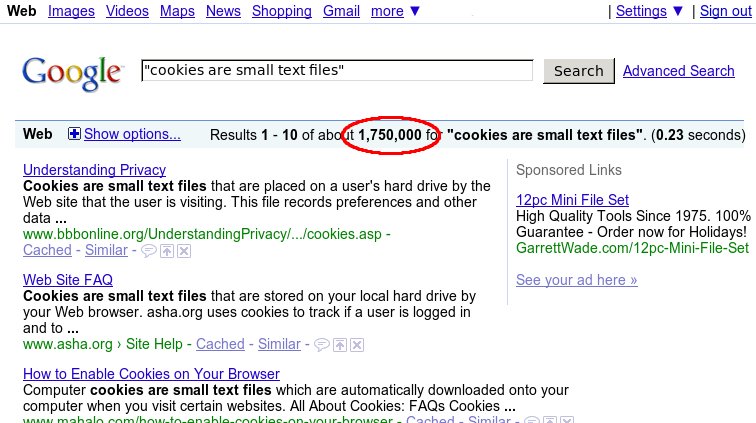
{kind=link}
{kind=link}